 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Should a Robot Replan? Regret-Guided Update Scheduling in Time-Varying MDPs
Jun 15, 2026Robots operating in non-stationary environments must continually adapt their policies as the dynamics drift, but onboard energy and compute budgets cap how often a full state estimation and re-planning step can be performed. This raises a question: \emph{when}, along a horizon, should a robot spend its limited budget? We formulate this problem in time-varying Markov decision processes (TVMDPs) with a known bound on the rate of transition drift. We model execution as a \emph{skip-update} scheme in which, at chosen update times, the agent estimates the transition kernel by maximum likelihood and computes a finite-horizon policy, and between updates reuses this policy under a propagated state estimate. We analyze the dynamic regret of this scheme and show how it grows during skip intervals in terms of the properties of the TVMDP and the skip lengths; the resulting bound answers the opening question via an online, regret-guided update rule that allocates the budget adaptively. We evaluate the rule in a simulated Mars-rover navigation task with time-varying slip dynamics and on a Crazyflie quadrotor in indoor obstacle fields. Adaptive allocation outperforms other budgeted baselines.
Convergence of Gradient-based MAML in LQR
Sep 15, 2023


The main objective of this research paper is to investigate the local convergence characteristics of Model-agnostic Meta-learning (MAML) when applied to linear system quadratic optimal control (LQR). MAML and its variations have become popular techniques for quickly adapting to new tasks by leveraging previous learning knowledge in areas like regression, classification, and reinforcement learning. However, its theoretical guarantees remain unknown due to non-convexity and its structure, making it even more challenging to ensure stability in the dynamic system setting. This study focuses on exploring MAML in the LQR setting, providing its local convergence guarantees while maintaining the stability of the dynamical system. The paper also presents simple numerical results to demonstrate the convergence properties of MAML in LQR tasks.
Learning Certifiably Robust Controllers Using Fragile Perception
Sep 22, 2022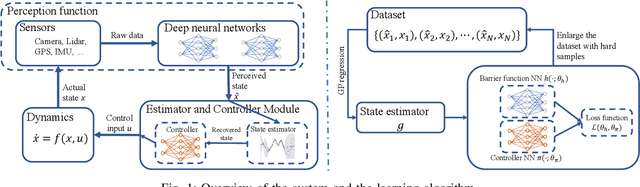
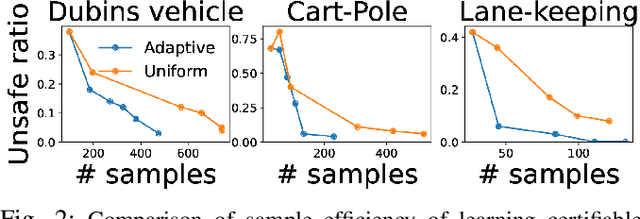
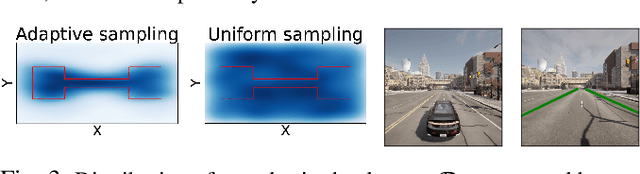
Advances in computer vision and machine learning enable robots to perceive their surroundings in powerful new ways, but these perception modules have well-known fragilities. We consider the problem of synthesizing a safe controller that is robust despite perception errors. The proposed method constructs a state estimator based on Gaussian processes with input-dependent noises. This estimator computes a high-confidence set for the actual state given a perceived state. Then, a robust neural network controller is synthesized that can provably handle the state uncertainty. Furthermore, an adaptive sampling algorithm is proposed to jointly improve the estimator and controller. Simulation experiments, including a realistic vision-based lane-keeping example in CARLA, illustrate the promise of the proposed approach in synthesizing robust controllers with deep-learning-based perception.
Optimistic Optimization for Statistical Model Checking with Regret Bounds
Nov 04, 2019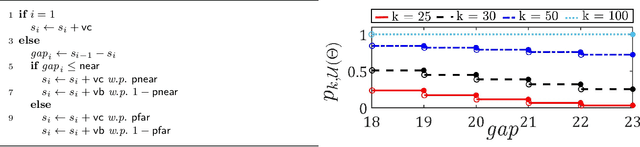
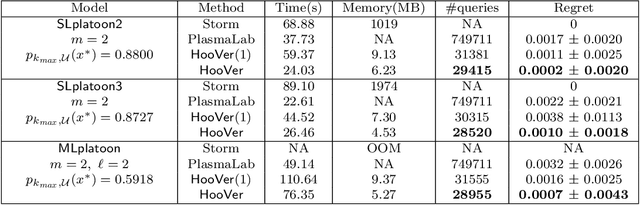
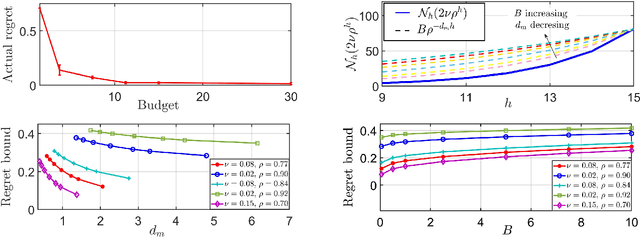
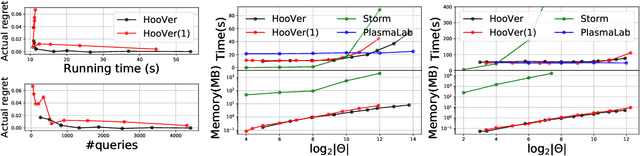
We explore application of multi-armed bandit algorithms to statistical model checking (SMC) of Markov chains initialized to a set of states. We observe that model checking problems requiring maximization of probabilities of sets of execution over all choices of the initial states, can be formulated as a multi-armed bandit problem, for appropriate costs and rewards. Therefore, the problem can be solved using multi-fidelity hierarchical optimistic optimization (MFHOO). Bandit algorithms, and MFHOO in particular, give (regret) bounds on the sample efficiency which rely on the smoothness and the near-optimality dimension of the objective function, and are a new addition to the existing types of bounds in the SMC literature. We present a new SMC tool---HooVer---built on these principles and our experiments suggest that: Compared with exact probabilistic model checking tools like Storm, HooVer scales better; compared with the statistical model checking tool PlasmaLab, HooVer can require much less data to achieve comparable results.
A Game Theoretical Framework for the Evaluation of Unmanned Aircraft Systems Airspace Integration Concepts
Apr 17, 2019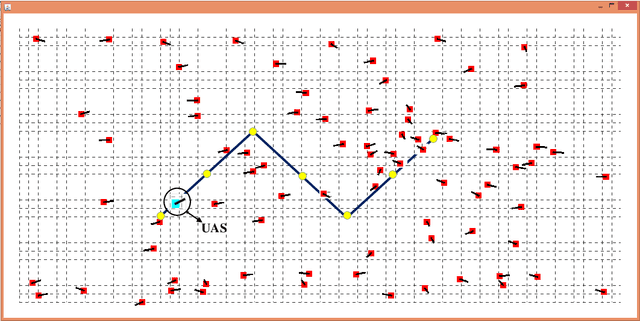
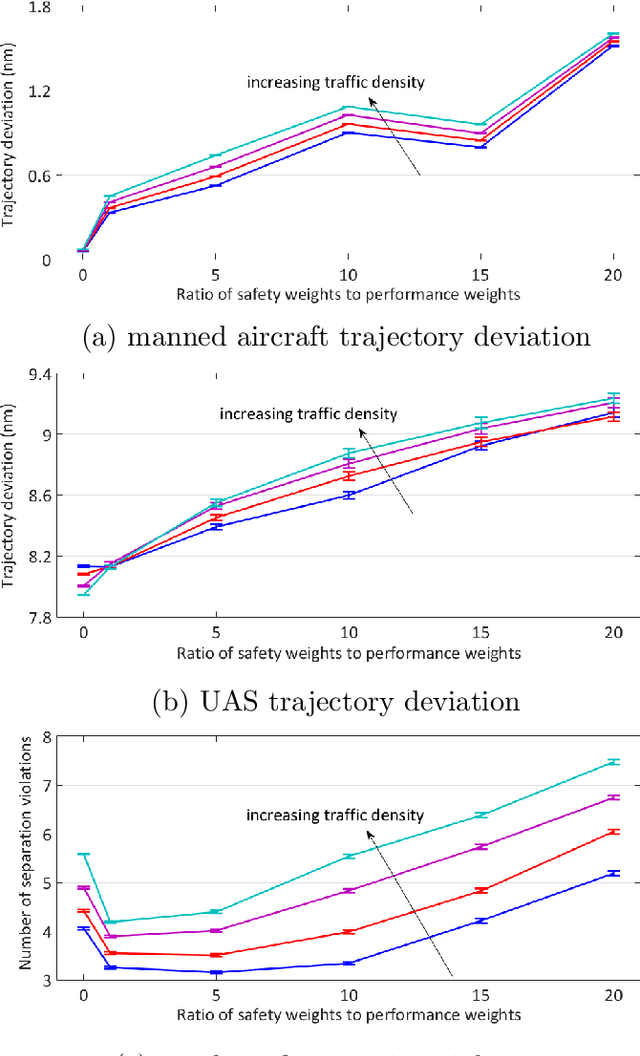
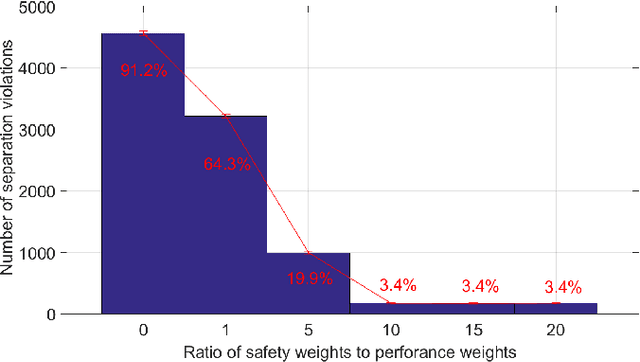
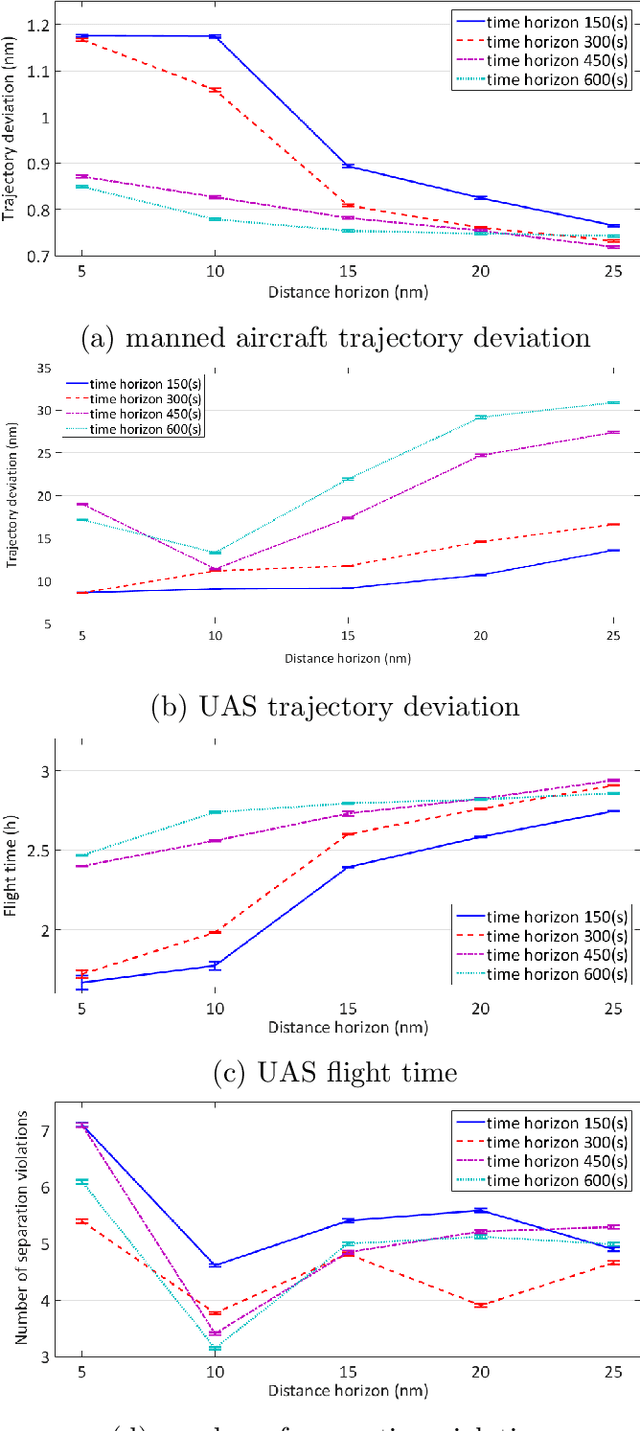
Predicting the outcomes of integrating Unmanned Aerial Systems (UAS) into the National Aerospace (NAS) is a complex problem which is required to be addressed by simulation studies before allowing the routine access of UAS into the NAS. This thesis focuses on providing 2D and 3D simulation frameworks using a game theoretical methodology to evaluate integration concepts in scenarios where manned and unmanned air vehicles co-exist. The fundamental gap in the literature is that the models of interaction between manned and unmanned vehicles are insufficient: a) they assume that pilot behavior is known a priori and b) they disregard decision making processes. The contribution of this work is to propose a modeling framework, in which, human pilot reactions are modeled using reinforcement learning and a game theoretical concept called level-k reasoning to fill this gap. The level-k reasoning concept is based on the assumption that humans have various levels of decision making. Reinforcement learning is a mathematical learning method that is rooted in human learning. In this work, a classical and an approximate reinforcement learning (Neural Fitted Q Iteration) methods are used to model time-extended decisions of pilots with 2D and 3D maneuvers. An analysis of UAS integration is conducted using example scenarios in the presence of manned aircraft and fully autonomous UAS equipped with sense and avoid algorithms.
A 3D Game Theoretical Framework for the Evaluation of Unmanned Aircraft Systems Airspace Integration Concepts
Feb 27, 2018Predicting the outcomes of integrating Unmanned Aerial Systems (UAS) into the National Airspace System (NAS) is a complex problem which is required to be addressed by simulation studies before allowing the routine access of UAS into the NAS. This paper focuses on providing a 3-dimensional (3D) simulation framework using a game theoretical methodology to evaluate integration concepts using scenarios where manned and unmanned air vehicles co-exist. In the proposed method, human pilot interactive decision making process is incorporated into airspace models which can fill the gap in the literature where the pilot behavior is generally assumed to be known a priori. The proposed human pilot behavior is modeled using dynamic level-k reasoning concept and approximate reinforcement learning. The level-k reasoning concept is a notion in game theory and is based on the assumption that humans have various levels of decision making. In the conventional "static" approach, each agent makes assumptions about his or her opponents and chooses his or her actions accordingly. On the other hand, in the dynamic level-k reasoning, agents can update their beliefs about their opponents and revise their level-k rule. In this study, Neural Fitted Q Iteration, which is an approximate reinforcement learning method, is used to model time-extended decisions of pilots with 3D maneuvers. An analysis of UAS integration is conducted using an example 3D scenario in the presence of manned aircraft and fully autonomous UAS equipped with sense and avoid algorithms.