 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo pretrained Transformers Really Learn In-context by Gradient Descent?
Paper and Code

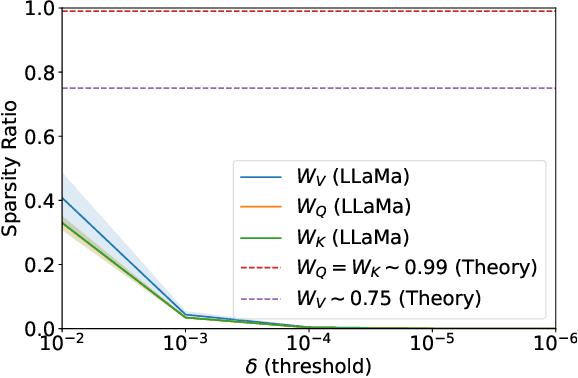


Is In-Context Learning (ICL) implicitly equivalent to Gradient Descent (GD)? Several recent works draw analogies between the dynamics of GD and the emergent behavior of ICL in large language models. However, these works make assumptions far from the realistic natural language setting in which language models are trained. Such discrepancies between theory and practice, therefore, necessitate further investigation to validate their applicability. We start by highlighting the weaknesses in prior works that construct Transformer weights to simulate gradient descent. Their experiments with training Transformers on ICL objective, inconsistencies in the order sensitivity of ICL and GD, sparsity of the constructed weights, and sensitivity to parameter changes are some examples of a mismatch from the real-world setting. Furthermore, we probe and compare the ICL vs. GD hypothesis in a natural setting. We conduct comprehensive empirical analyses on language models pretrained on natural data (LLaMa-7B). Our comparisons on various performance metrics highlight the inconsistent behavior of ICL and GD as a function of various factors such as datasets, models, and number of demonstrations. We observe that ICL and GD adapt the output distribution of language models differently. These results indicate that the equivalence between ICL and GD is an open hypothesis, requires nuanced considerations and calls for further studies.