 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECAF: Dynamic Envelope Context-Aware Fusion for Speech-Envelope Reconstruction from EEG
Feb 23, 2026Reconstructing the speech audio envelope from scalp neural recordings (EEG) is a central task for decoding a listener's attentional focus in applications like neuro-steered hearing aids. Current methods for this reconstruction, however, face challenges with fidelity and noise. Prevailing approaches treat it as a static regression problem, processing each EEG window in isolation and ignoring the rich temporal structure inherent in continuous speech. This study introduces a new, dynamic framework for envelope reconstruction that leverages this structure as a predictive temporal prior. We propose a state-space fusion model that combines direct neural estimates from EEG with predictions from recent speech context, using a learned gating mechanism to adaptively balance these cues. To validate this approach, we evaluate our model on the ICASSP 2023 Stimulus Reconstruction benchmark demonstrating significant improvements over static, EEG-only baselines. Our analyses reveal a powerful synergy between the neural and temporal information streams. Ultimately, this work reframes envelope reconstruction not as a simple mapping, but as a dynamic state-estimation problem, opening a new direction for developing more accurate and coherent neural decoding systems.
Foundation Model Hidden Representations for Heart Rate Estimation from Auscultation
May 29, 2025
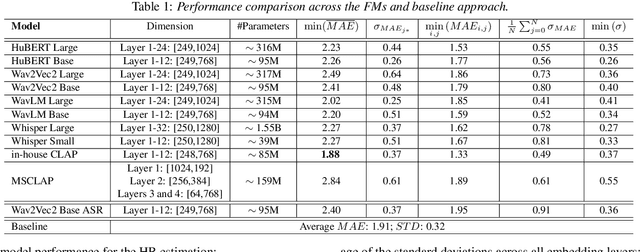
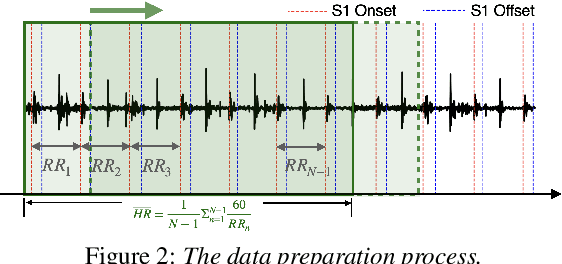
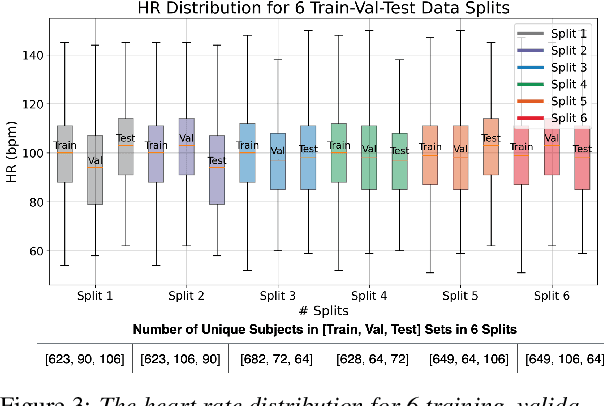
Auscultation, particularly heart sound, is a non-invasive technique that provides essential vital sign information. Recently, self-supervised acoustic representation foundation models (FMs) have been proposed to offer insights into acoustics-based vital signs. However, there has been little exploration of the extent to which auscultation is encoded in these pre-trained FM representations. In this work, using a publicly available phonocardiogram (PCG) dataset and a heart rate (HR) estimation model, we conduct a layer-wise investigation of six acoustic representation FMs: HuBERT, wav2vec2, wavLM, Whisper, Contrastive Language-Audio Pretraining (CLAP), and an in-house CLAP model. Additionally, we implement the baseline method from Nie et al., 2024 (which relies on acoustic features) and show that overall, representation vectors from pre-trained foundation models (FMs) offer comparable performance to the baseline. Notably, HR estimation using the representations from the audio encoder of the in-house CLAP model outperforms the results obtained from the baseline, achieving a lower mean absolute error (MAE) across various train/validation/test splits despite the domain mismatch.
SoloAudio: Target Sound Extraction with Language-oriented Audio Diffusion Transformer
Sep 12, 2024In this paper, we introduce SoloAudio, a novel diffusion-based generative model for target sound extraction (TSE). Our approach trains latent diffusion models on audio, replacing the previous U-Net backbone with a skip-connected Transformer that operates on latent features. SoloAudio supports both audio-oriented and language-oriented TSE by utilizing a CLAP model as the feature extractor for target sounds. Furthermore, SoloAudio leverages synthetic audio generated by state-of-the-art text-to-audio models for training, demonstrating strong generalization to out-of-domain data and unseen sound events. We evaluate this approach on the FSD Kaggle 2018 mixture dataset and real data from AudioSet, where SoloAudio achieves the state-of-the-art results on both in-domain and out-of-domain data, and exhibits impressive zero-shot and few-shot capabilities. Source code and demos are released.
DreamVoice: Text-Guided Voice Conversion
Jun 24, 2024


Generative voice technologies are rapidly evolving, offering opportunities for more personalized and inclusive experiences. Traditional one-shot voice conversion (VC) requires a target recording during inference, limiting ease of usage in generating desired voice timbres. Text-guided generation offers an intuitive solution to convert voices to desired "DreamVoices" according to the users' needs. Our paper presents two major contributions to VC technology: (1) DreamVoiceDB, a robust dataset of voice timbre annotations for 900 speakers from VCTK and LibriTTS. (2) Two text-guided VC methods: DreamVC, an end-to-end diffusion-based text-guided VC model; and DreamVG, a versatile text-to-voice generation plugin that can be combined with any one-shot VC models. The experimental results demonstrate that our proposed methods trained on the DreamVoiceDB dataset generate voice timbres accurately aligned with the text prompt and achieve high-quality VC.
Investigating Self-Supervised Deep Representations for EEG-based Auditory Attention Decoding
Nov 07, 2023



Auditory Attention Decoding (AAD) algorithms play a crucial role in isolating desired sound sources within challenging acoustic environments directly from brain activity. Although recent research has shown promise in AAD using shallow representations such as auditory envelope and spectrogram, there has been limited exploration of deep Self-Supervised (SS) representations on a larger scale. In this study, we undertake a comprehensive investigation into the performance of linear decoders across 12 deep and 2 shallow representations, applied to EEG data from multiple studies spanning 57 subjects and multiple languages. Our experimental results consistently reveal the superiority of deep features for AAD at decoding background speakers, regardless of the datasets and analysis windows. This result indicates possible nonlinear encoding of unattended signals in the brain that are revealed using deep nonlinear features. Additionally, we analyze the impact of different layers of SS representations and window sizes on AAD performance. These findings underscore the potential for enhancing EEG-based AAD systems through the integration of deep feature representations.
DPM-TSE: A Diffusion Probabilistic Model for Target Sound Extraction
Oct 10, 2023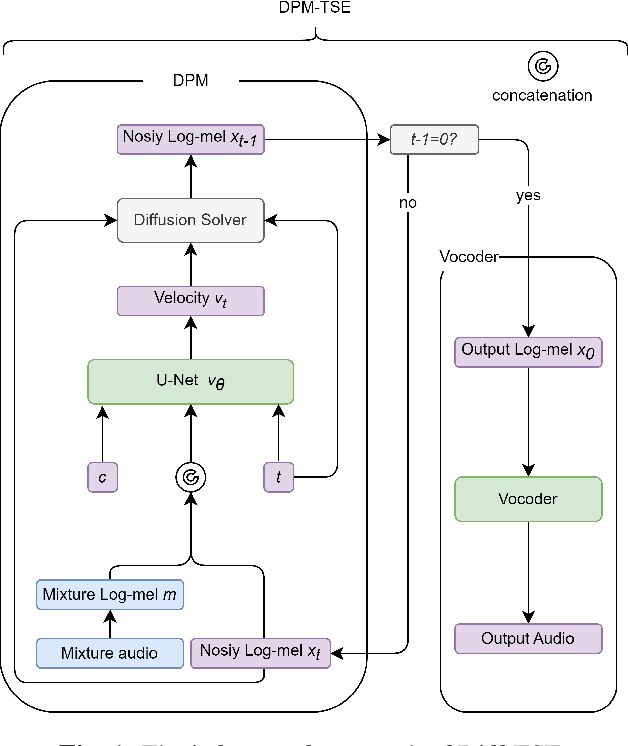
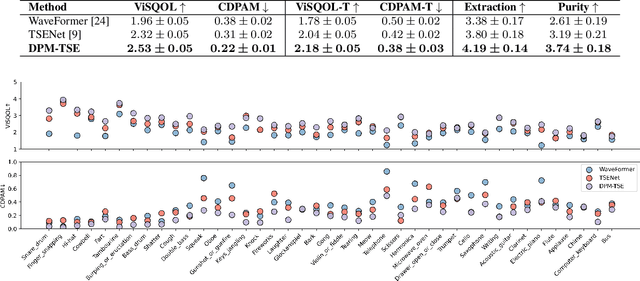

Common target sound extraction (TSE) approaches primarily relied on discriminative approaches in order to separate the target sound while minimizing interference from the unwanted sources, with varying success in separating the target from the background. This study introduces DPM-TSE, a first generative method based on diffusion probabilistic modeling (DPM) for target sound extraction, to achieve both cleaner target renderings as well as improved separability from unwanted sounds. The technique also tackles common background noise issues with DPM by introducing a correction method for noise schedules and sample steps. This approach is evaluated using both objective and subjective quality metrics on the FSD Kaggle 2018 dataset. The results show that DPM-TSE has a significant improvement in perceived quality in terms of target extraction and purity.
Stress Testing Chain-of-Thought Prompting for Large Language Models
Sep 28, 2023



This report examines the effectiveness of Chain-of-Thought (CoT) prompting in improving the multi-step reasoning abilities of large language models (LLMs). Inspired by previous studies \cite{Min2022RethinkingWork}, we analyze the impact of three types of CoT prompt perturbations, namely CoT order, CoT values, and CoT operators on the performance of GPT-3 on various tasks. Our findings show that incorrect CoT prompting leads to poor performance on accuracy metrics. Correct values in the CoT is crucial for predicting correct answers. Moreover, incorrect demonstrations, where the CoT operators or the CoT order are wrong, do not affect the performance as drastically when compared to the value based perturbations. This research deepens our understanding of CoT prompting and opens some new questions regarding the capability of LLMs to learn reasoning in context.