 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating automatically labeled data for author name disambiguation: An iterative clustering method
Feb 05, 2021

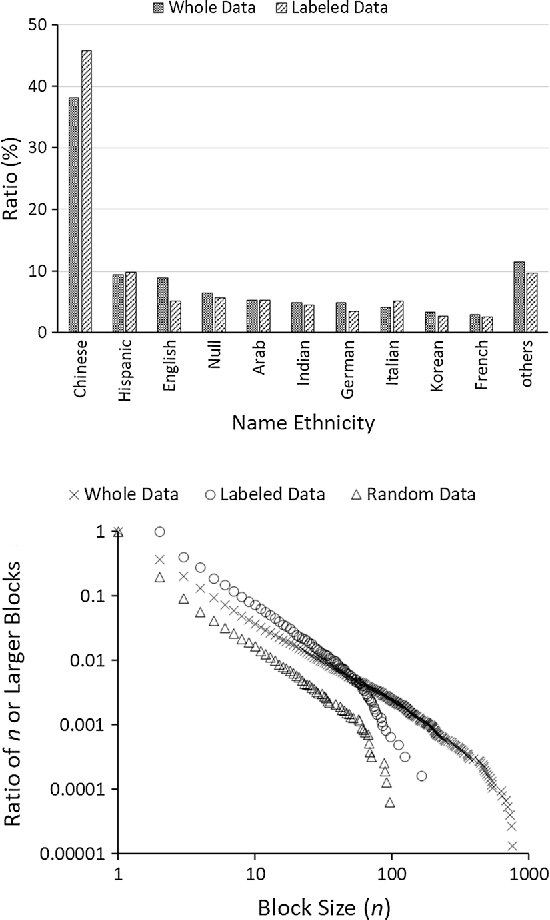

To train algorithms for supervised author name disambiguation, many studies have relied on hand-labeled truth data that are very laborious to generate. This paper shows that labeled training data can be automatically generated using information features such as email address, coauthor names, and cited references that are available from publication records. For this purpose, high-precision rules for matching name instances on each feature are decided using an external-authority database. Then, selected name instances in target ambiguous data go through the process of pairwise matching based on the rules. Next, they are merged into clusters by a generic entity resolution algorithm. The clustering procedure is repeated over other features until further merging is impossible. Tested on 26,566 instances out of the population of 228K author name instances, this iterative clustering produced accurately labeled data with pairwise F1 = 0.99. The labeled data represented the population data in terms of name ethnicity and co-disambiguating name group size distributions. In addition, trained on the labeled data, machine learning algorithms disambiguated 24K names in test data with performance of pairwise F1 = 0.90 ~ 0.92. Several challenges are discussed for applying this method to resolving author name ambiguity in large-scale scholarly data.
* 25 pages
ORCID-linked labeled data for evaluating author name disambiguation at scale
Feb 05, 2021
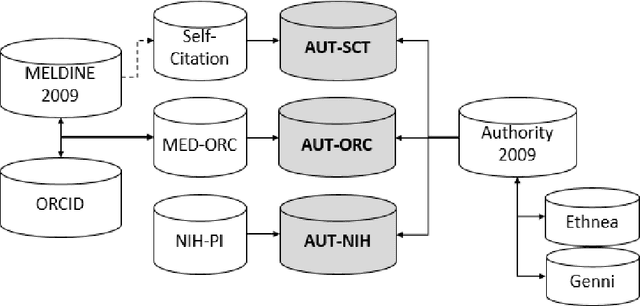

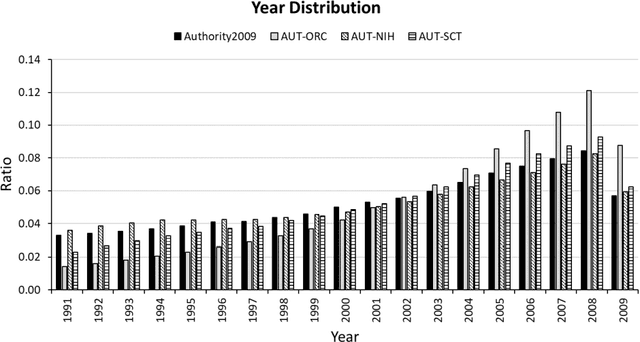
How can we evaluate the performance of a disambiguation method implemented on big bibliographic data? This study suggests that the open researcher profile system, ORCID, can be used as an authority source to label name instances at scale. This study demonstrates the potential by evaluating the disambiguation performances of Author-ity2009 (which algorithmically disambiguates author names in MEDLINE) using 3 million name instances that are automatically labeled through linkage to 5 million ORCID researcher profiles. Results show that although ORCID-linked labeled data do not effectively represent the population of name instances in Author-ity2009, they do effectively capture the 'high precision over high recall' performances of Author-ity2009. In addition, ORCID-linked labeled data can provide nuanced details about the Author-ity2009's performance when name instances are evaluated within and across ethnicity categories. As ORCID continues to be expanded to include more researchers, labeled data via ORCID-linkage can be improved in representing the population of a whole disambiguated data and updated on a regular basis. This can benefit author name disambiguation researchers and practitioners who need large-scale labeled data but lack resources for manual labeling or access to other authority sources for linkage-based labeling. The ORCID-linked labeled data for Author-tiy2009 are publicly available for validation and reuse.