 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINDS: A Cross-cultural Dialogue Corpus for Social Norm Classification and Adherence Detection
Nov 13, 2025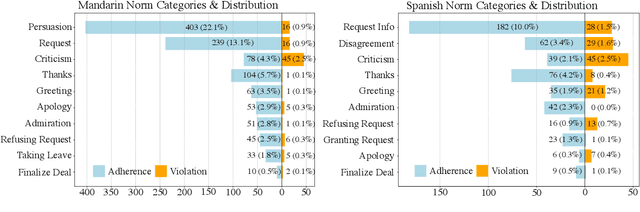
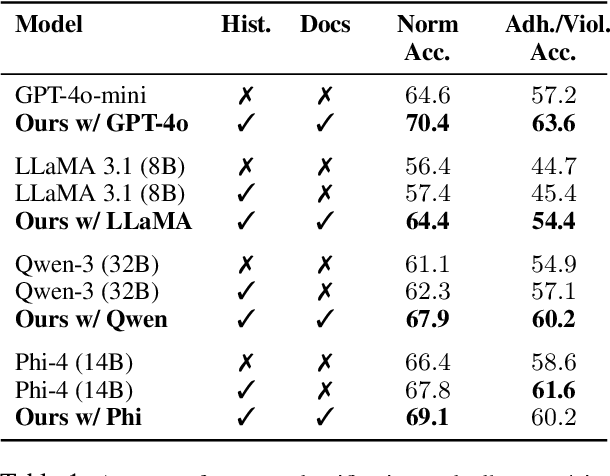
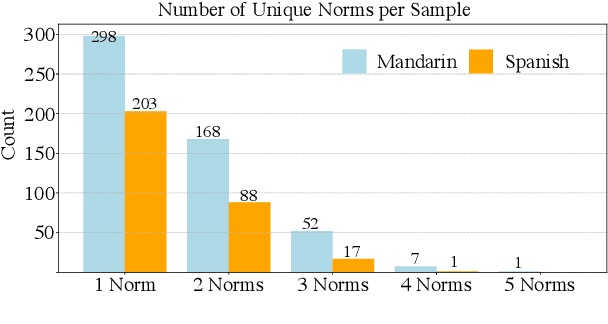
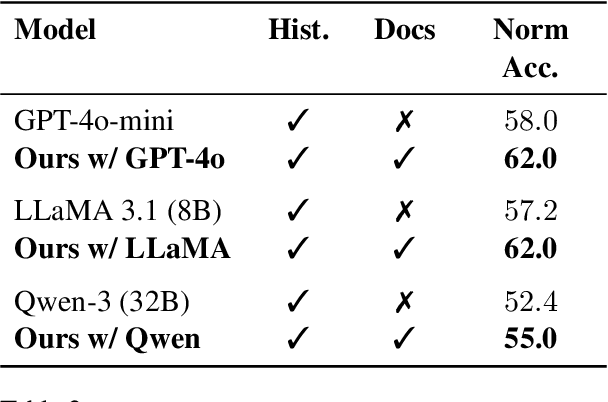
Social norms are implicit, culturally grounded expectations that guide interpersonal communication. Unlike factual commonsense, norm reasoning is subjective, context-dependent, and varies across cultures, posing challenges for computational models. Prior works provide valuable normative annotations but mostly target isolated utterances or synthetic dialogues, limiting their ability to capture the fluid, multi-turn nature of real-world conversations. In this work, we present Norm-RAG, a retrieval-augmented, agentic framework for nuanced social norm inference in multi-turn dialogues. Norm-RAG models utterance-level attributes including communicative intent, speaker roles, interpersonal framing, and linguistic cues and grounds them in structured normative documentation retrieved via a novel Semantic Chunking approach. This enables interpretable and context-aware reasoning about norm adherence and violation across multilingual dialogues. We further introduce MINDS (Multilingual Interactions with Norm-Driven Speech), a bilingual dataset comprising 31 multi-turn Mandarin-English and Spanish-English conversations. Each turn is annotated for norm category and adherence status using multi-annotator consensus, reflecting cross-cultural and realistic norm expression. Our experiments show that Norm-RAG improves norm detection and generalization, demonstrates improved performance for culturally adaptive and socially intelligent dialogue systems.
Demonstrations Are All You Need: Advancing Offensive Content Paraphrasing using In-Context Learning
Oct 16, 2023



Paraphrasing of offensive content is a better alternative to content removal and helps improve civility in a communication environment. Supervised paraphrasers; however, rely heavily on large quantities of labelled data to help preserve meaning and intent. They also retain a large portion of the offensiveness of the original content, which raises questions on their overall usability. In this paper we aim to assist practitioners in developing usable paraphrasers by exploring In-Context Learning (ICL) with large language models (LLMs), i.e., using a limited number of input-label demonstration pairs to guide the model in generating desired outputs for specific queries. Our study focuses on key factors such as -- number and order of demonstrations, exclusion of prompt instruction, and reduction in measured toxicity. We perform principled evaluation on three datasets, including our proposed Context-Aware Polite Paraphrase dataset, comprising of dialogue-style rude utterances, polite paraphrases, and additional dialogue context. We evaluate our approach using two closed source and one open source LLM. Our results reveal that ICL is comparable to supervised methods in generation quality, while being qualitatively better by 25% on human evaluation and attaining lower toxicity by 76%. Also, ICL-based paraphrasers only show a slight reduction in performance even with just 10% training data.
Zero-shot Multi-Domain Dialog State Tracking Using Descriptive Rules
Sep 17, 2020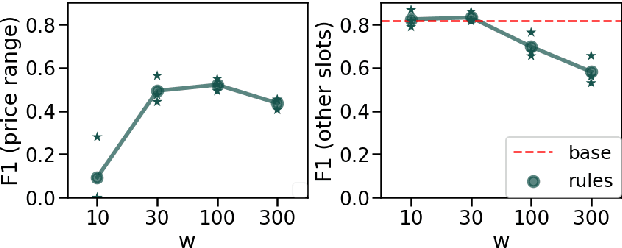
In this work, we present a framework for incorporating descriptive logical rules in state-of-the-art neural networks, enabling them to learn how to handle unseen labels without the introduction of any new training data. The rules are integrated into existing networks without modifying their architecture, through an additional term in the network's loss function that penalizes states of the network that do not obey the designed rules. As a case of study, the framework is applied to an existing neural-based Dialog State Tracker. Our experiments demonstrate that the inclusion of logical rules allows the prediction of unseen labels, without deteriorating the predictive capacity of the original system.
Articulatory information and Multiview Features for Large Vocabulary Continuous Speech Recognition
Feb 16, 2018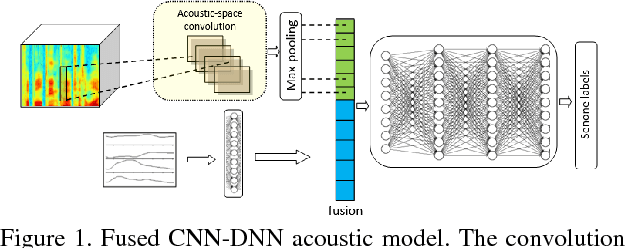
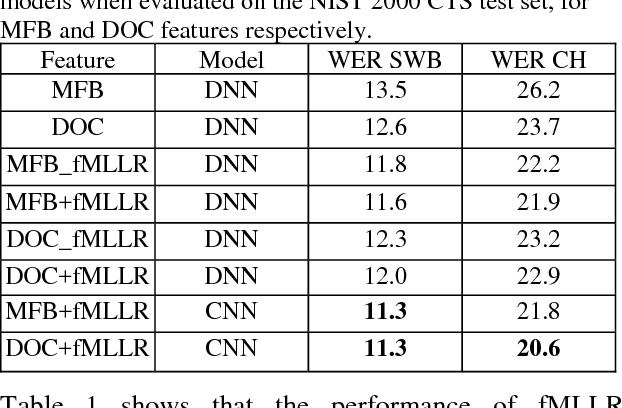
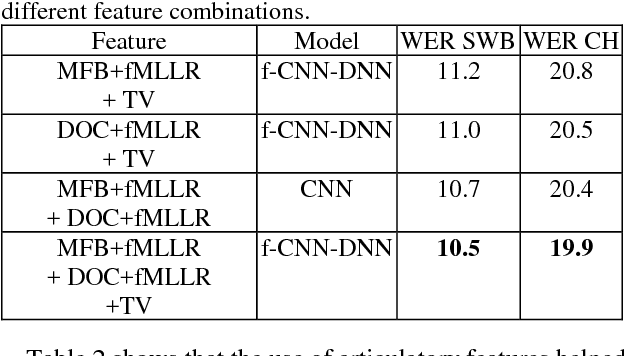
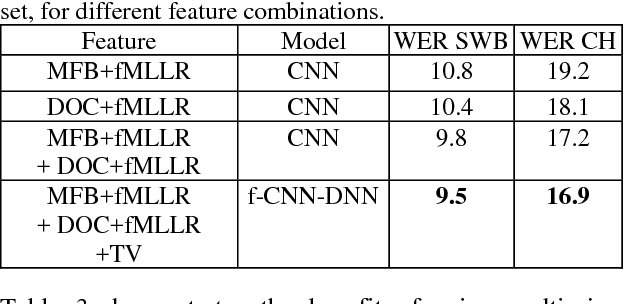
This paper explores the use of multi-view features and their discriminative transforms in a convolutional deep neural network (CNN) architecture for a continuous large vocabulary speech recognition task. Mel-filterbank energies and perceptually motivated forced damped oscillator coefficient (DOC) features are used after feature-space maximum-likelihood linear regression (fMLLR) transforms, which are combined and fed as a multi-view feature to a single CNN acoustic model. Use of multi-view feature representation demonstrated significant reduction in word error rates (WERs) compared to the use of individual features by themselves. In addition, when articulatory information was used as an additional input to a fused deep neural network (DNN) and CNN acoustic model, it was found to demonstrate further reduction in WER for the Switchboard subset and the CallHome subset (containing partly non-native accented speech) of the NIST 2000 conversational telephone speech test set, reducing the error rate by 12% relative to the baseline in both cases. This work shows that multi-view features in association with articulatory information can improve speech recognition robustness to spontaneous and non-native speech.