 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipette: Automatic Fine-grained Large Language Model Training Configurator for Real-World Clusters
May 28, 2024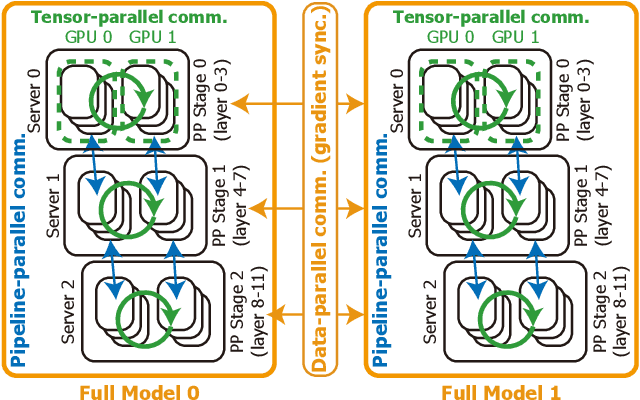
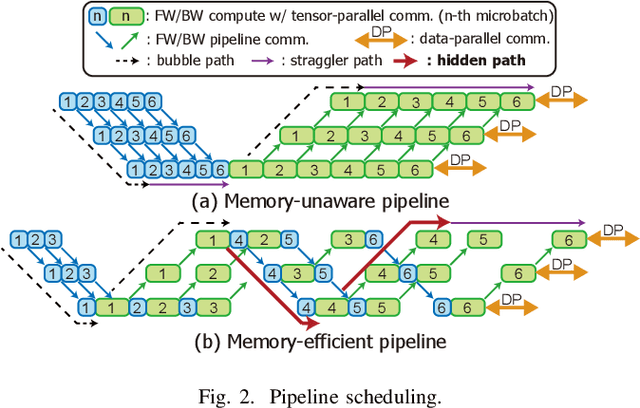
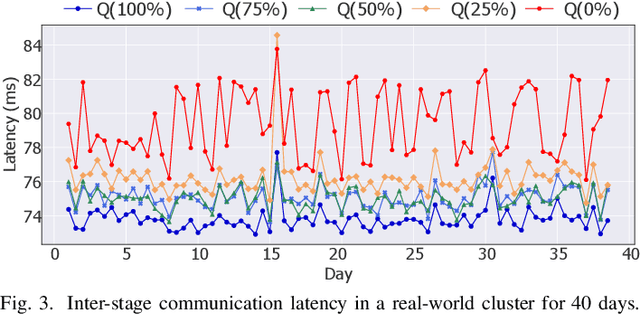
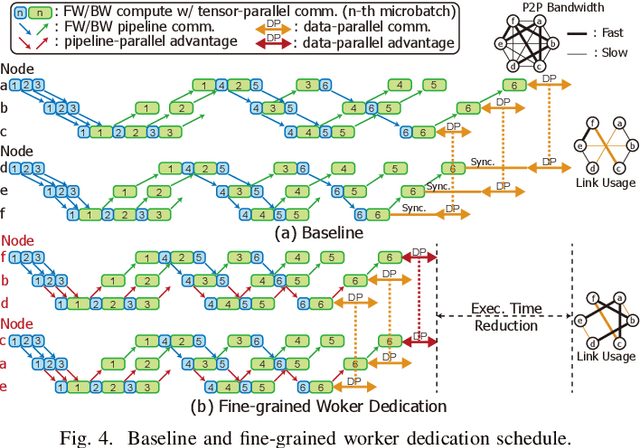
Training large language models (LLMs) is known to be challenging because of the huge computational and memory capacity requirements. To address these issues, it is common to use a cluster of GPUs with 3D parallelism, which splits a model along the data batch, pipeline stage, and intra-layer tensor dimensions. However, the use of 3D parallelism produces the additional challenge of finding the optimal number of ways on each dimension and mapping the split models onto the GPUs. Several previous studies have attempted to automatically find the optimal configuration, but many of these lacked several important aspects. For instance, the heterogeneous nature of the interconnect speeds is often ignored. While the peak bandwidths for the interconnects are usually made equal, the actual attained bandwidth varies per link in real-world clusters. Combined with the critical path modeling that does not properly consider the communication, they easily fall into sub-optimal configurations. In addition, they often fail to consider the memory requirement per GPU, often recommending solutions that could not be executed. To address these challenges, we propose Pipette, which is an automatic fine-grained LLM training configurator for real-world clusters. By devising better performance models along with the memory estimator and fine-grained individual GPU assignment, Pipette achieves faster configurations that satisfy the memory constraints. We evaluated Pipette on large clusters to show that it provides a significant speedup over the prior art. The implementation of Pipette is available at https://github.com/yimjinkyu1/date2024_pipette.
Optimus-CC: Efficient Large NLP Model Training with 3D Parallelism Aware Communication Compression
Jan 24, 2023



In training of modern large natural language processing (NLP) models, it has become a common practice to split models using 3D parallelism to multiple GPUs. Such technique, however, suffers from a high overhead of inter-node communication. Compressing the communication is one way to mitigate the overhead by reducing the inter-node traffic volume; however, the existing compression techniques have critical limitations to be applied for NLP models with 3D parallelism in that 1) only the data parallelism traffic is targeted, and 2) the existing compression schemes already harm the model quality too much. In this paper, we present Optimus-CC, a fast and scalable distributed training framework for large NLP models with aggressive communication compression. Optimus-CC differs from existing communication compression frameworks in the following ways: First, we compress pipeline parallel (inter-stage) traffic. In specific, we compress the inter-stage backpropagation and the embedding synchronization in addition to the existing data-parallel traffic compression methods. Second, we propose techniques to avoid the model quality drop that comes from the compression. We further provide mathematical and empirical analyses to show that our techniques can successfully suppress the compression error. Lastly, we analyze the pipeline and opt to selectively compress those traffic lying on the critical path. This further helps reduce the compression error. We demonstrate our solution on a GPU cluster, and achieve superior speedup from the baseline state-of-the-art solutions for distributed training without sacrificing the model quality.