 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipe-BD: Pipelined Parallel Blockwise Distillation
Paper and Code
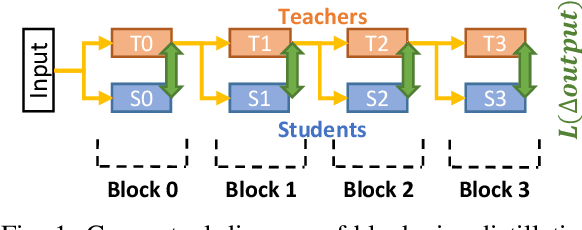
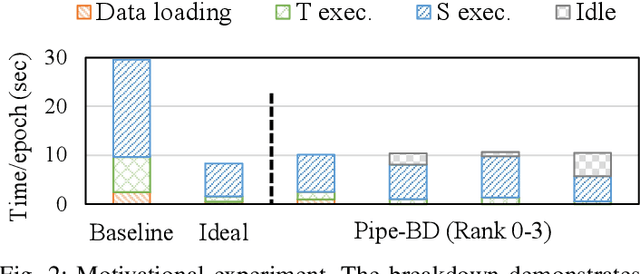
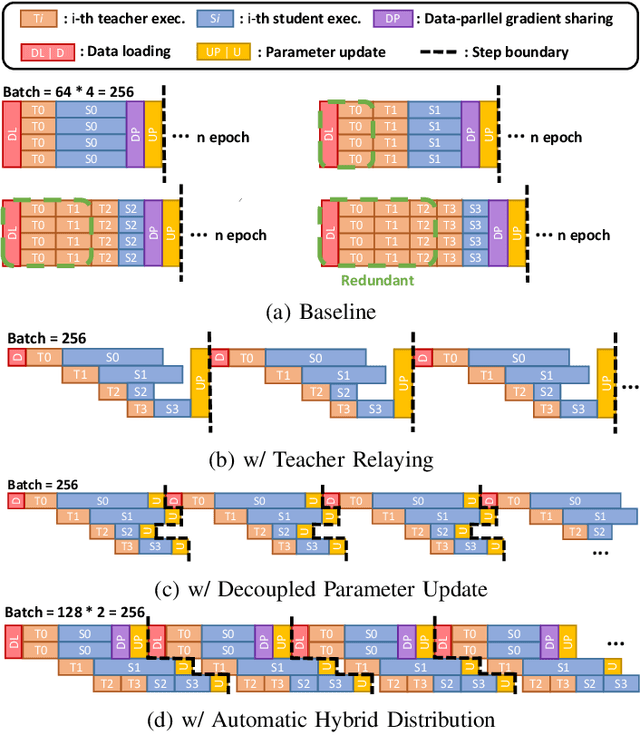
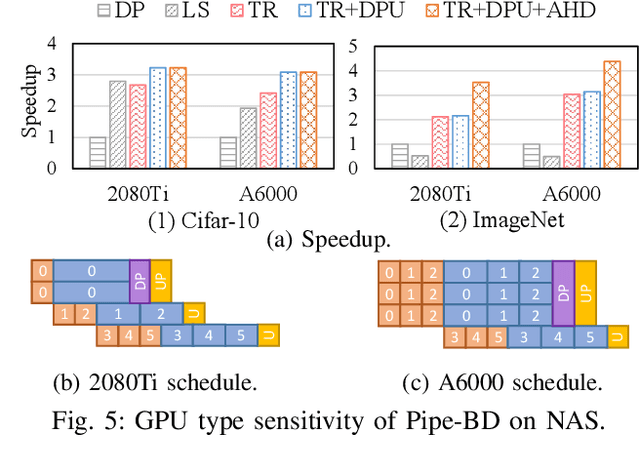
Training large deep neural network models is highly challenging due to their tremendous computational and memory requirements. Blockwise distillation provides one promising method towards faster convergence by splitting a large model into multiple smaller models. In state-of-the-art blockwise distillation methods, training is performed block-by-block in a data-parallel manner using multiple GPUs. To produce inputs for the student blocks, the teacher model is executed from the beginning until the current block under training. However, this results in a high overhead of redundant teacher execution, low GPU utilization, and extra data loading. To address these problems, we propose Pipe-BD, a novel parallelization method for blockwise distillation. Pipe-BD aggressively utilizes pipeline parallelism for blockwise distillation, eliminating redundant teacher block execution and increasing per-device batch size for better resource utilization. We also extend to hybrid parallelism for efficient workload balancing. As a result, Pipe-BD achieves significant acceleration without modifying the mathematical formulation of blockwise distillation. We implement Pipe-BD on PyTorch, and experiments reveal that Pipe-BD is effective on multiple scenarios, models, and datasets.