 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPM-TSE: A Diffusion Probabilistic Model for Target Sound Extraction
Paper and Code
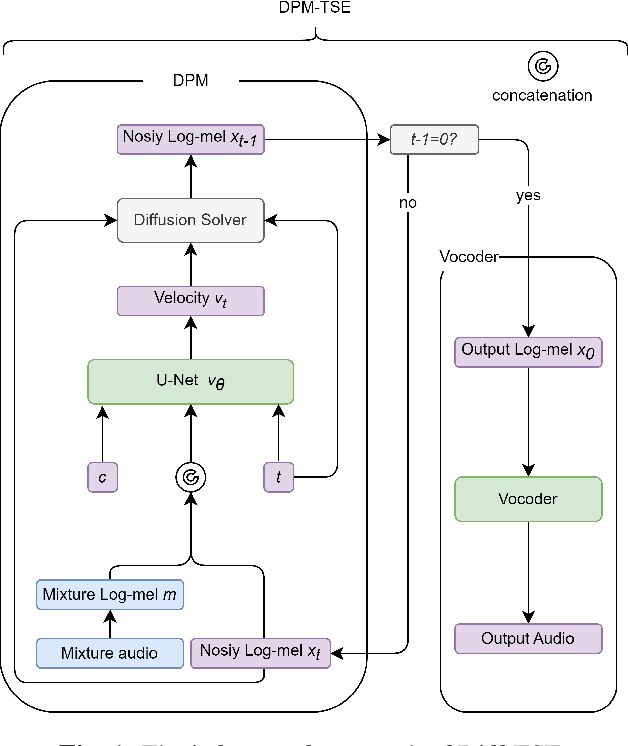
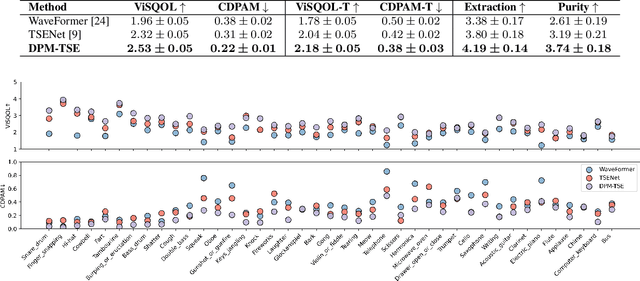

Common target sound extraction (TSE) approaches primarily relied on discriminative approaches in order to separate the target sound while minimizing interference from the unwanted sources, with varying success in separating the target from the background. This study introduces DPM-TSE, a first generative method based on diffusion probabilistic modeling (DPM) for target sound extraction, to achieve both cleaner target renderings as well as improved separability from unwanted sounds. The technique also tackles common background noise issues with DPM by introducing a correction method for noise schedules and sample steps. This approach is evaluated using both objective and subjective quality metrics on the FSD Kaggle 2018 dataset. The results show that DPM-TSE has a significant improvement in perceived quality in terms of target extraction and purity.