 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteered LLM Activations are Non-Surjective
Apr 10, 2026Activation steering is a popular white-box control technique that modifies model activations to elicit an abstract change in output behavior. It has also become a standard tool in interpretability (e.g., probing truthfulness, or translating activations into human-readable explanations and safety research (e.g., studying jailbreakability). However, it is unclear whether steered activation states are realizable by any textual prompt. In this work, we cast this question as a surjectivity problem: for a fixed model, does every steered activation admit a pre-image under the model's natural forward pass? Under practical assumptions, we prove that activation steering pushes the residual stream off the manifold of states reachable from discrete prompts. Almost surely, no prompt can reproduce the same internal behavior induced by steering. We also illustrate this finding empirically across three widely used LLMs. Our results establish a formal separation between white-box steerability and black-box prompting. We therefore caution against interpreting the ease and success of activation steering as evidence of prompt-based interpretability or vulnerability, and argue for evaluation protocols that explicitly decouple white-box and black-box interventions.
Unsupervised Continual Learning for Amortized Bayesian Inference
Feb 26, 2026Amortized Bayesian Inference (ABI) enables efficient posterior estimation using generative neural networks trained on simulated data, but often suffers from performance degradation under model misspecification. While self-consistency (SC) training on unlabeled empirical data can enhance network robustness, current approaches are limited to static, single-task settings and fail to handle sequentially arriving data or distribution shifts. We propose a continual learning framework for ABI that decouples simulation-based pre-training from unsupervised sequential SC fine-tuning on real-world data. To address the challenge of catastrophic forgetting, we introduce two adaptation strategies: (1) SC with episodic replay, utilizing a memory buffer of past observations, and (2) SC with elastic weight consolidation, which regularizes updates to preserve task-critical parameters. Across three diverse case studies, our methods significantly mitigate forgetting and yield posterior estimates that outperform standard simulation-based training, achieving estimates closer to MCMC reference, providing a viable path for trustworthy ABI across a range of different tasks.
BayesFlow 2.0: Multi-Backend Amortized Bayesian Inference in Python
Feb 06, 2026Modern Bayesian inference involves a mixture of computational methods for estimating, validating, and drawing conclusions from probabilistic models as part of principled workflows. An overarching motif of many Bayesian methods is that they are relatively slow, which often becomes prohibitive when fitting complex models to large data sets. Amortized Bayesian inference (ABI) offers a path to solving the computational challenges of Bayes. ABI trains neural networks on model simulations, rewarding users with rapid inference of any model-implied quantity, such as point estimates, likelihoods, or full posterior distributions. In this work, we present the Python library BayesFlow, Version 2.0, for general-purpose ABI. Along with direct posterior, likelihood, and ratio estimation, the software includes support for multiple popular deep learning backends, a rich collection of generative networks for sampling and density estimation, complete customization and high-level interfaces, as well as new capabilities for hyperparameter optimization, design optimization, and hierarchical modeling. Using a case study on dynamical system parameter estimation, combined with comparisons to similar software, we show that our streamlined, user-friendly workflow has strong potential to support broad adoption.
Improving the Accuracy of Amortized Model Comparison with Self-Consistency
Dec 16, 2025



Amortized Bayesian inference (ABI) offers fast, scalable approximations to posterior densities by training neural surrogates on data simulated from the statistical model. However, ABI methods are highly sensitive to model misspecification: when observed data fall outside the training distribution (generative scope of the statistical models), neural surrogates can behave unpredictably. This makes it a challenge in a model comparison setting, where multiple statistical models are considered, of which at least some are misspecified. Recent work on self-consistency (SC) provides a promising remedy to this issue, accessible even for empirical data (without ground-truth labels). In this work, we investigate how SC can improve amortized model comparison conceptualized in four different ways. Across two synthetic and two real-world case studies, we find that approaches for model comparison that estimate marginal likelihoods through approximate parameter posteriors consistently outperform methods that directly approximate model evidence or posterior model probabilities. SC training improves robustness when the likelihood is available, even under severe model misspecification. The benefits of SC for methods without access of analytic likelihoods are more limited and inconsistent. Our results suggest practical guidance for reliable amortized Bayesian model comparison: prefer parameter posterior-based methods and augment them with SC training on empirical datasets to mitigate extrapolation bias under model misspecification.
Genomic Next-Token Predictors are In-Context Learners
Nov 16, 2025In-context learning (ICL) -- the capacity of a model to infer and apply abstract patterns from examples provided within its input -- has been extensively studied in large language models trained for next-token prediction on human text. In fact, prior work often attributes this emergent behavior to distinctive statistical properties in human language. This raises a fundamental question: can ICL arise organically in other sequence domains purely through large-scale predictive training? To explore this, we turn to genomic sequences, an alternative symbolic domain rich in statistical structure. Specifically, we study the Evo2 genomic model, trained predominantly on next-nucleotide (A/T/C/G) prediction, at a scale comparable to mid-sized LLMs. We develop a controlled experimental framework comprising symbolic reasoning tasks instantiated in both linguistic and genomic forms, enabling direct comparison of ICL across genomic and linguistic models. Our results show that genomic models, like their linguistic counterparts, exhibit log-linear gains in pattern induction as the number of in-context demonstrations increases. To the best of our knowledge, this is the first evidence of organically emergent ICL in genomic sequences, supporting the hypothesis that ICL arises as a consequence of large-scale predictive modeling over rich data. These findings extend emergent meta-learning beyond language, pointing toward a unified, modality-agnostic view of in-context learning.
IA2: Alignment with ICL Activations Improves Supervised Fine-Tuning
Sep 26, 2025Supervised Fine-Tuning (SFT) is used to specialize model behavior by training weights to produce intended target responses for queries. In contrast, In-Context Learning (ICL) adapts models during inference with instructions or demonstrations in the prompt. ICL can offer better generalizability and more calibrated responses compared to SFT in data scarce settings, at the cost of more inference compute. In this work, we ask the question: Can ICL's internal computations be used to improve the qualities of SFT? We first show that ICL and SFT produce distinct activation patterns, indicating that the two methods achieve adaptation through different functional mechanisms. Motivated by this observation and to use ICL's rich functionality, we introduce ICL Activation Alignment (IA2), a self-distillation technique which aims to replicate ICL's activation patterns in SFT models and incentivizes ICL-like internal reasoning. Performing IA2 as a priming step before SFT significantly improves the accuracy and calibration of model outputs, as shown by our extensive empirical results on 12 popular benchmarks and 2 model families. This finding is not only practically useful, but also offers a conceptual window into the inner mechanics of model adaptation.
ODD: Overlap-aware Estimation of Model Performance under Distribution Shift
Jun 17, 2025Reliable and accurate estimation of the error of an ML model in unseen test domains is an important problem for safe intelligent systems. Prior work uses disagreement discrepancy (DIS^2) to derive practical error bounds under distribution shifts. It optimizes for a maximally disagreeing classifier on the target domain to bound the error of a given source classifier. Although this approach offers a reliable and competitively accurate estimate of the target error, we identify a problem in this approach which causes the disagreement discrepancy objective to compete in the overlapping region between source and target domains. With an intuitive assumption that the target disagreement should be no more than the source disagreement in the overlapping region due to high enough support, we devise Overlap-aware Disagreement Discrepancy (ODD). Maximizing ODD only requires disagreement in the non-overlapping target domain, removing the competition. Our ODD-based bound uses domain-classifiers to estimate domain-overlap and better predicts target performance than DIS^2. We conduct experiments on a wide array of benchmarks to show that our method improves the overall performance-estimation error while remaining valid and reliable. Our code and results are available on GitHub.
ICL CIPHERS: Quantifying "Learning'' in In-Context Learning via Substitution Ciphers
Apr 28, 2025Recent works have suggested that In-Context Learning (ICL) operates in dual modes, i.e. task retrieval (remember learned patterns from pre-training) and task learning (inference-time ``learning'' from demonstrations). However, disentangling these the two modes remains a challenging goal. We introduce ICL CIPHERS, a class of task reformulations based on substitution ciphers borrowed from classic cryptography. In this approach, a subset of tokens in the in-context inputs are substituted with other (irrelevant) tokens, rendering English sentences less comprehensible to human eye. However, by design, there is a latent, fixed pattern to this substitution, making it reversible. This bijective (reversible) cipher ensures that the task remains a well-defined task in some abstract sense, despite the transformations. It is a curious question if LLMs can solve ICL CIPHERS with a BIJECTIVE mapping, which requires deciphering the latent cipher. We show that LLMs are better at solving ICL CIPHERS with BIJECTIVE mappings than the NON-BIJECTIVE (irreversible) baseline, providing a novel approach to quantify ``learning'' in ICL. While this gap is small, it is consistent across the board on four datasets and six models. Finally, we examine LLMs' internal representations and identify evidence in their ability to decode the ciphered inputs.
Automatic Machine Learning Framework to Study Morphological Parameters of AGN Host Galaxies within $z < 1.4$ in the Hyper Supreme-Cam Wide Survey
Jan 27, 2025We present a composite machine learning framework to estimate posterior probability distributions of bulge-to-total light ratio, half-light radius, and flux for Active Galactic Nucleus (AGN) host galaxies within $z<1.4$ and $m<23$ in the Hyper Supreme-Cam Wide survey. We divide the data into five redshift bins: low ($0<z<0.25$), mid ($0.25<z<0.5$), high ($0.5<z<0.9$), extra ($0.9<z<1.1$) and extreme ($1.1<z<1.4$), and train our models independently in each bin. We use PSFGAN to decompose the AGN point source light from its host galaxy, and invoke the Galaxy Morphology Posterior Estimation Network (GaMPEN) to estimate morphological parameters of the recovered host galaxy. We first trained our models on simulated data, and then fine-tuned our algorithm via transfer learning using labeled real data. To create training labels for transfer learning, we used GALFIT to fit $\sim 20,000$ real HSC galaxies in each redshift bin. We comprehensively examined that the predicted values from our final models agree well with the GALFIT values for the vast majority of cases. Our PSFGAN + GaMPEN framework runs at least three orders of magnitude faster than traditional light-profile fitting methods, and can be easily retrained for other morphological parameters or on other datasets with diverse ranges of resolutions, seeing conditions, and signal-to-noise ratios, making it an ideal tool for analyzing AGN host galaxies from large surveys coming soon from the Rubin-LSST, Euclid, and Roman telescopes.
Source-Free and Image-Only Unsupervised Domain Adaptation for Category Level Object Pose Estimation
Jan 19, 2024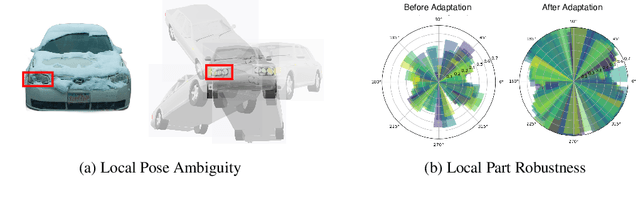
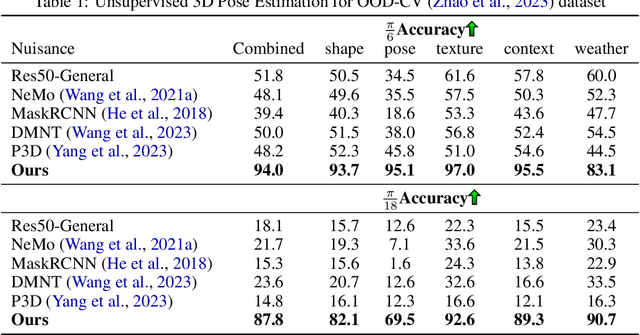
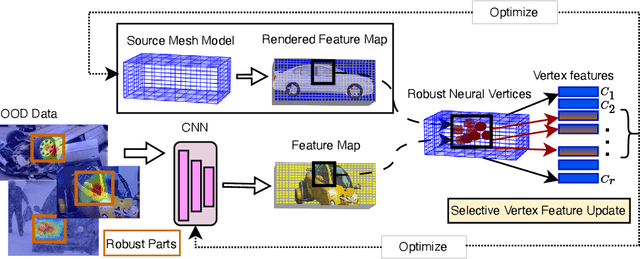
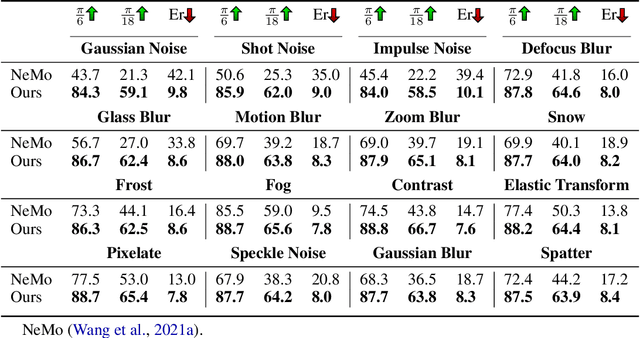
We consider the problem of source-free unsupervised category-level pose estimation from only RGB images to a target domain without any access to source domain data or 3D annotations during adaptation. Collecting and annotating real-world 3D data and corresponding images is laborious, expensive, yet unavoidable process, since even 3D pose domain adaptation methods require 3D data in the target domain. We introduce 3DUDA, a method capable of adapting to a nuisance-ridden target domain without 3D or depth data. Our key insight stems from the observation that specific object subparts remain stable across out-of-domain (OOD) scenarios, enabling strategic utilization of these invariant subcomponents for effective model updates. We represent object categories as simple cuboid meshes, and harness a generative model of neural feature activations modeled at each mesh vertex learnt using differential rendering. We focus on individual locally robust mesh vertex features and iteratively update them based on their proximity to corresponding features in the target domain even when the global pose is not correct. Our model is then trained in an EM fashion, alternating between updating the vertex features and the feature extractor. We show that our method simulates fine-tuning on a global pseudo-labeled dataset under mild assumptions, which converges to the target domain asymptotically. Through extensive empirical validation, including a complex extreme UDA setup which combines real nuisances, synthetic noise, and occlusion, we demonstrate the potency of our simple approach in addressing the domain shift challenge and significantly improving pose estimation accuracy.