 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization Dynamics in Knowledge Distillation for Language Models
Jan 21, 2026Knowledge Distillation (KD) is increasingly adopted to transfer capabilities from large language models to smaller ones, offering significant improvements in efficiency and utility while often surpassing standard fine-tuning. Beyond performance, KD is also explored as a privacy-preserving mechanism to mitigate the risk of training data leakage. While training data memorization has been extensively studied in standard pre-training and fine-tuning settings, its dynamics in a knowledge distillation setup remain poorly understood. In this work, we study memorization across the KD pipeline using three large language model (LLM) families (Pythia, OLMo-2, Qwen-3) and three datasets (FineWeb, Wikitext, Nemotron-CC-v2). We find: (1) distilled models memorize significantly less training data than standard fine-tuning (reducing memorization by more than 50%); (2) some examples are inherently easier to memorize and account for a large fraction of memorization during distillation (over ~95%); (3) student memorization is predictable prior to distillation using features based on zlib entropy, KL divergence, and perplexity; and (4) while soft and hard distillation have similar overall memorization rates, hard distillation poses a greater risk: it inherits $2.7\times$ more teacher-specific examples than soft distillation. Overall, we demonstrate that distillation can provide both improved generalization and reduced memorization risks compared to standard fine-tuning.
Privacy Ripple Effects from Adding or Removing Personal Information in Language Model Training
Feb 21, 2025Due to the sensitive nature of personally identifiable information (PII), its owners may have the authority to control its inclusion or request its removal from large-language model (LLM) training. Beyond this, PII may be added or removed from training datasets due to evolving dataset curation techniques, because they were newly scraped for retraining, or because they were included in a new downstream fine-tuning stage. We find that the amount and ease of PII memorization is a dynamic property of a model that evolves throughout training pipelines and depends on commonly altered design choices. We characterize three such novel phenomena: (1) similar-appearing PII seen later in training can elicit memorization of earlier-seen sequences in what we call assisted memorization, and this is a significant factor (in our settings, up to 1/3); (2) adding PII can increase memorization of other PII significantly (in our settings, as much as $\approx\!7.5\times$); and (3) removing PII can lead to other PII being memorized. Model creators should consider these first- and second-order privacy risks when training models to avoid the risk of new PII regurgitation.
Mind the Gap: Analyzing Lacunae with Transformer-Based Transcription
Jun 28, 2024Historical documents frequently suffer from damage and inconsistencies, including missing or illegible text resulting from issues such as holes, ink problems, and storage damage. These missing portions or gaps are referred to as lacunae. In this study, we employ transformer-based optical character recognition (OCR) models trained on synthetic data containing lacunae in a supervised manner. We demonstrate their effectiveness in detecting and restoring lacunae, achieving a success rate of 65%, compared to a base model lacking knowledge of lacunae, which achieves only 5% restoration. Additionally, we investigate the mechanistic properties of the model, such as the log probability of transcription, which can identify lacunae and other errors (e.g., mistranscriptions due to complex writing or ink issues) in line images without directly inspecting the image. This capability could be valuable for scholars seeking to distinguish images containing lacunae or errors from clean ones. Although we explore the potential of attention mechanisms in flagging lacunae and transcription errors, our findings suggest it is not a significant factor. Our work highlights a promising direction in utilizing transformer-based OCR models for restoring or analyzing damaged historical documents.
Recite, Reconstruct, Recollect: Memorization in LMs as a Multifaceted Phenomenon
Jun 25, 2024



Memorization in language models is typically treated as a homogenous phenomenon, neglecting the specifics of the memorized data. We instead model memorization as the effect of a set of complex factors that describe each sample and relate it to the model and corpus. To build intuition around these factors, we break memorization down into a taxonomy: recitation of highly duplicated sequences, reconstruction of inherently predictable sequences, and recollection of sequences that are neither. We demonstrate the usefulness of our taxonomy by using it to construct a predictive model for memorization. By analyzing dependencies and inspecting the weights of the predictive model, we find that different factors influence the likelihood of memorization differently depending on the taxonomic category.
What can we learn from Data Leakage and Unlearning for Law?
Jul 19, 2023Large Language Models (LLMs) have a privacy concern because they memorize training data (including personally identifiable information (PII) like emails and phone numbers) and leak it during inference. A company can train an LLM on its domain-customized data which can potentially also include their users' PII. In order to comply with privacy laws such as the "right to be forgotten", the data points of users that are most vulnerable to extraction could be deleted. We find that once the most vulnerable points are deleted, a new set of points become vulnerable to extraction. So far, little attention has been given to understanding memorization for fine-tuned models. In this work, we also show that not only do fine-tuned models leak their training data but they also leak the pre-training data (and PII) memorized during the pre-training phase. The property of new data points becoming vulnerable to extraction after unlearning and leakage of pre-training data through fine-tuned models can pose significant privacy and legal concerns for companies that use LLMs to offer services. We hope this work will start an interdisciplinary discussion within AI and law communities regarding the need for policies to tackle these issues.
Simple Transparent Adversarial Examples
May 20, 2021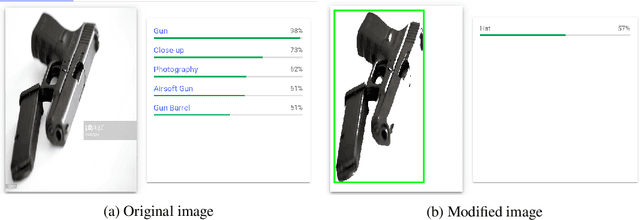


There has been a rise in the use of Machine Learning as a Service (MLaaS) Vision APIs as they offer multiple services including pre-built models and algorithms, which otherwise take a huge amount of resources if built from scratch. As these APIs get deployed for high-stakes applications, it's very important that they are robust to different manipulations. Recent works have only focused on typical adversarial attacks when evaluating the robustness of vision APIs. We propose two new aspects of adversarial image generation methods and evaluate them on the robustness of Google Cloud Vision API's optical character recognition service and object detection APIs deployed in real-world settings such as sightengine.com, picpurify.com, Google Cloud Vision API, and Microsoft Azure's Computer Vision API. Specifically, we go beyond the conventional small-noise adversarial attacks and introduce secret embedding and transparent adversarial examples as a simpler way to evaluate robustness. These methods are so straightforward that even non-specialists can craft such attacks. As a result, they pose a serious threat where APIs are used for high-stakes applications. Our transparent adversarial examples successfully evade state-of-the art object detections APIs such as Azure Cloud Vision (attack success rate 52%) and Google Cloud Vision (attack success rate 36%). 90% of the images have a secret embedded text that successfully fools the vision of time-limited humans but is detected by Google Cloud Vision API's optical character recognition. Complementing to current research, our results provide simple but unconventional methods on robustness evaluation.