 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Transformer Language Models for Predictive Typing in Brain-Computer Interfaces
May 05, 2023
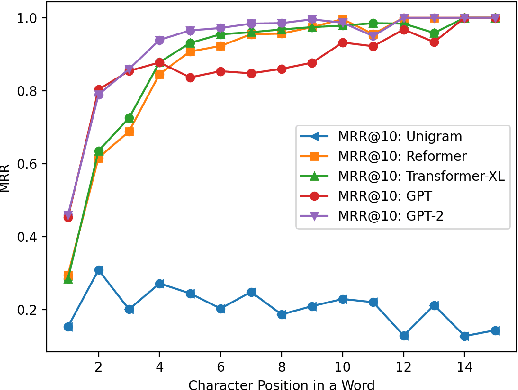

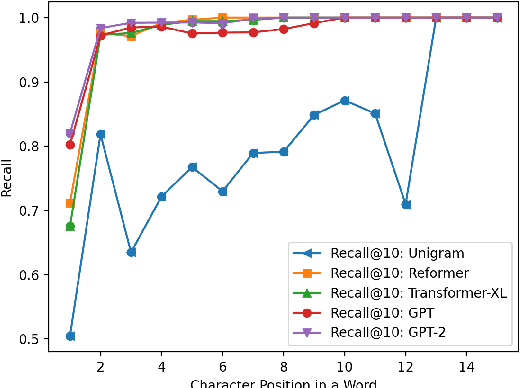
Brain-computer interfaces (BCI) are an important mode of alternative and augmentative communication for many people. Unlike keyboards, many BCI systems do not display even the 26 letters of English at one time, let alone all the symbols in more complex systems. Using language models to make character-level predictions, therefore, can greatly speed up BCI typing (Ghosh and Kristensson, 2017). While most existing BCI systems employ character n-gram models or no LM at all, this paper adapts several wordpiece-level Transformer LMs to make character predictions and evaluates them on typing tasks. GPT-2 fares best on clean text, but different LMs react differently to noisy histories. We further analyze the effect of character positions in a word and context lengths.
On the Idiosyncrasies of the Mandarin Chinese Classifier System
Apr 05, 2019

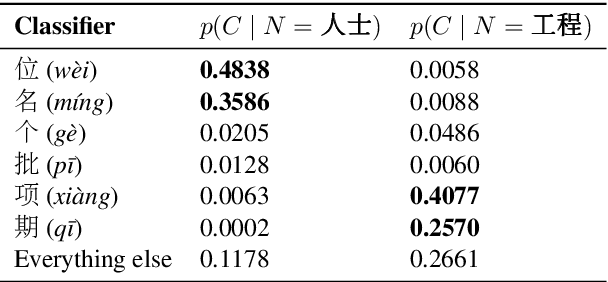
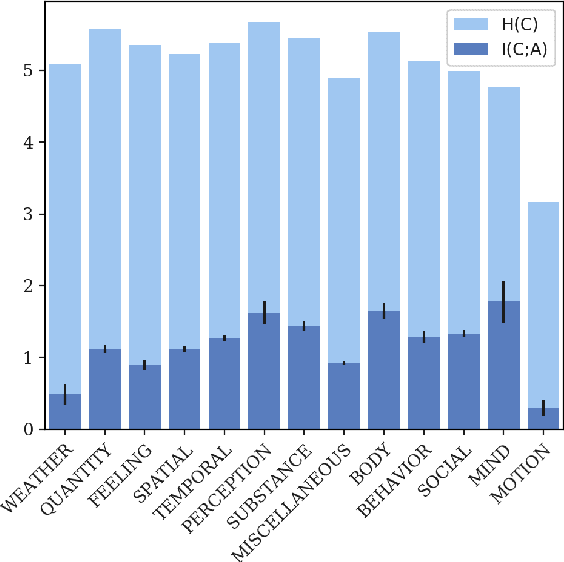
While idiosyncrasies of the Chinese classifier system have been a richly studied topic among linguists (Adams and Conklin, 1973; Erbaugh, 1986; Lakoff, 1986), not much work has been done to quantify them with statistical methods. In this paper, we introduce an information-theoretic approach to measuring idiosyncrasy; we examine how much the uncertainty in Mandarin Chinese classifiers can be reduced by knowing semantic information about the nouns that the classifiers modify. Using the empirical distribution of classifiers from the parsed Chinese Gigaword corpus (Graff et al., 2005), we compute the mutual information (in bits) between the distribution over classifiers and distributions over other linguistic quantities. We investigate whether semantic classes of nouns and adjectives differ in how much they reduce uncertainty in classifier choice, and find that it is not fully idiosyncratic; while there are no obvious trends for the majority of semantic classes, shape nouns reduce uncertainty in classifier choice the most.