 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting Whisper for Improved Verbatim Transcription and End-to-end Miscue Detection
May 29, 2025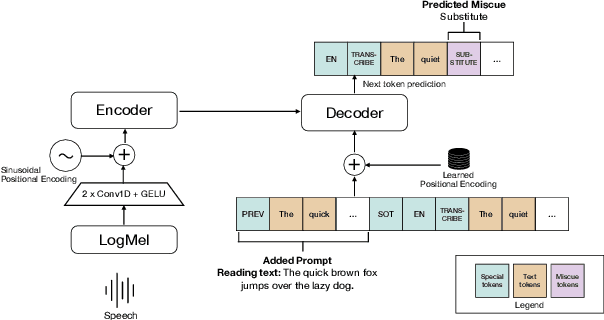



Identifying mistakes (i.e., miscues) made while reading aloud is commonly approached post-hoc by comparing automatic speech recognition (ASR) transcriptions to the target reading text. However, post-hoc methods perform poorly when ASR inaccurately transcribes verbatim speech. To improve on current methods for reading error annotation, we propose a novel end-to-end architecture that incorporates the target reading text via prompting and is trained for both improved verbatim transcription and direct miscue detection. Our contributions include: first, demonstrating that incorporating reading text through prompting benefits verbatim transcription performance over fine-tuning, and second, showing that it is feasible to augment speech recognition tasks for end-to-end miscue detection. We conducted two case studies -- children's read-aloud and adult atypical speech -- and found that our proposed strategies improve verbatim transcription and miscue detection compared to current state-of-the-art.
Voice Quality Dimensions as Interpretable Primitives for Speaking Style for Atypical Speech and Affect
May 27, 2025



Perceptual voice quality dimensions describe key characteristics of atypical speech and other speech modulations. Here we develop and evaluate voice quality models for seven voice and speech dimensions (intelligibility, imprecise consonants, harsh voice, naturalness, monoloudness, monopitch, and breathiness). Probes were trained on the public Speech Accessibility (SAP) project dataset with 11,184 samples from 434 speakers, using embeddings from frozen pre-trained models as features. We found that our probes had both strong performance and strong generalization across speech elicitation categories in the SAP dataset. We further validated zero-shot performance on additional datasets, encompassing unseen languages and tasks: Italian atypical speech, English atypical speech, and affective speech. The strong zero-shot performance and the interpretability of results across an array of evaluations suggests the utility of using voice quality dimensions in speaking style-related tasks.
Hypernetworks for Personalizing ASR to Atypical Speech
Jun 07, 2024Parameter-efficient fine-tuning (PEFT) for personalizing automatic speech recognition (ASR) has recently shown promise for adapting general population models to atypical speech. However, these approaches assume a priori knowledge of the atypical speech disorder being adapted for -- the diagnosis of which requires expert knowledge that is not always available. Even given this knowledge, data scarcity and high inter/intra-speaker variability further limit the effectiveness of traditional fine-tuning. To circumvent these challenges, we first identify the minimal set of model parameters required for ASR adaptation. Our analysis of each individual parameter's effect on adaptation performance allows us to reduce Word Error Rate (WER) by half while adapting 0.03% of all weights. Alleviating the need for cohort-specific models, we next propose the novel use of a meta-learned hypernetwork to generate highly individualized, utterance-level adaptations on-the-fly for a diverse set of atypical speech characteristics. Evaluating adaptation at the global, cohort and individual-level, we show that hypernetworks generalize better to out-of-distribution speakers, while maintaining an overall relative WER reduction of 75.2% using 0.1% of the full parameter budget.
Latent Phrase Matching for Dysarthric Speech
Jun 08, 2023



Many consumer speech recognition systems are not tuned for people with speech disabilities, resulting in poor recognition and user experience, especially for severe speech differences. Recent studies have emphasized interest in personalized speech models from people with atypical speech patterns. We propose a query-by-example-based personalized phrase recognition system that is trained using small amounts of speech, is language agnostic, does not assume a traditional pronunciation lexicon, and generalizes well across speech difference severities. On an internal dataset collected from 32 people with dysarthria, this approach works regardless of severity and shows a 60% improvement in recall relative to a commercial speech recognition system. On the public EasyCall dataset of dysarthric speech, our approach improves accuracy by 30.5%. Performance degrades as the number of phrases increases, but consistently outperforms ASR systems when trained with 50 unique phrases.