 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogical Robots: Declarative Multi-Agent Programming in Logica
Apr 08, 2026We present Logical Robots, an interactive multi-agent simulation platform where autonomous robot behavior is specified declaratively in the logic programming language Logica. Robot behavior is defined by logical predicates that map observations from simulated radar arrays and shared memory to desired motor outputs. This approach allows low-level reactive control and high-level planning to coexist within a single programming environment, providing a coherent framework for exploring multi-agent robot behavior.
CRABS: A syntactic-semantic pincer strategy for bounding LLM interpretation of Python notebooks
Jul 15, 2025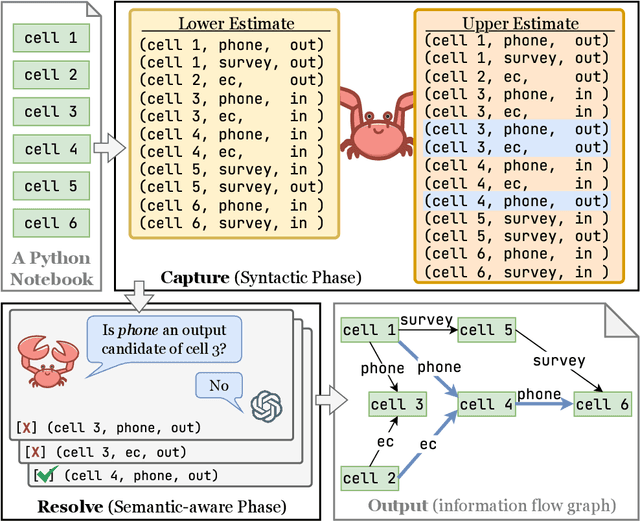



Recognizing the information flows and operations comprising data science and machine learning Python notebooks is critical for evaluating, reusing, and adapting notebooks for new tasks. Investigating a notebook via re-execution often is impractical due to the challenges of resolving data and software dependencies. While Large Language Models (LLMs) pre-trained on large codebases have demonstrated effectiveness in understanding code without running it, we observe that they fail to understand some realistic notebooks due to hallucinations and long-context challenges. To address these issues, we propose a notebook understanding task yielding an information flow graph and corresponding cell execution dependency graph for a notebook, and demonstrate the effectiveness of a pincer strategy that uses limited syntactic analysis to assist full comprehension of the notebook using an LLM. Our Capture and Resolve Assisted Bounding Strategy (CRABS) employs shallow syntactic parsing and analysis of the abstract syntax tree (AST) to capture the correct interpretation of a notebook between lower and upper estimates of the inter-cell I/O sets, then uses an LLM to resolve remaining ambiguities via cell-by-cell zero-shot learning, thereby identifying the true data inputs and outputs of each cell. We evaluate and demonstrate the effectiveness of our approach using an annotated dataset of 50 representative, highly up-voted Kaggle notebooks that together represent 3454 actual cell inputs and outputs. The LLM correctly resolves 1397 of 1425 (98%) ambiguities left by analyzing the syntactic structure of these notebooks. Across 50 notebooks, CRABS achieves average F1 scores of 98% identifying cell-to-cell information flows and 99% identifying transitive cell execution dependencies.
On the Structure of Game Provenance and its Applications
Oct 07, 2024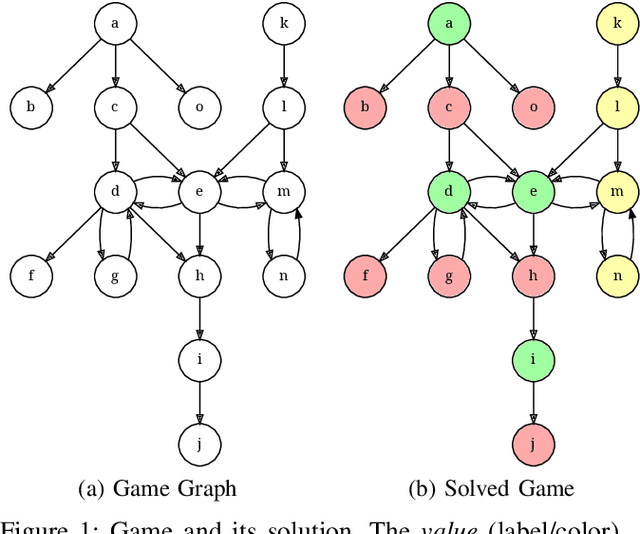
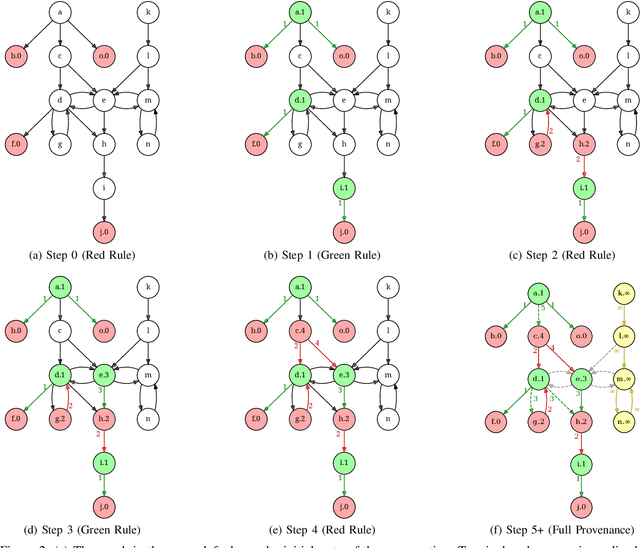
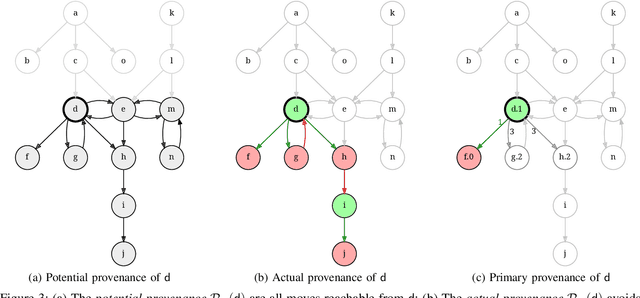
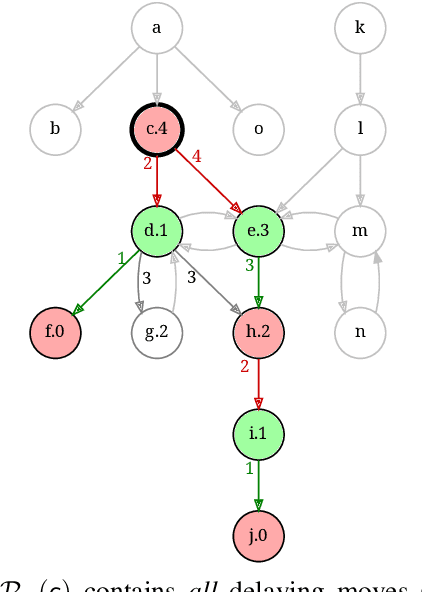
Provenance in databases has been thoroughly studied for positive and for recursive queries, then for first-order (FO) queries, i.e., having negation but no recursion. Query evaluation can be understood as a two-player game where the opponents argue whether or not a tuple is in the query answer. This game-theoretic approach yields a natural provenance model for FO queries, unifying how and why-not provenance. Here, we study the fine-grain structure of game provenance. A game $G=(V,E)$ consists of positions $V$ and moves $E$ and can be solved by computing the well-founded model of a single, unstratifiable rule: \[ \text{win}(X) \leftarrow \text{move}(X, Y), \neg \, \text{win}(Y). \] In the solved game $G^{\lambda}$, the value of a position $x\,{\in}\,V$ is either won, lost, or drawn. This value is explained by the provenance $\mathscr{P}$(x), i.e., certain (annotated) edges reachable from $x$. We identify seven edge types that give rise to new kinds of provenance, i.e., potential, actual, and primary, and demonstrate that "not all moves are created equal". We describe the new provenance types, show how they can be computed while solving games, and discuss applications, e.g., for abstract argumentation frameworks.
SciPrompt: Knowledge-augmented Prompting for Fine-grained Categorization of Scientific Topics
Oct 02, 2024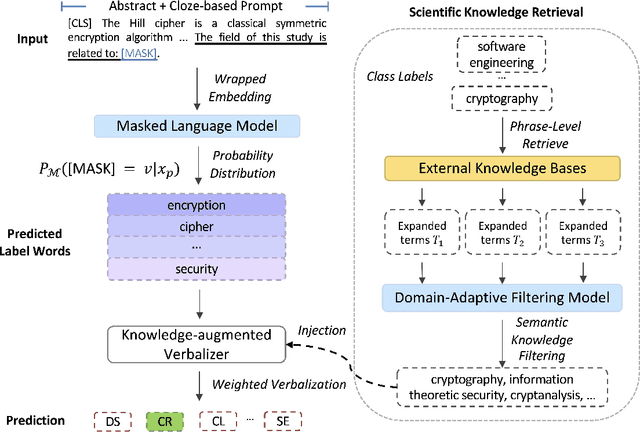
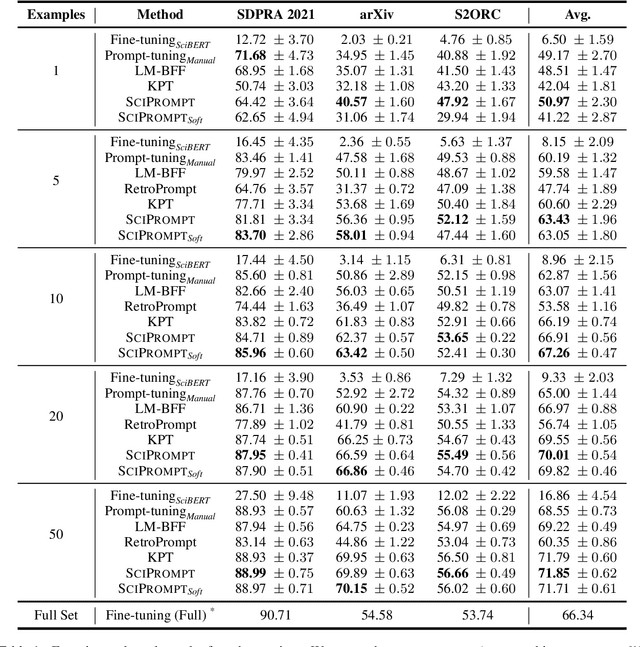
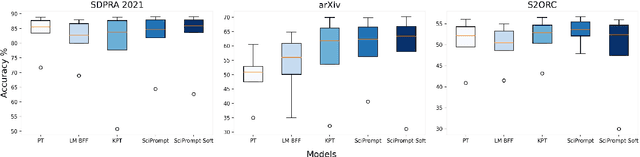
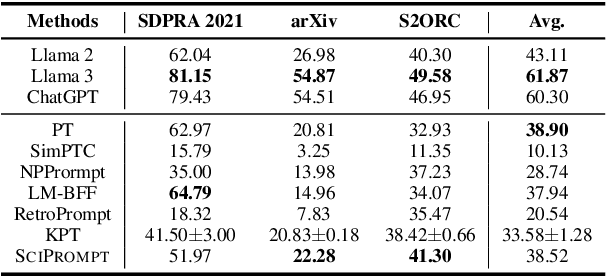
Prompt-based fine-tuning has become an essential method for eliciting information encoded in pre-trained language models for a variety of tasks, including text classification. For multi-class classification tasks, prompt-based fine-tuning under low-resource scenarios has resulted in performance levels comparable to those of fully fine-tuning methods. Previous studies have used crafted prompt templates and verbalizers, mapping from the label terms space to the class space, to solve the classification problem as a masked language modeling task. However, cross-domain and fine-grained prompt-based fine-tuning with an automatically enriched verbalizer remains unexplored, mainly due to the difficulty and costs of manually selecting domain label terms for the verbalizer, which requires humans with domain expertise. To address this challenge, we introduce SciPrompt, a framework designed to automatically retrieve scientific topic-related terms for low-resource text classification tasks. To this end, we select semantically correlated and domain-specific label terms within the context of scientific literature for verbalizer augmentation. Furthermore, we propose a new verbalization strategy that uses correlation scores as additional weights to enhance the prediction performance of the language model during model tuning. Our method outperforms state-of-the-art, prompt-based fine-tuning methods on scientific text classification tasks under few and zero-shot settings, especially in classifying fine-grained and emerging scientific topics.
KAER: A Knowledge Augmented Pre-Trained Language Model for Entity Resolution
Jan 12, 2023Entity resolution has been an essential and well-studied task in data cleaning research for decades. Existing work has discussed the feasibility of utilizing pre-trained language models to perform entity resolution and achieved promising results. However, few works have discussed injecting domain knowledge to improve the performance of pre-trained language models on entity resolution tasks. In this study, we propose Knowledge Augmented Entity Resolution (KAER), a novel framework named for augmenting pre-trained language models with external knowledge for entity resolution. We discuss the results of utilizing different knowledge augmentation and prompting methods to improve entity resolution performance. Our model improves on Ditto, the existing state-of-the-art entity resolution method. In particular, 1) KAER performs more robustly and achieves better results on "dirty data", and 2) with more general knowledge injection, KAER outperforms the existing baseline models on the textual dataset and dataset from the online product domain. 3) KAER achieves competitive results on highly domain-specific datasets, such as citation datasets, requiring the injection of expert knowledge in future work.