 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Detecting Emotion Primitives from Speech and their use in discerning Categorical Emotions
Jan 31, 2020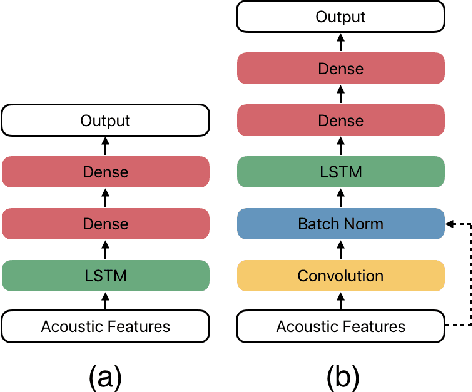
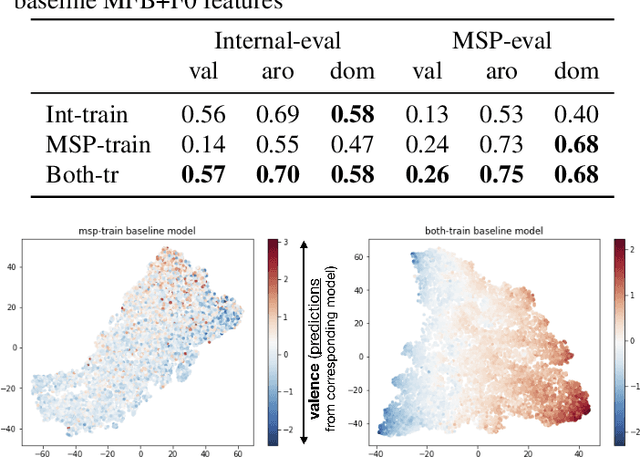
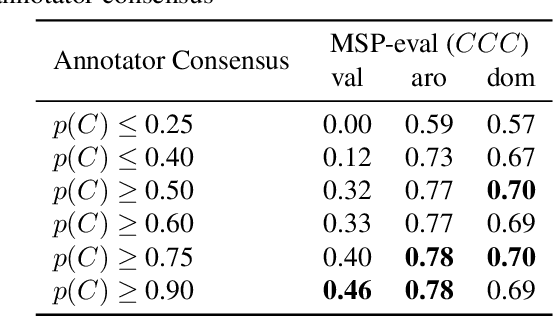

Emotion plays an essential role in human-to-human communication, enabling us to convey feelings such as happiness, frustration, and sincerity. While modern speech technologies rely heavily on speech recognition and natural language understanding for speech content understanding, the investigation of vocal expression is increasingly gaining attention. Key considerations for building robust emotion models include characterizing and improving the extent to which a model, given its training data distribution, is able to generalize to unseen data conditions. This work investigated a long-shot-term memory (LSTM) network and a time convolution - LSTM (TC-LSTM) to detect primitive emotion attributes such as valence, arousal, and dominance, from speech. It was observed that training with multiple datasets and using robust features improved the concordance correlation coefficient (CCC) for valence, by 30\% with respect to the baseline system. Additionally, this work investigated how emotion primitives can be used to detect categorical emotions such as happiness, disgust, contempt, anger, and surprise from neutral speech, and results indicated that arousal, followed by dominance was a better detector of such emotions.
Articulatory Features for ASR of Pathological Speech
Jul 28, 2018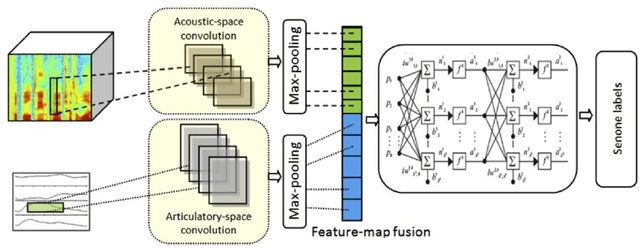
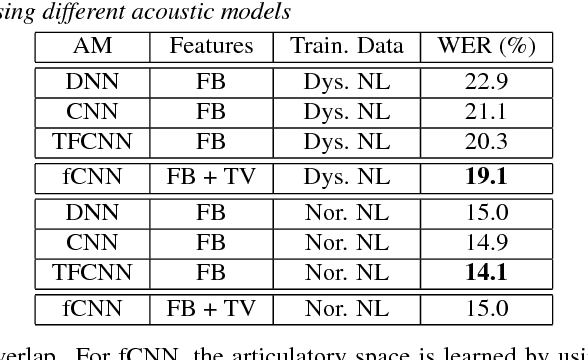
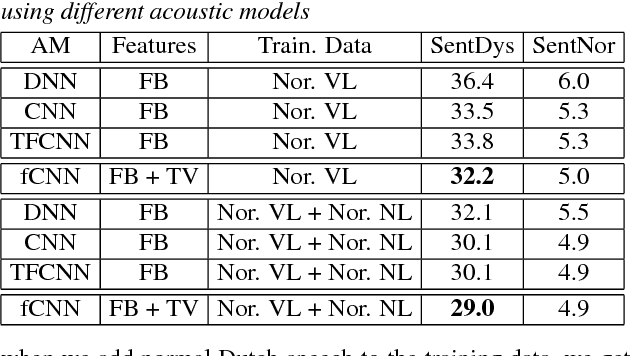
In this work, we investigate the joint use of articulatory and acoustic features for automatic speech recognition (ASR) of pathological speech. Despite long-lasting efforts to build speaker- and text-independent ASR systems for people with dysarthria, the performance of state-of-the-art systems is still considerably lower on this type of speech than on normal speech. The most prominent reason for the inferior performance is the high variability in pathological speech that is characterized by the spectrotemporal deviations caused by articulatory impairments due to various etiologies. To cope with this high variation, we propose to use speech representations which utilize articulatory information together with the acoustic properties. A designated acoustic model, namely a fused-feature-map convolutional neural network (fCNN), which performs frequency convolution on acoustic features and time convolution on articulatory features is trained and tested on a Dutch and a Flemish pathological speech corpus. The ASR performance of fCNN-based ASR system using joint features is compared to other neural network architectures such conventional CNNs and time-frequency convolutional networks (TFCNNs) in several training scenarios.
Articulatory information and Multiview Features for Large Vocabulary Continuous Speech Recognition
Feb 16, 2018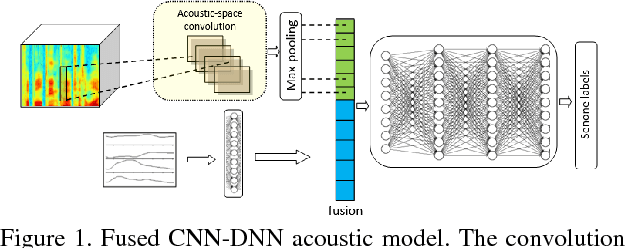
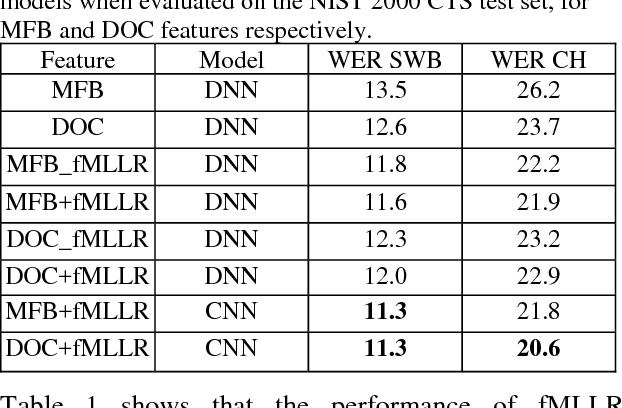
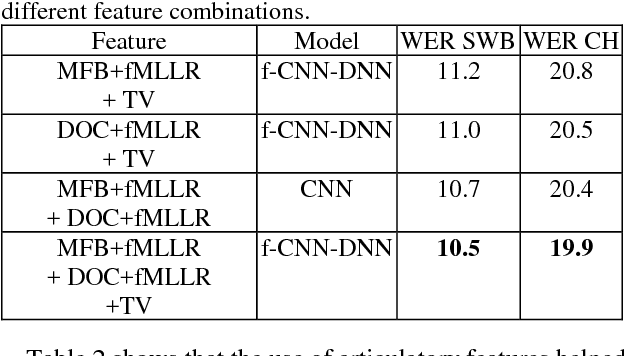
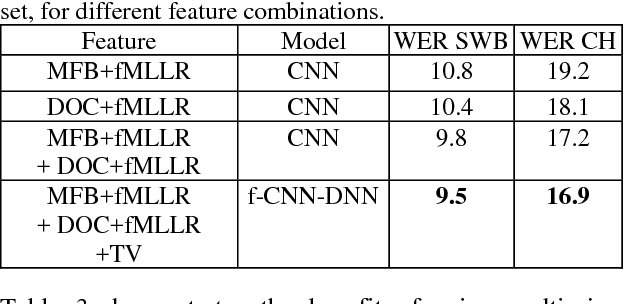
This paper explores the use of multi-view features and their discriminative transforms in a convolutional deep neural network (CNN) architecture for a continuous large vocabulary speech recognition task. Mel-filterbank energies and perceptually motivated forced damped oscillator coefficient (DOC) features are used after feature-space maximum-likelihood linear regression (fMLLR) transforms, which are combined and fed as a multi-view feature to a single CNN acoustic model. Use of multi-view feature representation demonstrated significant reduction in word error rates (WERs) compared to the use of individual features by themselves. In addition, when articulatory information was used as an additional input to a fused deep neural network (DNN) and CNN acoustic model, it was found to demonstrate further reduction in WER for the Switchboard subset and the CallHome subset (containing partly non-native accented speech) of the NIST 2000 conversational telephone speech test set, reducing the error rate by 12% relative to the baseline in both cases. This work shows that multi-view features in association with articulatory information can improve speech recognition robustness to spontaneous and non-native speech.
On Triangulating Dynamic Graphical Models
Oct 19, 2012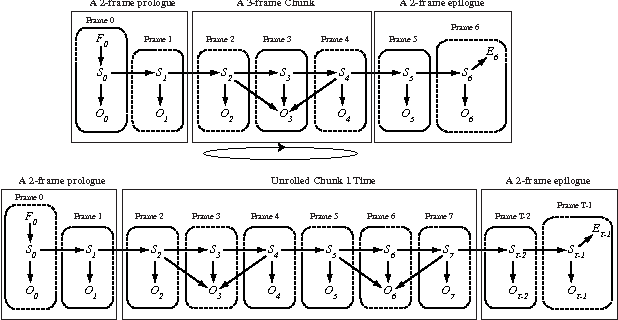
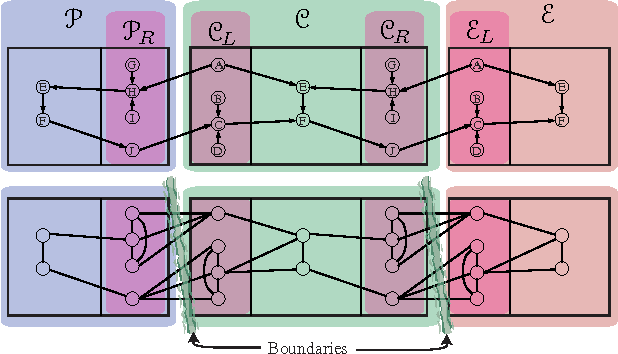
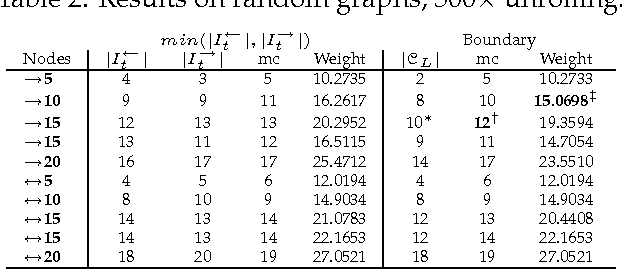
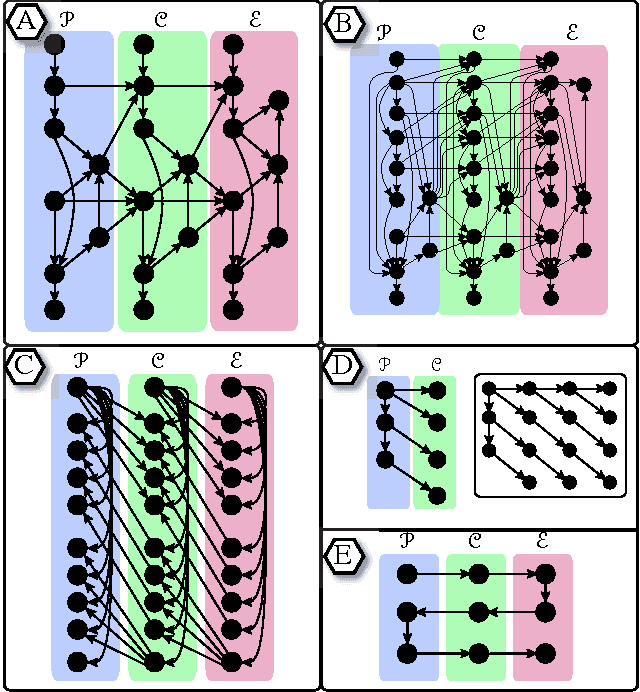
This paper introduces new methodology to triangulate dynamic Bayesian networks (DBNs) and dynamic graphical models (DGMs). While most methods to triangulate such networks use some form of constrained elimination scheme based on properties of the underlying directed graph, we find it useful to view triangulation and elimination using properties only of the resulting undirected graph, obtained after the moralization step. We first briefly introduce the Graphical model toolkit (GMTK) and its notion of dynamic graphical models, one that slightly extends the standard notion of a DBN. We next introduce the 'boundary algorithm', a method to find the best boundary between partitions in a dynamic model. We find that using this algorithm, the notions of forward- and backward-interface become moot - namely, the size and fill-in of the best forward- and backward- interface are identical. Moreover, we observe that finding a good partition boundary allows for constrained elimination orders (and therefore graph triangulations) that are not possible using standard slice-by-slice constrained eliminations. More interestingly, with certain boundaries it is possible to obtain constrained elimination schemes that lie outside the space of possible triangulations using only unconstrained elimination. Lastly, we report triangulation results on invented graphs, standard DBNs from the literature, novel DBNs used in speech recognition research systems, and also random graphs. Using a number of different triangulation quality measures (max clique size, state-space, etc.), we find that with our boundary algorithm the triangulation quality can dramatically improve.
Non-Minimal Triangulations for Mixed Stochastic/Deterministic Graphical Models
Jun 27, 2012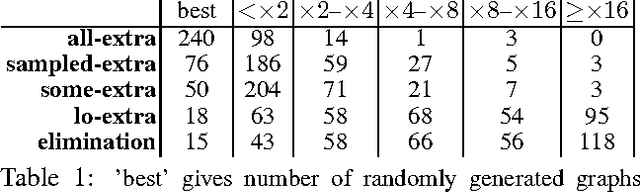
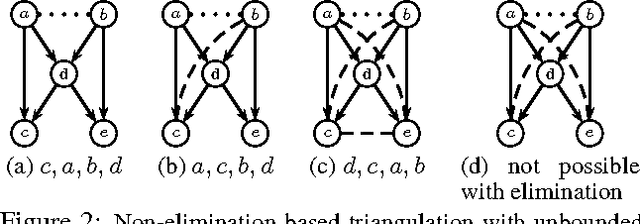

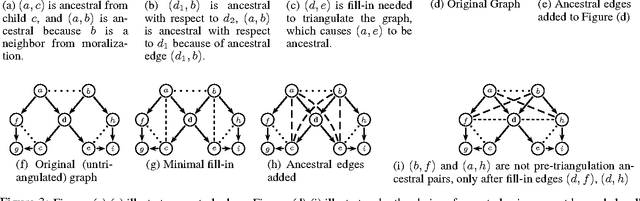
We observe that certain large-clique graph triangulations can be useful to reduce both computational and space requirements when making queries on mixed stochastic/deterministic graphical models. We demonstrate that many of these large-clique triangulations are non-minimal and are thus unattainable via the variable elimination algorithm. We introduce ancestral pairs as the basis for novel triangulation heuristics and prove that no more than the addition of edges between ancestral pairs need be considered when searching for state space optimal triangulations in such graphs. Empirical results on random and real world graphs show that the resulting triangulations that yield significant speedups are almost always non-minimal. We also give an algorithm and correctness proof for determining if a triangulation can be obtained via elimination, and we show that the decision problem associated with finding optimal state space triangulations in this mixed stochastic/deterministic setting is NP-complete.