 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurg-R1: A Hierarchical Reasoning Foundation Model for Scalable and Interpretable Surgical Decision Support with Multi-Center Clinical Validation
Mar 12, 2026Surgical scene understanding demands not only accurate predictions but also interpretable reasoning that surgeons can verify against clinical expertise. However, existing surgical vision-language models generate predictions without reasoning chains, and general-purpose reasoning models fail on compositional surgical tasks without domain-specific knowledge. We present Surg-R1, a surgical Vision-Language Model that addresses this gap through hierarchical reasoning trained via a four-stage pipeline. Our approach introduces three key contributions: (1) a three-level reasoning hierarchy decomposing surgical interpretation into perceptual grounding, relational understanding, and contextual reasoning; (2) the largest surgical chain-of-thought dataset with 320,000 reasoning pairs; and (3) a four-stage training pipeline progressing from supervised fine-tuning to group relative policy optimization and iterative self-improvement. Evaluation on SurgBench, comprising six public benchmarks and six multi-center external validation datasets from five institutions, demonstrates that Surg-R1 achieves the highest Arena Score (64.9%) on public benchmarks versus Gemini 3.0 Pro (46.1%) and GPT-5.1 (37.9%), outperforming both proprietary reasoning models and specialized surgical VLMs on the majority of tasks spanning instrument localization, triplet recognition, phase recognition, action recognition, and critical view of safety assessment, with a 15.2 percentage point improvement over the strongest surgical baseline on external validation.
Neuro-Symbolic Synergy for Interactive World Modeling
Feb 12, 2026Large language models (LLMs) exhibit strong general-purpose reasoning capabilities, yet they frequently hallucinate when used as world models (WMs), where strict compliance with deterministic transition rules--particularly in corner cases--is essential. In contrast, Symbolic WMs provide logical consistency but lack semantic expressivity. To bridge this gap, we propose Neuro-Symbolic Synergy (NeSyS), a framework that integrates the probabilistic semantic priors of LLMs with executable symbolic rules to achieve both expressivity and robustness. NeSyS alternates training between the two models using trajectories inadequately explained by the other. Unlike rule-based prompting, the symbolic WM directly constrains the LLM by modifying its output probability distribution. The neural WM is fine-tuned only on trajectories not covered by symbolic rules, reducing training data by 50% without loss of accuracy. Extensive experiments on three distinct interactive environments, i.e., ScienceWorld, Webshop, and Plancraft, demonstrate NeSyS's consistent advantages over baselines in both WM prediction accuracy and data efficiency.
DreamVoice: Text-Guided Voice Conversion
Jun 24, 2024


Generative voice technologies are rapidly evolving, offering opportunities for more personalized and inclusive experiences. Traditional one-shot voice conversion (VC) requires a target recording during inference, limiting ease of usage in generating desired voice timbres. Text-guided generation offers an intuitive solution to convert voices to desired "DreamVoices" according to the users' needs. Our paper presents two major contributions to VC technology: (1) DreamVoiceDB, a robust dataset of voice timbre annotations for 900 speakers from VCTK and LibriTTS. (2) Two text-guided VC methods: DreamVC, an end-to-end diffusion-based text-guided VC model; and DreamVG, a versatile text-to-voice generation plugin that can be combined with any one-shot VC models. The experimental results demonstrate that our proposed methods trained on the DreamVoiceDB dataset generate voice timbres accurately aligned with the text prompt and achieve high-quality VC.
JetMoE: Reaching Llama2 Performance with 0.1M Dollars
Apr 11, 2024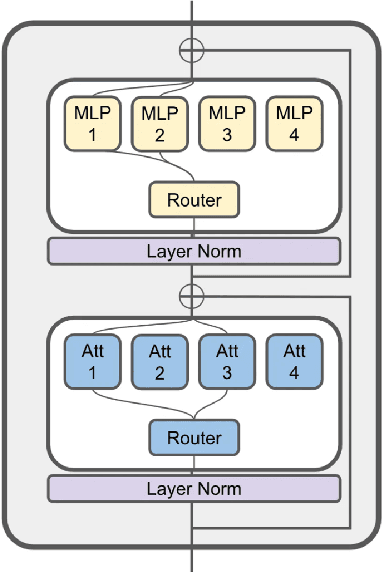

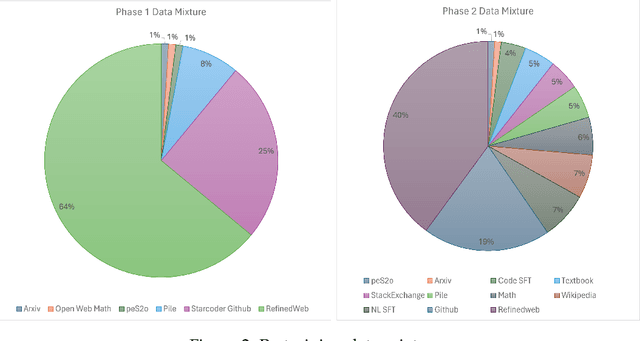
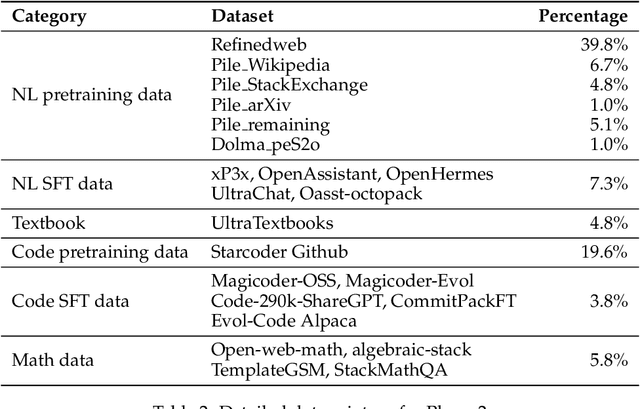
Large Language Models (LLMs) have achieved remarkable results, but their increasing resource demand has become a major obstacle to the development of powerful and accessible super-human intelligence. This report introduces JetMoE-8B, a new LLM trained with less than $0.1 million, using 1.25T tokens from carefully mixed open-source corpora and 30,000 H100 GPU hours. Despite its low cost, the JetMoE-8B demonstrates impressive performance, with JetMoE-8B outperforming the Llama2-7B model and JetMoE-8B-Chat surpassing the Llama2-13B-Chat model. These results suggest that LLM training can be much more cost-effective than generally thought. JetMoE-8B is based on an efficient Sparsely-gated Mixture-of-Experts (SMoE) architecture, composed of attention and feedforward experts. Both layers are sparsely activated, allowing JetMoE-8B to have 8B parameters while only activating 2B for each input token, reducing inference computation by about 70% compared to Llama2-7B. Moreover, JetMoE-8B is highly open and academia-friendly, using only public datasets and training code. All training parameters and data mixtures have been detailed in this report to facilitate future efforts in the development of open foundation models. This transparency aims to encourage collaboration and further advancements in the field of accessible and efficient LLMs. The model weights are publicly available at https://github.com/myshell-ai/JetMoE.
OpenVoice: Versatile Instant Voice Cloning
Dec 03, 2023
We introduce OpenVoice, a versatile voice cloning approach that requires only a short audio clip from the reference speaker to replicate their voice and generate speech in multiple languages. OpenVoice represents a significant advancement in addressing the following open challenges in the field: 1) Flexible Voice Style Control. OpenVoice enables granular control over voice styles, including emotion, accent, rhythm, pauses, and intonation, in addition to replicating the tone color of the reference speaker. The voice styles are not directly copied from and constrained by the style of the reference speaker. Previous approaches lacked the ability to flexibly manipulate voice styles after cloning. 2) Zero-Shot Cross-Lingual Voice Cloning. OpenVoice achieves zero-shot cross-lingual voice cloning for languages not included in the massive-speaker training set. Unlike previous approaches, which typically require extensive massive-speaker multi-lingual (MSML) dataset for all languages, OpenVoice can clone voices into a new language without any massive-speaker training data for that language. OpenVoice is also computationally efficient, costing tens of times less than commercially available APIs that offer even inferior performance. To foster further research in the field, we have made the source code and trained model publicly accessible. We also provide qualitative results in our demo website. Prior to its public release, our internal version of OpenVoice was used tens of millions of times by users worldwide between May and October 2023, serving as the backend of MyShell.ai.
SABLAS: Learning Safe Control for Black-box Dynamical Systems
Jan 09, 2022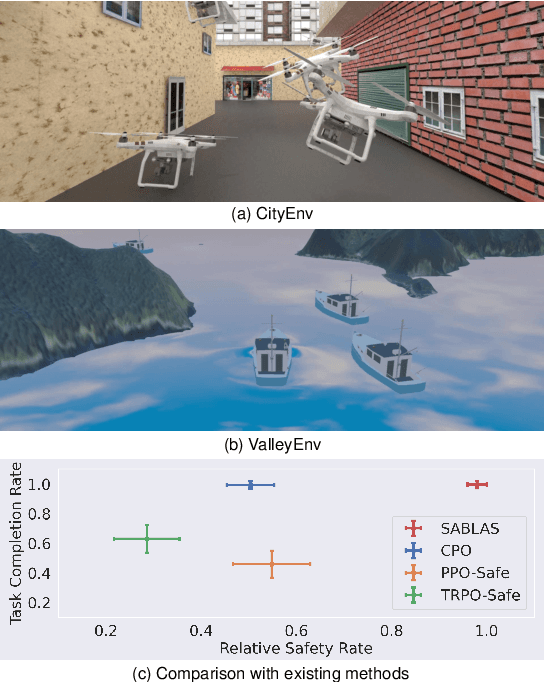
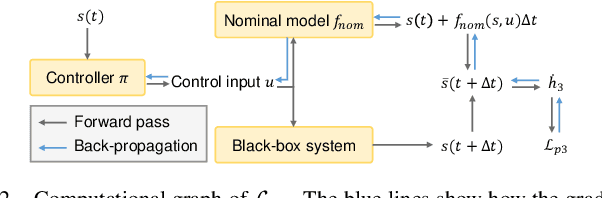
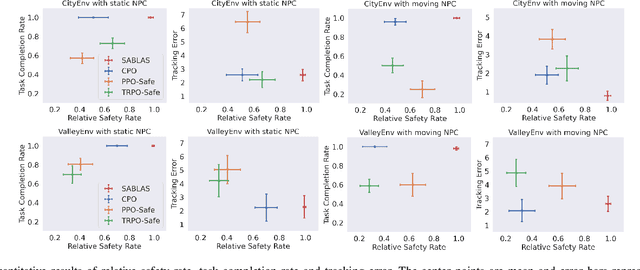
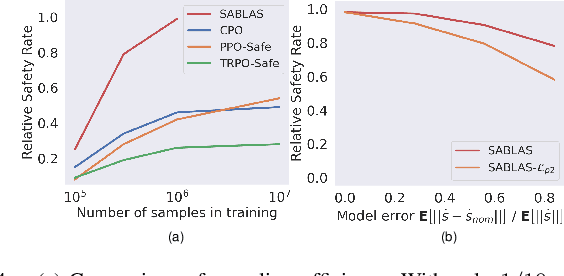
Control certificates based on barrier functions have been a powerful tool to generate probably safe control policies for dynamical systems. However, existing methods based on barrier certificates are normally for white-box systems with differentiable dynamics, which makes them inapplicable to many practical applications where the system is a black-box and cannot be accurately modeled. On the other side, model-free reinforcement learning (RL) methods for black-box systems suffer from lack of safety guarantees and low sampling efficiency. In this paper, we propose a novel method that can learn safe control policies and barrier certificates for black-box dynamical systems, without requiring for an accurate system model. Our method re-designs the loss function to back-propagate gradient to the control policy even when the black-box dynamical system is non-differentiable, and we show that the safety certificates hold on the black-box system. Empirical results in simulation show that our method can significantly improve the performance of the learned policies by achieving nearly 100% safety and goal reaching rates using much fewer training samples, compared to state-of-the-art black-box safe control methods. Our learned agents can also generalize to unseen scenarios while keeping the original performance. The source code can be found at https://github.com/Zengyi-Qin/bcbf.
Safe Nonlinear Control Using Robust Neural Lyapunov-Barrier Functions
Sep 14, 2021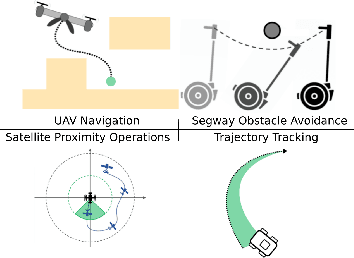
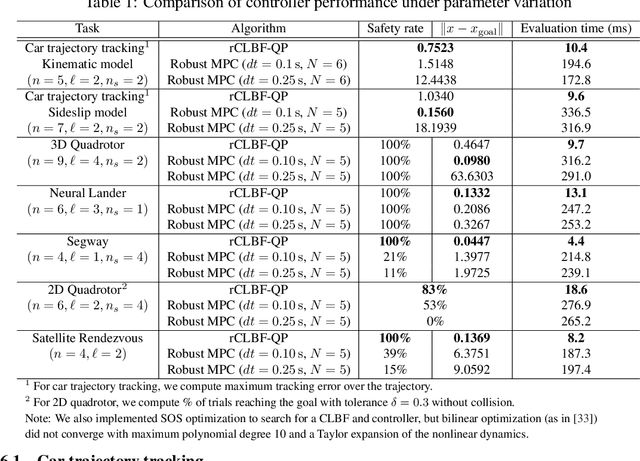

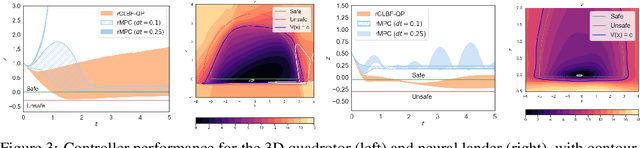
Safety and stability are common requirements for robotic control systems; however, designing safe, stable controllers remains difficult for nonlinear and uncertain models. We develop a model-based learning approach to synthesize robust feedback controllers with safety and stability guarantees. We take inspiration from robust convex optimization and Lyapunov theory to define robust control Lyapunov barrier functions that generalize despite model uncertainty. We demonstrate our approach in simulation on problems including car trajectory tracking, nonlinear control with obstacle avoidance, satellite rendezvous with safety constraints, and flight control with a learned ground effect model. Simulation results show that our approach yields controllers that match or exceed the capabilities of robust MPC while reducing computational costs by an order of magnitude.
Reactive and Safe Road User Simulations using Neural Barrier Certificates
Sep 14, 2021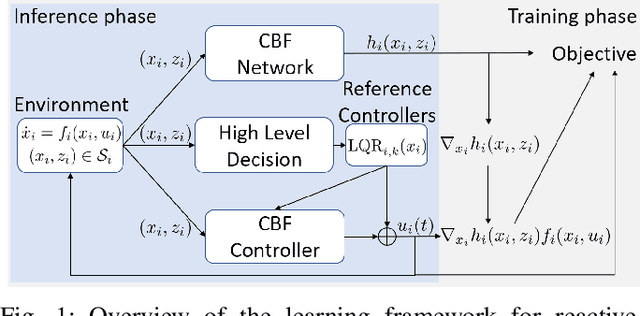
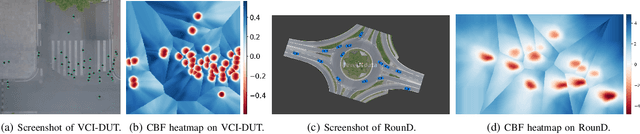

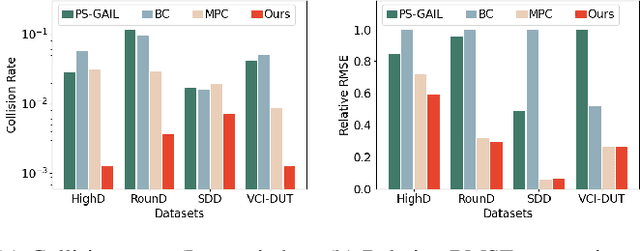
Reactive and safe agent modelings are important for nowadays traffic simulator designs and safe planning applications. In this work, we proposed a reactive agent model which can ensure safety without comprising the original purposes, by learning only high-level decisions from expert data and a low-level decentralized controller guided by the jointly learned decentralized barrier certificates. Empirical results show that our learned road user simulation models can achieve a significant improvement in safety comparing to state-of-the-art imitation learning and pure control-based methods, while being similar to human agents by having smaller errors to the expert data. Moreover, our learned reactive agents are shown to generalize better to unseen traffic conditions, and react better to other road users and therefore can help understand challenging planning problems pragmatically.
Density Constrained Reinforcement Learning
Jun 24, 2021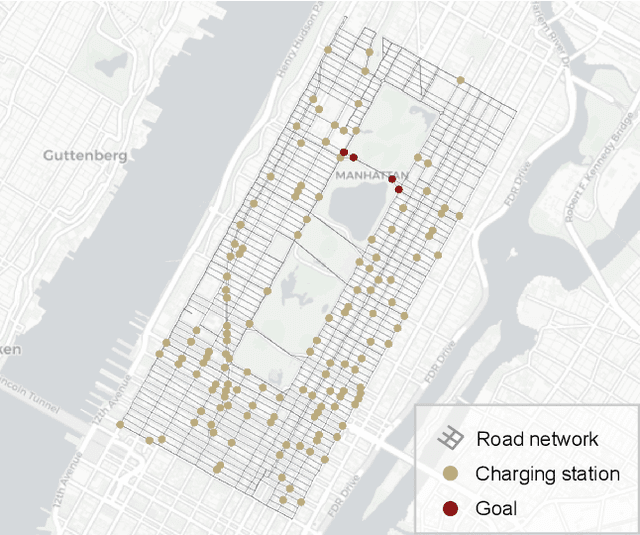
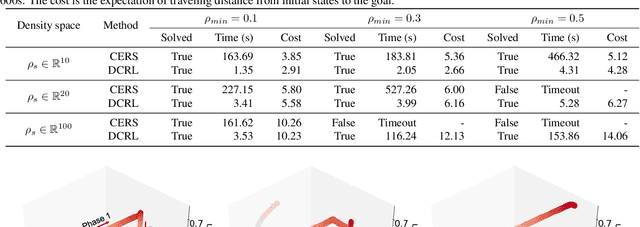

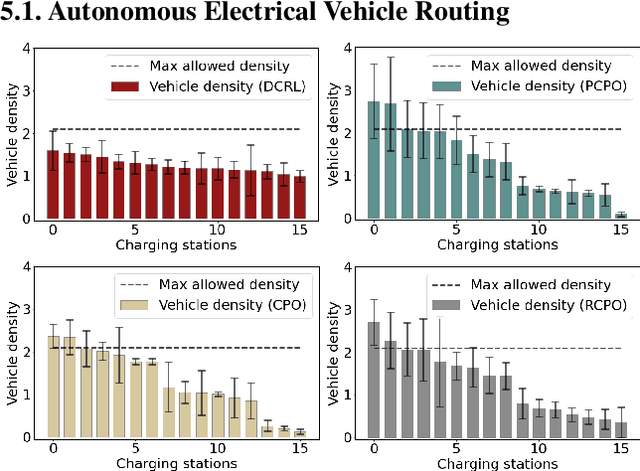
We study constrained reinforcement learning (CRL) from a novel perspective by setting constraints directly on state density functions, rather than the value functions considered by previous works. State density has a clear physical and mathematical interpretation, and is able to express a wide variety of constraints such as resource limits and safety requirements. Density constraints can also avoid the time-consuming process of designing and tuning cost functions required by value function-based constraints to encode system specifications. We leverage the duality between density functions and Q functions to develop an effective algorithm to solve the density constrained RL problem optimally and the constrains are guaranteed to be satisfied. We prove that the proposed algorithm converges to a near-optimal solution with a bounded error even when the policy update is imperfect. We use a set of comprehensive experiments to demonstrate the advantages of our approach over state-of-the-art CRL methods, with a wide range of density constrained tasks as well as standard CRL benchmarks such as Safety-Gym.
MonoGRNet: A General Framework for Monocular 3D Object Detection
Apr 18, 2021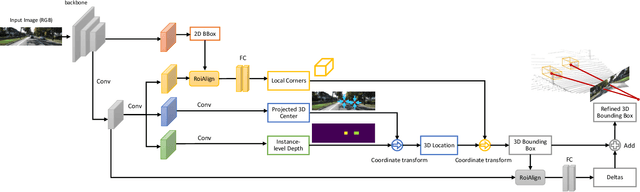
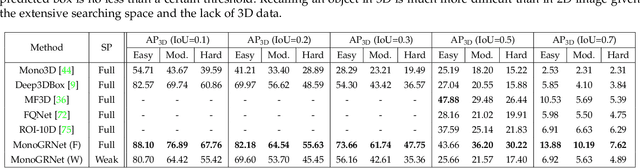
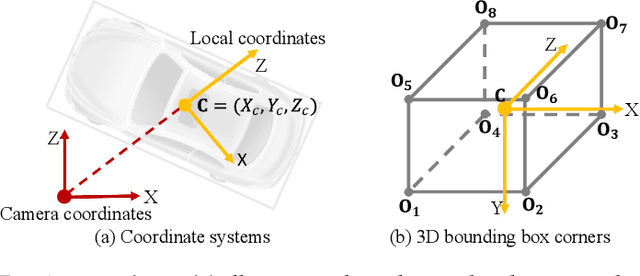
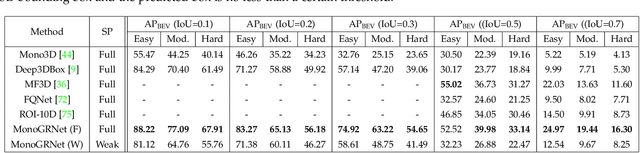
Detecting and localizing objects in the real 3D space, which plays a crucial role in scene understanding, is particularly challenging given only a monocular image due to the geometric information loss during imagery projection. We propose MonoGRNet for the amodal 3D object detection from a monocular image via geometric reasoning in both the observed 2D projection and the unobserved depth dimension. MonoGRNet decomposes the monocular 3D object detection task into four sub-tasks including 2D object detection, instance-level depth estimation, projected 3D center estimation and local corner regression. The task decomposition significantly facilitates the monocular 3D object detection, allowing the target 3D bounding boxes to be efficiently predicted in a single forward pass, without using object proposals, post-processing or the computationally expensive pixel-level depth estimation utilized by previous methods. In addition, MonoGRNet flexibly adapts to both fully and weakly supervised learning, which improves the feasibility of our framework in diverse settings. Experiments are conducted on KITTI, Cityscapes and MS COCO datasets. Results demonstrate the promising performance of our framework in various scenarios.