 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipette: Automatic Fine-grained Large Language Model Training Configurator for Real-World Clusters
Paper and Code
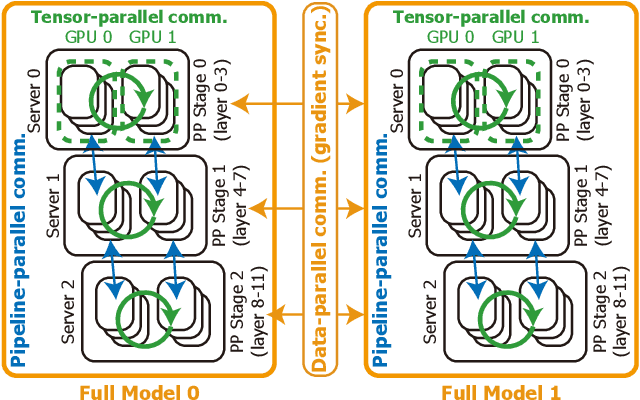
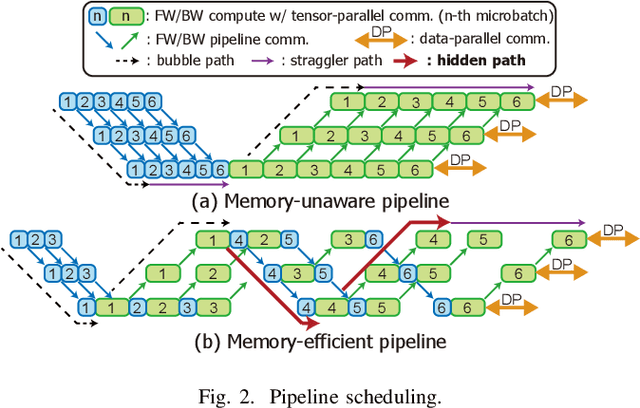
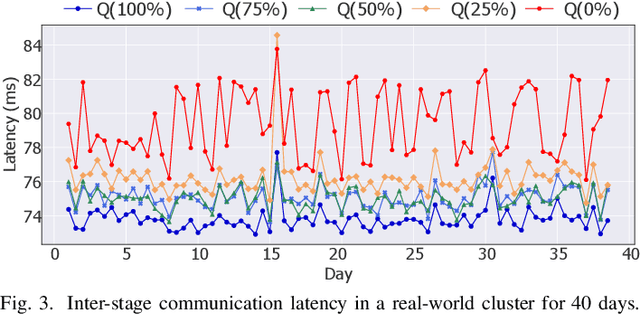
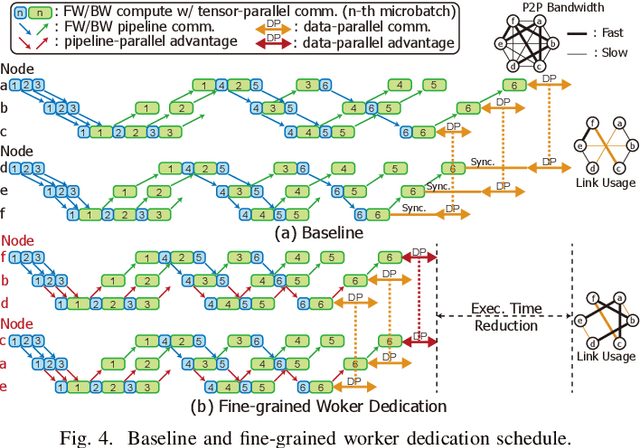
Training large language models (LLMs) is known to be challenging because of the huge computational and memory capacity requirements. To address these issues, it is common to use a cluster of GPUs with 3D parallelism, which splits a model along the data batch, pipeline stage, and intra-layer tensor dimensions. However, the use of 3D parallelism produces the additional challenge of finding the optimal number of ways on each dimension and mapping the split models onto the GPUs. Several previous studies have attempted to automatically find the optimal configuration, but many of these lacked several important aspects. For instance, the heterogeneous nature of the interconnect speeds is often ignored. While the peak bandwidths for the interconnects are usually made equal, the actual attained bandwidth varies per link in real-world clusters. Combined with the critical path modeling that does not properly consider the communication, they easily fall into sub-optimal configurations. In addition, they often fail to consider the memory requirement per GPU, often recommending solutions that could not be executed. To address these challenges, we propose Pipette, which is an automatic fine-grained LLM training configurator for real-world clusters. By devising better performance models along with the memory estimator and fine-grained individual GPU assignment, Pipette achieves faster configurations that satisfy the memory constraints. We evaluated Pipette on large clusters to show that it provides a significant speedup over the prior art. The implementation of Pipette is available at https://github.com/yimjinkyu1/date2024_pipette.