 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised 3D Object Detection from Point Clouds
Paper and Code
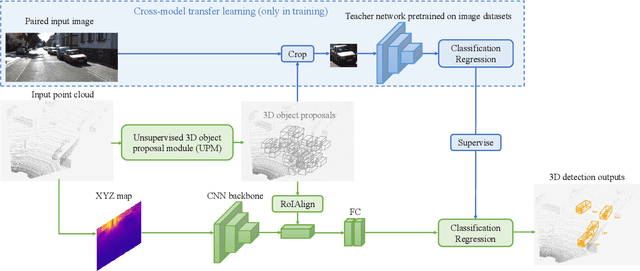
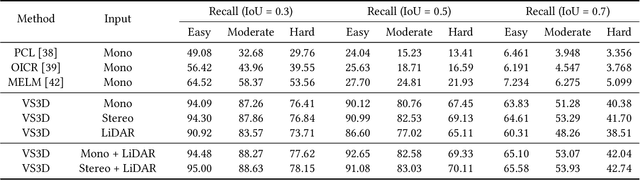
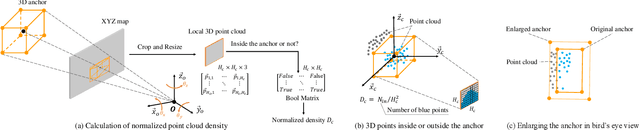
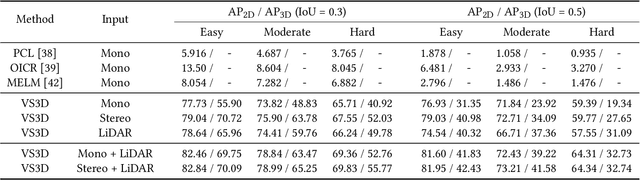
A crucial task in scene understanding is 3D object detection, which aims to detect and localize the 3D bounding boxes of objects belonging to specific classes. Existing 3D object detectors heavily rely on annotated 3D bounding boxes during training, while these annotations could be expensive to obtain and only accessible in limited scenarios. Weakly supervised learning is a promising approach to reducing the annotation requirement, but existing weakly supervised object detectors are mostly for 2D detection rather than 3D. In this work, we propose VS3D, a framework for weakly supervised 3D object detection from point clouds without using any ground truth 3D bounding box for training. First, we introduce an unsupervised 3D proposal module that generates object proposals by leveraging normalized point cloud densities. Second, we present a cross-modal knowledge distillation strategy, where a convolutional neural network learns to predict the final results from the 3D object proposals by querying a teacher network pretrained on image datasets. Comprehensive experiments on the challenging KITTI dataset demonstrate the superior performance of our VS3D in diverse evaluation settings. The source code and pretrained models are publicly available at https://github.com/Zengyi-Qin/Weakly-Supervised-3D-Object-Detection.