 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRePO-VLA: Recovery-Driven Policy Optimization for Vision-Language-Action Models
May 10, 2026Vision-Language-Action (VLA) models remain brittle in long-horizon, contact-rich manipulation because success-only imitation provides little supervision for execution drift, while failed rollouts are often discarded. We introduce RePO-VLA, a recovery-driven policy optimization framework that assigns distinct roles to success, recovery, and failure trajectories. RePO-VLA first applies Recovery-Aware Initialization (RAI), slicing recovery segments and resetting history so corrective actions depend on the current adverse state rather than the preceding failure. It then learns a Progress-Aware Semantic Value Function (PAS-VF), aligning spatiotemporal trajectory features with instructions and successful references. The resulting labels salvage useful failure prefixes via reliability decay, while low-value labels mark drift and terminal breakdowns, teaching differences among nominal, failed, and corrective actions. The data engine turns adverse states into planner-generated or human-collected corrective rollouts, teaching recovery to the success manifold. Value-Conditioned Refinement (VCR) trains the policy to prefer high-progress actions. At deployment, a fixed high value ($v=1.0$) biases actions toward the learned success manifold without online failure detectors or heuristic retries. We introduce FRBench, with standardized error injection and recovery-focused evaluation. Across simulated and real-world bimanual tasks, RePO-VLA improves robustness, raising adversarial success from 20% to 75% on average and up to 80% in scaled real-world trials.
Human Behavior Modeling via Identification of Task Objective and Variability
Apr 23, 2024Human behavior modeling is important for the design and implementation of human-automation interactive control systems. In this context, human behavior refers to a human's control input to systems. We propose a novel method for human behavior modeling that uses human demonstrations for a given task to infer the unknown task objective and the variability. The task objective represents the human's intent or desire. It can be inferred by the inverse optimal control and improve the understanding of human behavior by providing an explainable objective function behind the given human behavior. Meanwhile, the variability denotes the intrinsic uncertainty in human behavior. It can be described by a Gaussian mixture model and capture the uncertainty in human behavior which cannot be encoded by the task objective. The proposed method can improve the prediction accuracy of human behavior by leveraging both task objective and variability. The proposed method is demonstrated through human-subject experiments using an illustrative quadrotor remote control example.
Learning-based Perception Contracts and Applications
Sep 24, 2023Perception modules are integral in many modern autonomous systems, but their accuracy can be subject to the vagaries of the environment. In this paper, we propose a learning-based approach that can automatically characterize the error of a perception module from data and use this for safe control. The proposed approach constructs a {\em perception contract (PC)\/} which generates a set that contains the ground-truth value that is being estimated by the perception module, with high probability. We apply the proposed approach to study a vision pipeline deployed on a quadcopter. With the proposed approach, we successfully constructed a PC for the vision pipeline. We then designed a control algorithm that utilizes the learned PC, with the goal of landing the quadcopter safely on a landing pad. Experiments show that with the learned PC, the control algorithm safely landed the quadcopter despite the error from the perception module, while the baseline algorithm without using the learned PC failed to do so.
Learning Certifiably Robust Controllers Using Fragile Perception
Sep 22, 2022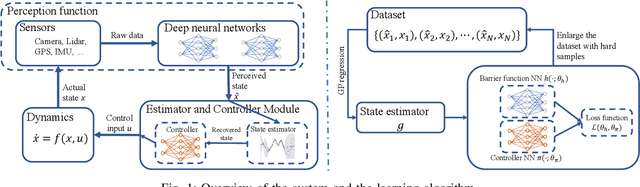
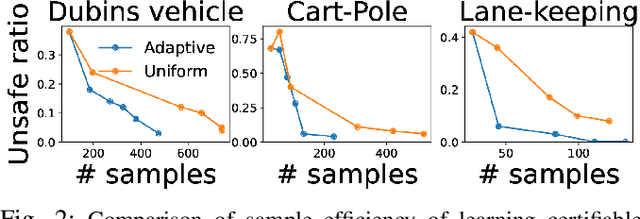
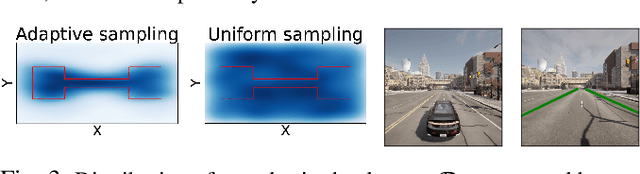
Advances in computer vision and machine learning enable robots to perceive their surroundings in powerful new ways, but these perception modules have well-known fragilities. We consider the problem of synthesizing a safe controller that is robust despite perception errors. The proposed method constructs a state estimator based on Gaussian processes with input-dependent noises. This estimator computes a high-confidence set for the actual state given a perceived state. Then, a robust neural network controller is synthesized that can provably handle the state uncertainty. Furthermore, an adaptive sampling algorithm is proposed to jointly improve the estimator and controller. Simulation experiments, including a realistic vision-based lane-keeping example in CARLA, illustrate the promise of the proposed approach in synthesizing robust controllers with deep-learning-based perception.
DistPro: Searching A Fast Knowledge Distillation Process via Meta Optimization
Apr 12, 2022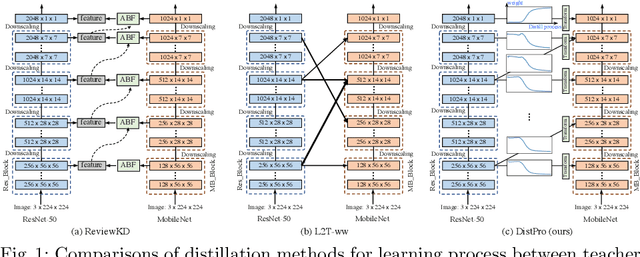
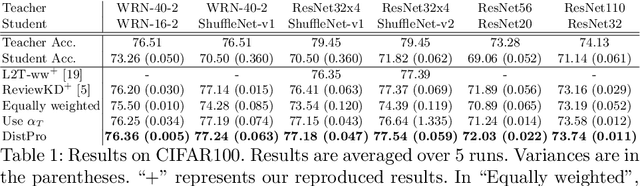
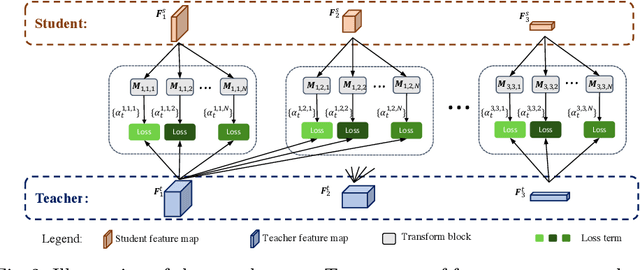

Recent Knowledge distillation (KD) studies show that different manually designed schemes impact the learned results significantly. Yet, in KD, automatically searching an optimal distillation scheme has not yet been well explored. In this paper, we propose DistPro, a novel framework which searches for an optimal KD process via differentiable meta-learning. Specifically, given a pair of student and teacher networks, DistPro first sets up a rich set of KD connection from the transmitting layers of the teacher to the receiving layers of the student, and in the meanwhile, various transforms are also proposed for comparing feature maps along its pathway for the distillation. Then, each combination of a connection and a transform choice (pathway) is associated with a stochastic weighting process which indicates its importance at every step during the distillation. In the searching stage, the process can be effectively learned through our proposed bi-level meta-optimization strategy. In the distillation stage, DistPro adopts the learned processes for knowledge distillation, which significantly improves the student accuracy especially when faster training is required. Lastly, we find the learned processes can be generalized between similar tasks and networks. In our experiments, DistPro produces state-of-the-art (SoTA) accuracy under varying number of learning epochs on popular datasets, i.e. CIFAR100 and ImageNet, which demonstrate the effectiveness of our framework.
Cooperative Task and Motion Planning for Multi-Arm Assembly Systems
Mar 04, 2022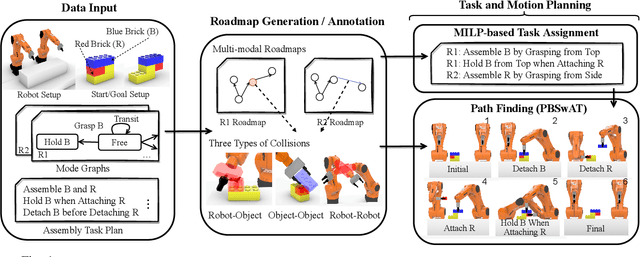
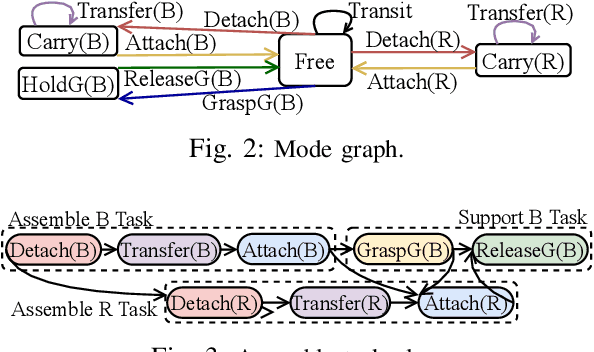
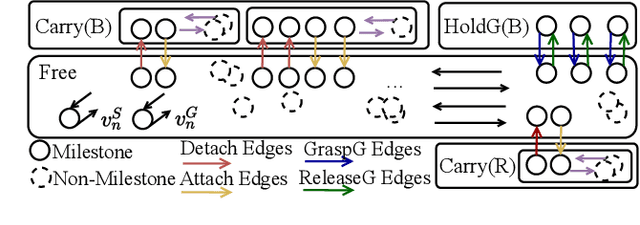
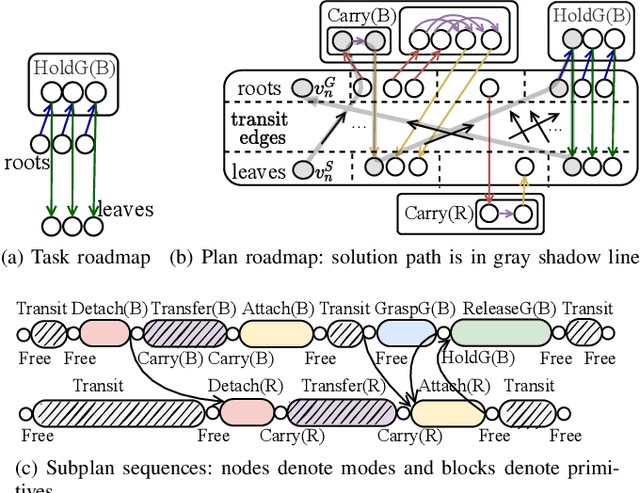
Multi-robot assembly systems are becoming increasingly appealing in manufacturing due to their ability to automatically, flexibly, and quickly construct desired structural designs. However, effectively planning for these systems in a manner that ensures each robot is simultaneously productive, and not idle, is challenging due to (1) the close proximity that the robots must operate in to manipulate the structure and (2) the inherent structural partial orderings on when each part can be installed. In this paper, we present a task and motion planning framework that jointly plans safe, low-makespan plans for a team of robots to assemble complex spatial structures. Our framework takes a hierarchical approach that, at the high level, uses Mixed-integer Linear Programs to compute an abstract plan comprised of an allocation of robots to tasks subject to precedence constraints and, at the low level, builds on a state-of-the-art algorithm for Multi-Agent Path Finding to plan collision-free robot motions that realize this abstract plan. Critical to our approach is the inclusion of certain collision constraints and movement durations during high-level planning, which better informs the search for abstract plans that are likely to be both feasible and low-makespan while keeping the search tractable. We demonstrate our planning system on several challenging assembly domains with several (sometimes heterogeneous) robots with grippers or suction plates for assembling structures with up to 23 objects involving Lego bricks, bars, plates, or irregularly shaped blocks.
Multi-agent Motion Planning from Signal Temporal Logic Specifications
Jan 13, 2022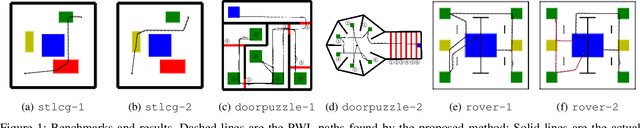
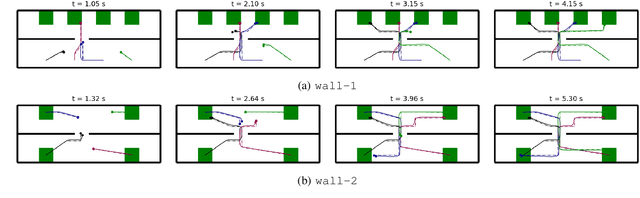
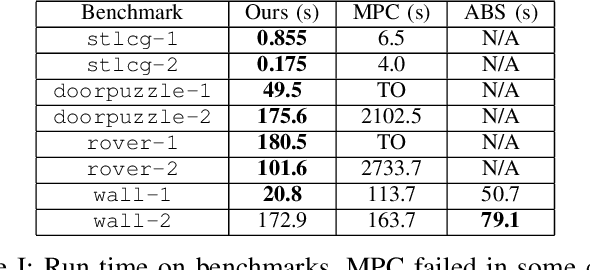
We tackle the challenging problem of multi-agent cooperative motion planning for complex tasks described using signal temporal logic (STL), where robots can have nonlinear and nonholonomic dynamics. Existing methods in multi-agent motion planning, especially those based on discrete abstractions and model predictive control (MPC), suffer from limited scalability with respect to the complexity of the task, the size of the workspace, and the planning horizon. We present a method based on {\em timed waypoints\/} to address this issue. We show that timed waypoints can help abstract nonlinear behaviors of the system as safety envelopes around the reference path defined by those waypoints. Then the search for waypoints satisfying the STL specifications can be inductively encoded as a mixed-integer linear program. The agents following the synthesized timed waypoints have their tasks automatically allocated, and are guaranteed to satisfy the STL specifications while avoiding collisions. We evaluate the algorithm on a wide variety of benchmarks. Results show that it supports multi-agent planning from complex specification over long planning horizons, and significantly outperforms state-of-the-art abstraction-based and MPC-based motion planning methods. The implementation is available at https://github.com/sundw2014/STLPlanning.
SABLAS: Learning Safe Control for Black-box Dynamical Systems
Jan 09, 2022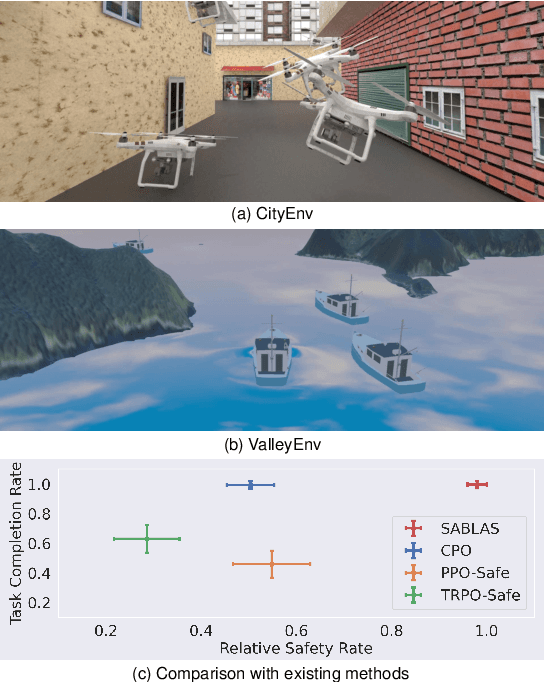
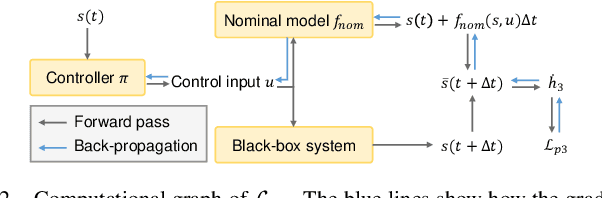
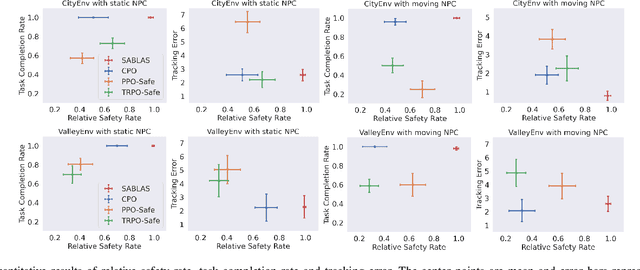
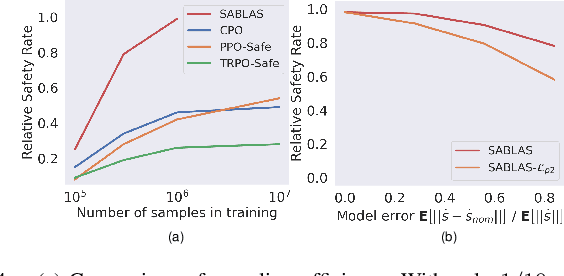
Control certificates based on barrier functions have been a powerful tool to generate probably safe control policies for dynamical systems. However, existing methods based on barrier certificates are normally for white-box systems with differentiable dynamics, which makes them inapplicable to many practical applications where the system is a black-box and cannot be accurately modeled. On the other side, model-free reinforcement learning (RL) methods for black-box systems suffer from lack of safety guarantees and low sampling efficiency. In this paper, we propose a novel method that can learn safe control policies and barrier certificates for black-box dynamical systems, without requiring for an accurate system model. Our method re-designs the loss function to back-propagate gradient to the control policy even when the black-box dynamical system is non-differentiable, and we show that the safety certificates hold on the black-box system. Empirical results in simulation show that our method can significantly improve the performance of the learned policies by achieving nearly 100% safety and goal reaching rates using much fewer training samples, compared to state-of-the-art black-box safe control methods. Our learned agents can also generalize to unseen scenarios while keeping the original performance. The source code can be found at https://github.com/Zengyi-Qin/bcbf.
Learning Density Distribution of Reachable States for Autonomous Systems
Sep 14, 2021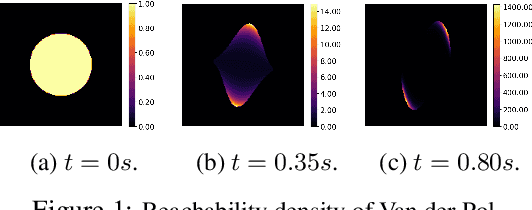
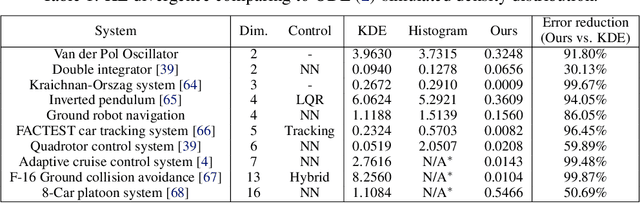
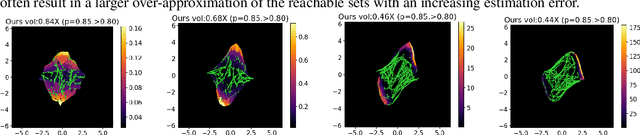
State density distribution, in contrast to worst-case reachability, can be leveraged for safety-related problems to better quantify the likelihood of the risk for potentially hazardous situations. In this work, we propose a data-driven method to compute the density distribution of reachable states for nonlinear and even black-box systems. Our semi-supervised approach learns system dynamics and the state density jointly from trajectory data, guided by the fact that the state density evolution follows the Liouville partial differential equation. With the help of neural network reachability tools, our approach can estimate the set of all possible future states as well as their density. Moreover, we could perform online safety verification with probability ranges for unsafe behaviors to occur. We use an extensive set of experiments to show that our learned solution can produce a much more accurate estimate on density distribution, and can quantify risks less conservatively and flexibly comparing with worst-case analysis.
Uncertainty-aware Safe Exploratory Planning using Gaussian Process and Neural Control Contraction Metric
May 13, 2021
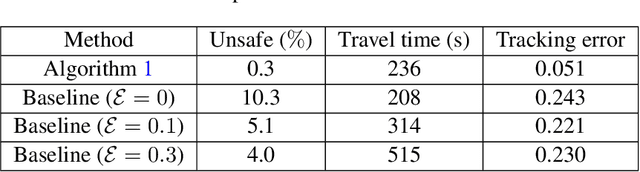
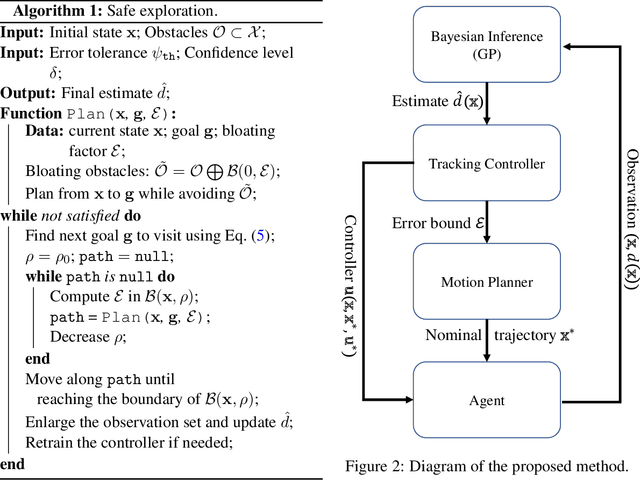

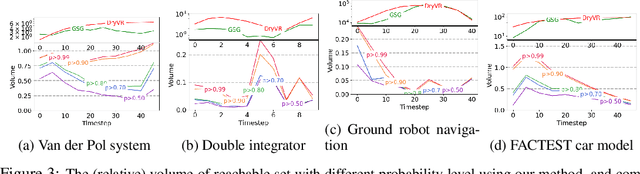
In this paper, we consider the problem of using a robot to explore an environment with an unknown, state-dependent disturbance function while avoiding some forbidden areas. The goal of the robot is to safely collect observations of the disturbance and construct an accurate estimate of the underlying disturbance function. We use Gaussian Process (GP) to get an estimate of the disturbance from data with a high-confidence bound on the regression error. Furthermore, we use neural Contraction Metrics to derive a tracking controller and the corresponding high-confidence uncertainty tube around the nominal trajectory planned for the robot, based on the estimate of the disturbance. From the robustness of the Contraction Metric, error bound can be pre-computed and used by the motion planner such that the actual trajectory is guaranteed to be safe. As the robot collects more and more observations along its trajectory, the estimate of the disturbance becomes more and more accurate, which in turn improves the performance of the tracking controller and enlarges the free space that the robot can safely explore. We evaluate the proposed method using a carefully designed environment with a ground vehicle. Results show that with the proposed method the robot can thoroughly explore the environment safely and quickly.