 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Model Hidden Representations for Heart Rate Estimation from Auscultation
May 29, 2025
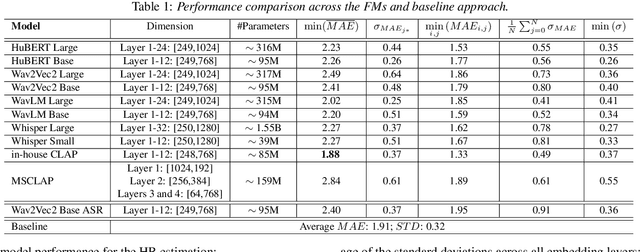
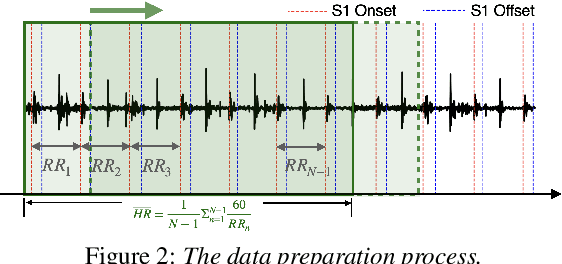
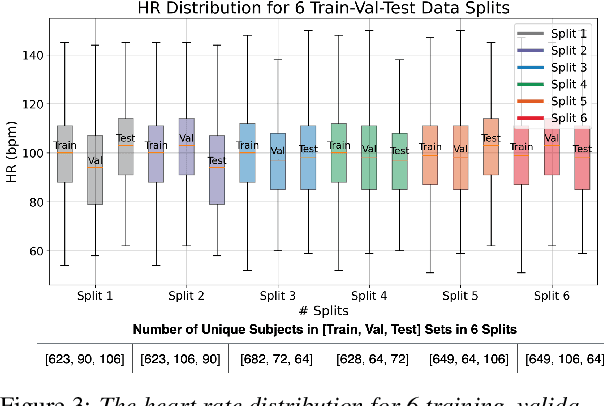
Auscultation, particularly heart sound, is a non-invasive technique that provides essential vital sign information. Recently, self-supervised acoustic representation foundation models (FMs) have been proposed to offer insights into acoustics-based vital signs. However, there has been little exploration of the extent to which auscultation is encoded in these pre-trained FM representations. In this work, using a publicly available phonocardiogram (PCG) dataset and a heart rate (HR) estimation model, we conduct a layer-wise investigation of six acoustic representation FMs: HuBERT, wav2vec2, wavLM, Whisper, Contrastive Language-Audio Pretraining (CLAP), and an in-house CLAP model. Additionally, we implement the baseline method from Nie et al., 2024 (which relies on acoustic features) and show that overall, representation vectors from pre-trained foundation models (FMs) offer comparable performance to the baseline. Notably, HR estimation using the representations from the audio encoder of the in-house CLAP model outperforms the results obtained from the baseline, achieving a lower mean absolute error (MAE) across various train/validation/test splits despite the domain mismatch.
Voice Quality Dimensions as Interpretable Primitives for Speaking Style for Atypical Speech and Affect
May 27, 2025



Perceptual voice quality dimensions describe key characteristics of atypical speech and other speech modulations. Here we develop and evaluate voice quality models for seven voice and speech dimensions (intelligibility, imprecise consonants, harsh voice, naturalness, monoloudness, monopitch, and breathiness). Probes were trained on the public Speech Accessibility (SAP) project dataset with 11,184 samples from 434 speakers, using embeddings from frozen pre-trained models as features. We found that our probes had both strong performance and strong generalization across speech elicitation categories in the SAP dataset. We further validated zero-shot performance on additional datasets, encompassing unseen languages and tasks: Italian atypical speech, English atypical speech, and affective speech. The strong zero-shot performance and the interpretability of results across an array of evaluations suggests the utility of using voice quality dimensions in speaking style-related tasks.
Learning to Detect Novel and Fine-Grained Acoustic Sequences Using Pretrained Audio Representations
May 03, 2023This work investigates pretrained audio representations for few shot Sound Event Detection. We specifically address the task of few shot detection of novel acoustic sequences, or sound events with semantically meaningful temporal structure, without assuming access to non-target audio. We develop procedures for pretraining suitable representations, and methods which transfer them to our few shot learning scenario. Our experiments evaluate the general purpose utility of our pretrained representations on AudioSet, and the utility of proposed few shot methods via tasks constructed from real-world acoustic sequences. Our pretrained embeddings are suitable to the proposed task, and enable multiple aspects of our few shot framework.
Pre-trained Model Representations and their Robustness against Noise for Speech Emotion Analysis
Mar 03, 2023
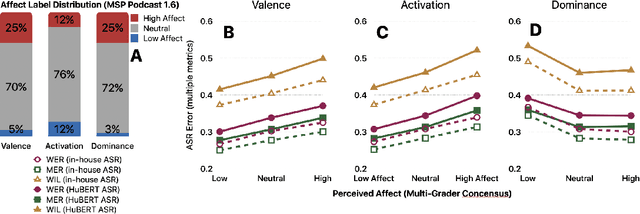
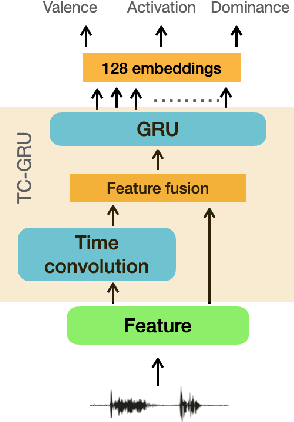

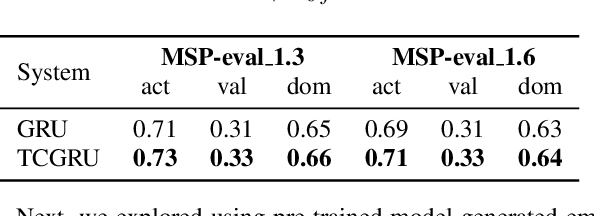
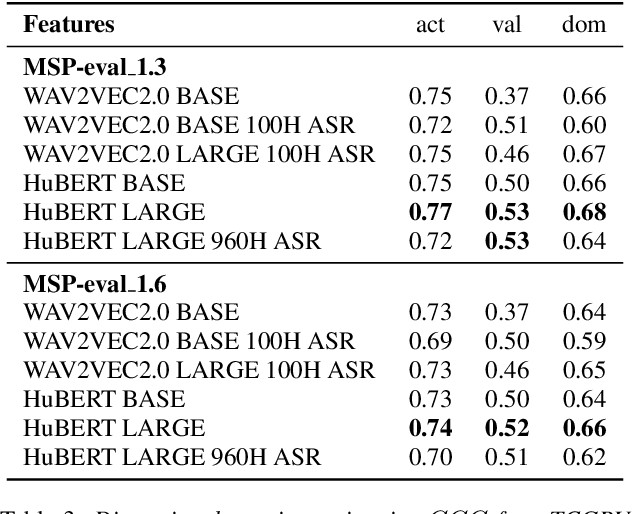
Pre-trained model representations have demonstrated state-of-the-art performance in speech recognition, natural language processing, and other applications. Speech models, such as Bidirectional Encoder Representations from Transformers (BERT) and Hidden units BERT (HuBERT), have enabled generating lexical and acoustic representations to benefit speech recognition applications. We investigated the use of pre-trained model representations for estimating dimensional emotions, such as activation, valence, and dominance, from speech. We observed that while valence may rely heavily on lexical representations, activation and dominance rely mostly on acoustic information. In this work, we used multi-modal fusion representations from pre-trained models to generate state-of-the-art speech emotion estimation, and we showed a 100% and 30% relative improvement in concordance correlation coefficient (CCC) on valence estimation compared to standard acoustic and lexical baselines. Finally, we investigated the robustness of pre-trained model representations against noise and reverberation degradation and noticed that lexical and acoustic representations are impacted differently. We discovered that lexical representations are more robust to distortions compared to acoustic representations, and demonstrated that knowledge distillation from a multi-modal model helps to improve the noise-robustness of acoustic-based models.
Speech Emotion: Investigating Model Representations, Multi-Task Learning and Knowledge Distillation
Jul 02, 2022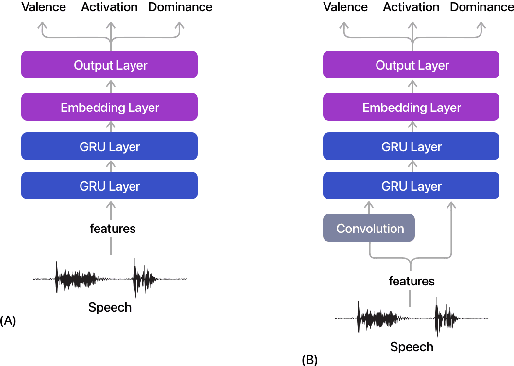
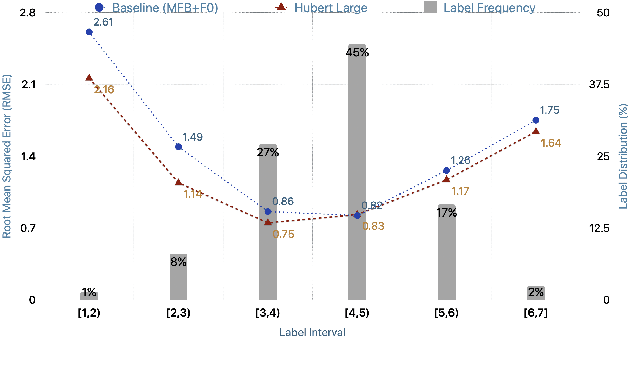
Estimating dimensional emotions, such as activation, valence and dominance, from acoustic speech signals has been widely explored over the past few years. While accurate estimation of activation and dominance from speech seem to be possible, the same for valence remains challenging. Previous research has shown that the use of lexical information can improve valence estimation performance. Lexical information can be obtained from pre-trained acoustic models, where the learned representations can improve valence estimation from speech. We investigate the use of pre-trained model representations to improve valence estimation from acoustic speech signal. We also explore fusion of representations to improve emotion estimation across all three emotion dimensions: activation, valence and dominance. Additionally, we investigate if representations from pre-trained models can be distilled into models trained with low-level features, resulting in models with a less number of parameters. We show that fusion of pre-trained model embeddings result in a 79% relative improvement in concordance correlation coefficient CCC on valence estimation compared to standard acoustic feature baseline (mel-filterbank energies), while distillation from pre-trained model embeddings to lower-dimensional representations yielded a relative 12% improvement. Such performance gains were observed over two evaluation sets, indicating that our proposed architecture generalizes across those evaluation sets. We report new state-of-the-art "text-free" acoustic-only dimensional emotion estimation $CCC$ values on two MSP-Podcast evaluation sets.
Detecting Emotion Primitives from Speech and their use in discerning Categorical Emotions
Jan 31, 2020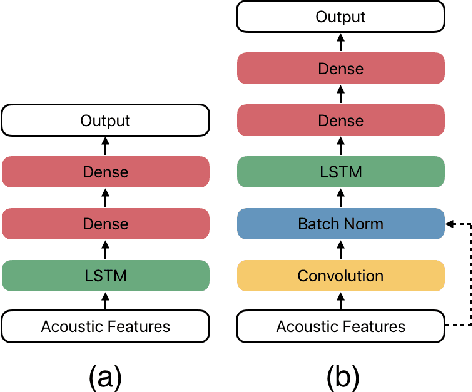
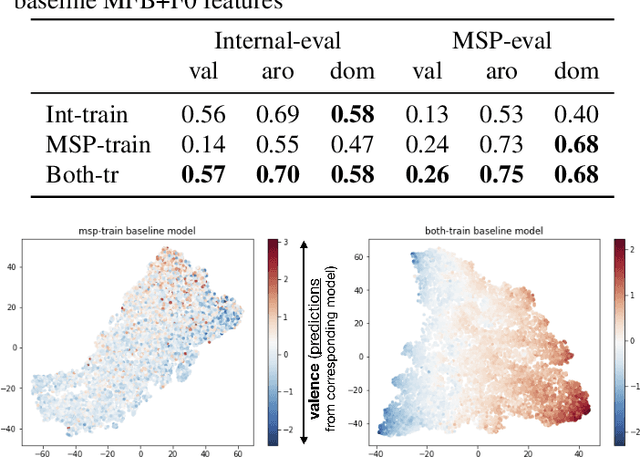
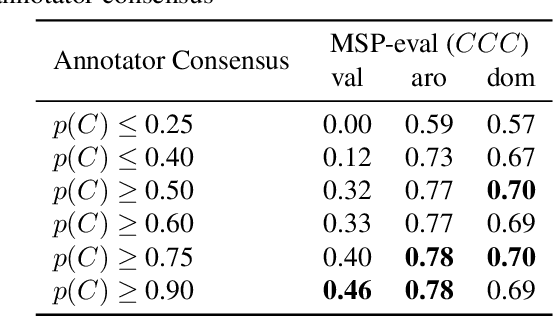

Emotion plays an essential role in human-to-human communication, enabling us to convey feelings such as happiness, frustration, and sincerity. While modern speech technologies rely heavily on speech recognition and natural language understanding for speech content understanding, the investigation of vocal expression is increasingly gaining attention. Key considerations for building robust emotion models include characterizing and improving the extent to which a model, given its training data distribution, is able to generalize to unseen data conditions. This work investigated a long-shot-term memory (LSTM) network and a time convolution - LSTM (TC-LSTM) to detect primitive emotion attributes such as valence, arousal, and dominance, from speech. It was observed that training with multiple datasets and using robust features improved the concordance correlation coefficient (CCC) for valence, by 30\% with respect to the baseline system. Additionally, this work investigated how emotion primitives can be used to detect categorical emotions such as happiness, disgust, contempt, anger, and surprise from neutral speech, and results indicated that arousal, followed by dominance was a better detector of such emotions.