 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulatory Features for ASR of Pathological Speech
Paper and Code
Jul 28, 2018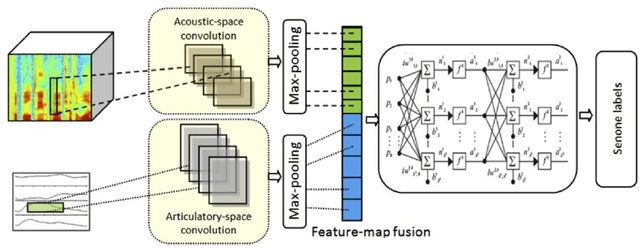
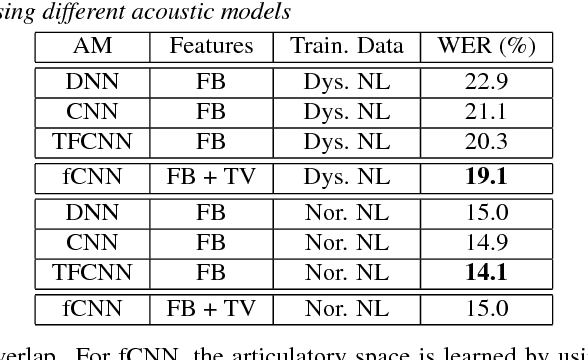
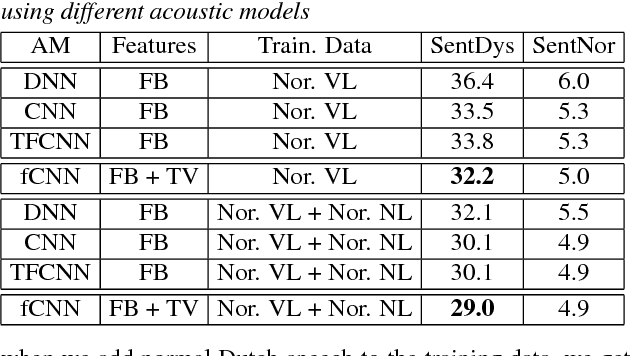
In this work, we investigate the joint use of articulatory and acoustic features for automatic speech recognition (ASR) of pathological speech. Despite long-lasting efforts to build speaker- and text-independent ASR systems for people with dysarthria, the performance of state-of-the-art systems is still considerably lower on this type of speech than on normal speech. The most prominent reason for the inferior performance is the high variability in pathological speech that is characterized by the spectrotemporal deviations caused by articulatory impairments due to various etiologies. To cope with this high variation, we propose to use speech representations which utilize articulatory information together with the acoustic properties. A designated acoustic model, namely a fused-feature-map convolutional neural network (fCNN), which performs frequency convolution on acoustic features and time convolution on articulatory features is trained and tested on a Dutch and a Flemish pathological speech corpus. The ASR performance of fCNN-based ASR system using joint features is compared to other neural network architectures such conventional CNNs and time-frequency convolutional networks (TFCNNs) in several training scenarios.