 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulatory information and Multiview Features for Large Vocabulary Continuous Speech Recognition
Paper and Code
Feb 16, 2018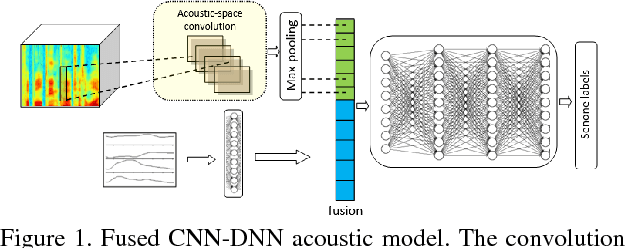
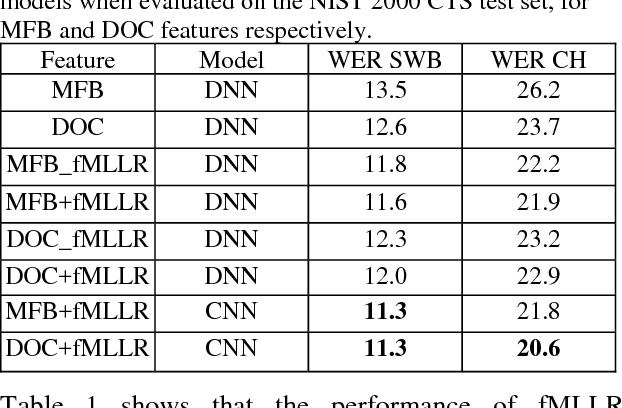
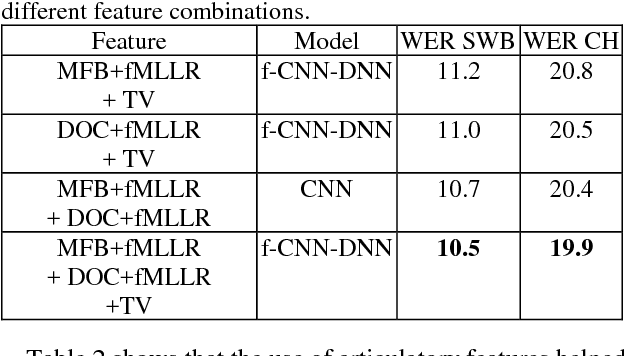
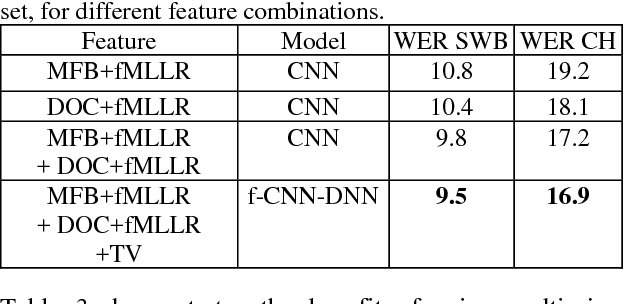
This paper explores the use of multi-view features and their discriminative transforms in a convolutional deep neural network (CNN) architecture for a continuous large vocabulary speech recognition task. Mel-filterbank energies and perceptually motivated forced damped oscillator coefficient (DOC) features are used after feature-space maximum-likelihood linear regression (fMLLR) transforms, which are combined and fed as a multi-view feature to a single CNN acoustic model. Use of multi-view feature representation demonstrated significant reduction in word error rates (WERs) compared to the use of individual features by themselves. In addition, when articulatory information was used as an additional input to a fused deep neural network (DNN) and CNN acoustic model, it was found to demonstrate further reduction in WER for the Switchboard subset and the CallHome subset (containing partly non-native accented speech) of the NIST 2000 conversational telephone speech test set, reducing the error rate by 12% relative to the baseline in both cases. This work shows that multi-view features in association with articulatory information can improve speech recognition robustness to spontaneous and non-native speech.