 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHy-Embodied-0.5-VLA: From Vision-Language-Action Models to a Real-World Robot Learning Stack
Jun 12, 2026In this report, we present Hy-Embodied-0.5-VLA, abbreviated as HyVLA-0.5, an end-to-end system that spans the full robot learning stack: data collection, model design, continued pre-training and supervised fine-tuning, RL post-training, and real-world deployment. Each component serves a distinct role in this stack.
GEM: Generative Supervision Helps Embodied Intelligence
May 27, 2026Embodied Vision-Language Models (VLMs) have demonstrated impressive performance and generalization in robotics, particularly within Vision-Language-Action frameworks. However, a significant gap remains between the high-level semantic focus of standard text-guided pre-training paradigms and the low-level spatial and physical knowledge critical for execution in embodied environments. In this paper, we introduce GEM, a Generative-supervised Embodied vision-language Model designed to bridge this divide. We propose integrating a depth map generation task directly into the VLM pre-training phase. By training this generative objective jointly with the main model, we observe substantial improvements in embodied intelligence, significantly enhancing both semantic understanding and physical operation capabilities. To support this paradigm, we curate and release GEM-4M, a comprehensive large-scale dataset featuring a mixture of grounding, reasoning, and planning data paired with high-quality depth supervision. Extensive experiments demonstrate that GEM achieves state-of-the-art results across diverse embodied benchmarks. Furthermore, our deployed action model, GEM-VLA, exhibits vastly superior task execution abilities in both simulation environments and real-world evaluations. Code, models, and datasets are available at https://zhaorw02.github.io/GEM/
HY-Embodied-0.5: Embodied Foundation Models for Real-World Agents
Apr 08, 2026We introduce HY-Embodied-0.5, a family of foundation models specifically designed for real-world embodied agents. To bridge the gap between general Vision-Language Models (VLMs) and the demands of embodied agents, our models are developed to enhance the core capabilities required by embodied intelligence: spatial and temporal visual perception, alongside advanced embodied reasoning for prediction, interaction, and planning. The HY-Embodied-0.5 suite comprises two primary variants: an efficient model with 2B activated parameters designed for edge deployment, and a powerful model with 32B activated parameters targeted for complex reasoning. To support the fine-grained visual perception essential for embodied tasks, we adopt a Mixture-of-Transformers (MoT) architecture to enable modality-specific computing. By incorporating latent tokens, this design effectively enhances the perceptual representation of the models. To improve reasoning capabilities, we introduce an iterative, self-evolving post-training paradigm. Furthermore, we employ on-policy distillation to transfer the advanced capabilities of the large model to the smaller variant, thereby maximizing the performance potential of the compact model. Extensive evaluations across 22 benchmarks, spanning visual perception, spatial reasoning, and embodied understanding, demonstrate the effectiveness of our approach. Our MoT-2B model outperforms similarly sized state-of-the-art models on 16 benchmarks, while the 32B variant achieves performance comparable to frontier models such as Gemini 3.0 Pro. In downstream robot control experiments, we leverage our robust VLM foundation to train an effective Vision-Language-Action (VLA) model, achieving compelling results in real-world physical evaluations. Code and models are open-sourced at https://github.com/Tencent-Hunyuan/HY-Embodied.
Spatial-TTT: Streaming Visual-based Spatial Intelligence with Test-Time Training
Mar 12, 2026Humans perceive and understand real-world spaces through a stream of visual observations. Therefore, the ability to streamingly maintain and update spatial evidence from potentially unbounded video streams is essential for spatial intelligence. The core challenge is not simply longer context windows but how spatial information is selected, organized, and retained over time. In this paper, we propose Spatial-TTT towards streaming visual-based spatial intelligence with test-time training (TTT), which adapts a subset of parameters (fast weights) to capture and organize spatial evidence over long-horizon scene videos. Specifically, we design a hybrid architecture and adopt large-chunk updates parallel with sliding-window attention for efficient spatial video processing. To further promote spatial awareness, we introduce a spatial-predictive mechanism applied to TTT layers with 3D spatiotemporal convolution, which encourages the model to capture geometric correspondence and temporal continuity across frames. Beyond architecture design, we construct a dataset with dense 3D spatial descriptions, which guides the model to update its fast weights to memorize and organize global 3D spatial signals in a structured manner. Extensive experiments demonstrate that Spatial-TTT improves long-horizon spatial understanding and achieves state-of-the-art performance on video spatial benchmarks. Project page: https://liuff19.github.io/Spatial-TTT.
Vision Generalist Model: A Survey
Jun 11, 2025Recently, we have witnessed the great success of the generalist model in natural language processing. The generalist model is a general framework trained with massive data and is able to process various downstream tasks simultaneously. Encouraged by their impressive performance, an increasing number of researchers are venturing into the realm of applying these models to computer vision tasks. However, the inputs and outputs of vision tasks are more diverse, and it is difficult to summarize them as a unified representation. In this paper, we provide a comprehensive overview of the vision generalist models, delving into their characteristics and capabilities within the field. First, we review the background, including the datasets, tasks, and benchmarks. Then, we dig into the design of frameworks that have been proposed in existing research, while also introducing the techniques employed to enhance their performance. To better help the researchers comprehend the area, we take a brief excursion into related domains, shedding light on their interconnections and potential synergies. To conclude, we provide some real-world application scenarios, undertake a thorough examination of the persistent challenges, and offer insights into possible directions for future research endeavors.
XMask3D: Cross-modal Mask Reasoning for Open Vocabulary 3D Semantic Segmentation
Nov 20, 2024
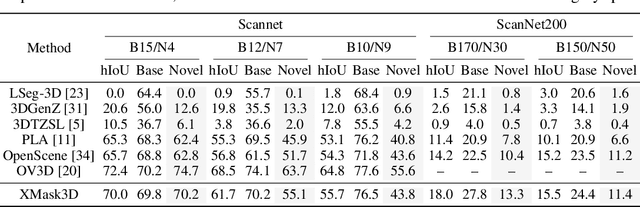


Existing methodologies in open vocabulary 3D semantic segmentation primarily concentrate on establishing a unified feature space encompassing 3D, 2D, and textual modalities. Nevertheless, traditional techniques such as global feature alignment or vision-language model distillation tend to impose only approximate correspondence, struggling notably with delineating fine-grained segmentation boundaries. To address this gap, we propose a more meticulous mask-level alignment between 3D features and the 2D-text embedding space through a cross-modal mask reasoning framework, XMask3D. In our approach, we developed a mask generator based on the denoising UNet from a pre-trained diffusion model, leveraging its capability for precise textual control over dense pixel representations and enhancing the open-world adaptability of the generated masks. We further integrate 3D global features as implicit conditions into the pre-trained 2D denoising UNet, enabling the generation of segmentation masks with additional 3D geometry awareness. Subsequently, the generated 2D masks are employed to align mask-level 3D representations with the vision-language feature space, thereby augmenting the open vocabulary capability of 3D geometry embeddings. Finally, we fuse complementary 2D and 3D mask features, resulting in competitive performance across multiple benchmarks for 3D open vocabulary semantic segmentation. Code is available at https://github.com/wangzy22/XMask3D.
FlowTurbo: Towards Real-time Flow-Based Image Generation with Velocity Refiner
Sep 26, 2024Building on the success of diffusion models in visual generation, flow-based models reemerge as another prominent family of generative models that have achieved competitive or better performance in terms of both visual quality and inference speed. By learning the velocity field through flow-matching, flow-based models tend to produce a straighter sampling trajectory, which is advantageous during the sampling process. However, unlike diffusion models for which fast samplers are well-developed, efficient sampling of flow-based generative models has been rarely explored. In this paper, we propose a framework called FlowTurbo to accelerate the sampling of flow-based models while still enhancing the sampling quality. Our primary observation is that the velocity predictor's outputs in the flow-based models will become stable during the sampling, enabling the estimation of velocity via a lightweight velocity refiner. Additionally, we introduce several techniques including a pseudo corrector and sample-aware compilation to further reduce inference time. Since FlowTurbo does not change the multi-step sampling paradigm, it can be effectively applied for various tasks such as image editing, inpainting, etc. By integrating FlowTurbo into different flow-based models, we obtain an acceleration ratio of 53.1%$\sim$58.3% on class-conditional generation and 29.8%$\sim$38.5% on text-to-image generation. Notably, FlowTurbo reaches an FID of 2.12 on ImageNet with 100 (ms / img) and FID of 3.93 with 38 (ms / img), achieving the real-time image generation and establishing the new state-of-the-art. Code is available at https://github.com/shiml20/FlowTurbo.
OpenVoice: Versatile Instant Voice Cloning
Dec 03, 2023
We introduce OpenVoice, a versatile voice cloning approach that requires only a short audio clip from the reference speaker to replicate their voice and generate speech in multiple languages. OpenVoice represents a significant advancement in addressing the following open challenges in the field: 1) Flexible Voice Style Control. OpenVoice enables granular control over voice styles, including emotion, accent, rhythm, pauses, and intonation, in addition to replicating the tone color of the reference speaker. The voice styles are not directly copied from and constrained by the style of the reference speaker. Previous approaches lacked the ability to flexibly manipulate voice styles after cloning. 2) Zero-Shot Cross-Lingual Voice Cloning. OpenVoice achieves zero-shot cross-lingual voice cloning for languages not included in the massive-speaker training set. Unlike previous approaches, which typically require extensive massive-speaker multi-lingual (MSML) dataset for all languages, OpenVoice can clone voices into a new language without any massive-speaker training data for that language. OpenVoice is also computationally efficient, costing tens of times less than commercially available APIs that offer even inferior performance. To foster further research in the field, we have made the source code and trained model publicly accessible. We also provide qualitative results in our demo website. Prior to its public release, our internal version of OpenVoice was used tens of millions of times by users worldwide between May and October 2023, serving as the backend of MyShell.ai.
Take-A-Photo: 3D-to-2D Generative Pre-training of Point Cloud Models
Jul 27, 2023



With the overwhelming trend of mask image modeling led by MAE, generative pre-training has shown a remarkable potential to boost the performance of fundamental models in 2D vision. However, in 3D vision, the over-reliance on Transformer-based backbones and the unordered nature of point clouds have restricted the further development of generative pre-training. In this paper, we propose a novel 3D-to-2D generative pre-training method that is adaptable to any point cloud model. We propose to generate view images from different instructed poses via the cross-attention mechanism as the pre-training scheme. Generating view images has more precise supervision than its point cloud counterpart, thus assisting 3D backbones to have a finer comprehension of the geometrical structure and stereoscopic relations of the point cloud. Experimental results have proved the superiority of our proposed 3D-to-2D generative pre-training over previous pre-training methods. Our method is also effective in boosting the performance of architecture-oriented approaches, achieving state-of-the-art performance when fine-tuning on ScanObjectNN classification and ShapeNetPart segmentation tasks. Code is available at https://github.com/wangzy22/TAP.
AdaPoinTr: Diverse Point Cloud Completion with Adaptive Geometry-Aware Transformers
Jan 11, 2023


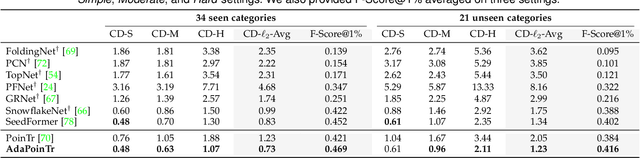
In this paper, we present a new method that reformulates point cloud completion as a set-to-set translation problem and design a new model, called PoinTr, which adopts a Transformer encoder-decoder architecture for point cloud completion. By representing the point cloud as a set of unordered groups of points with position embeddings, we convert the input data to a sequence of point proxies and employ the Transformers for generation. To facilitate Transformers to better leverage the inductive bias about 3D geometric structures of point clouds, we further devise a geometry-aware block that models the local geometric relationships explicitly. The migration of Transformers enables our model to better learn structural knowledge and preserve detailed information for point cloud completion. Taking a step towards more complicated and diverse situations, we further propose AdaPoinTr by developing an adaptive query generation mechanism and designing a novel denoising task during completing a point cloud. Coupling these two techniques enables us to train the model efficiently and effectively: we reduce training time (by 15x or more) and improve completion performance (over 20%). We also show our method can be extended to the scene-level point cloud completion scenario by designing a new geometry-enhanced semantic scene completion framework. Extensive experiments on the existing and newly-proposed datasets demonstrate the effectiveness of our method, which attains 6.53 CD on PCN, 0.81 CD on ShapeNet-55 and 0.392 MMD on real-world KITTI, surpassing other work by a large margin and establishing new state-of-the-arts on various benchmarks. Most notably, AdaPoinTr can achieve such promising performance with higher throughputs and fewer FLOPs compared with the previous best methods in practice. The code and datasets are available at https://github.com/yuxumin/PoinTr