 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLPStatTest: A Toolkit for Comparing NLP System Performance
Paper and Code
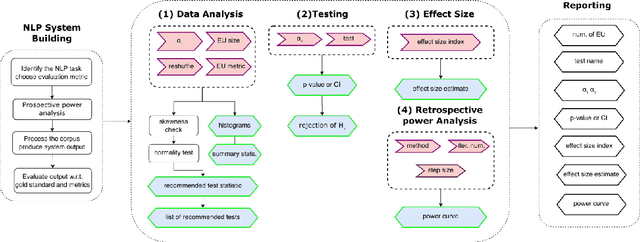
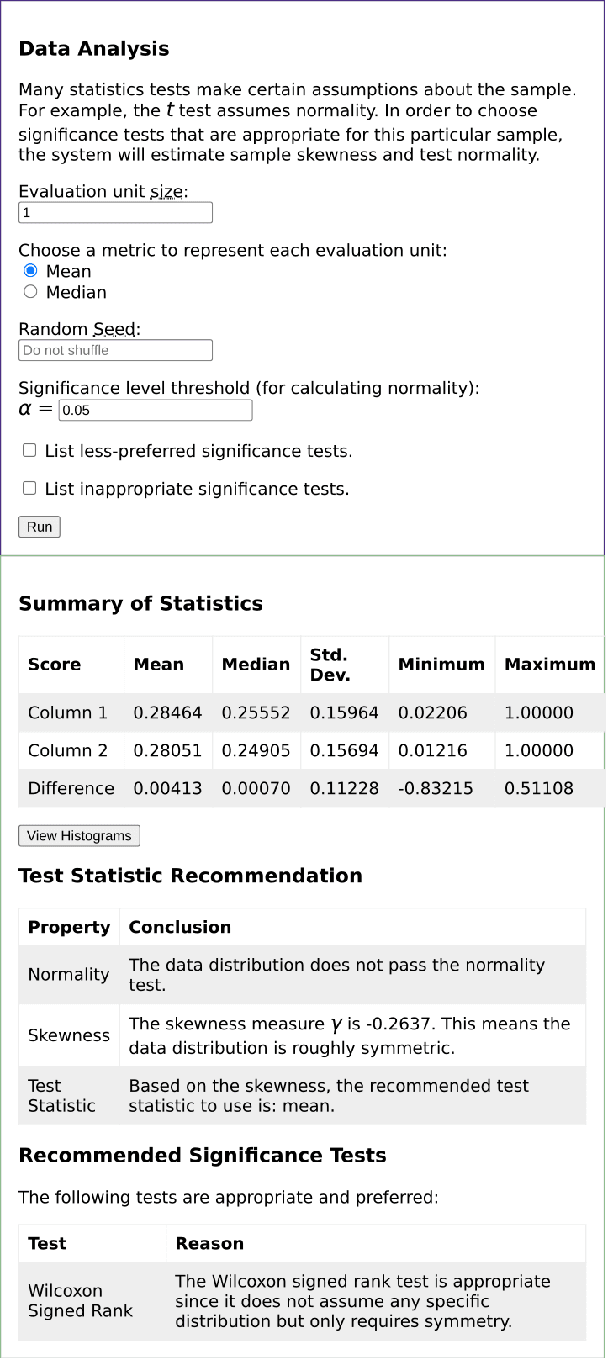
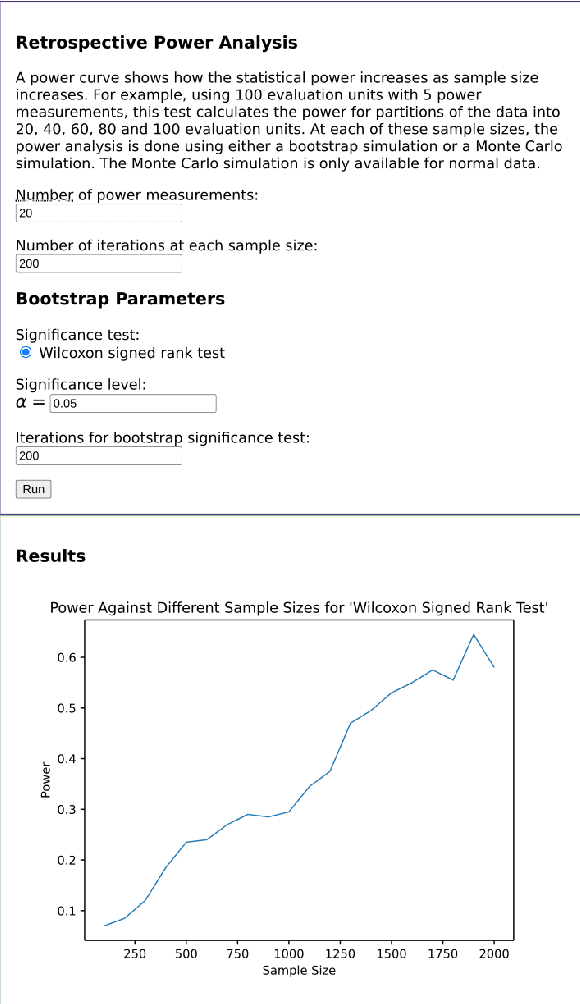
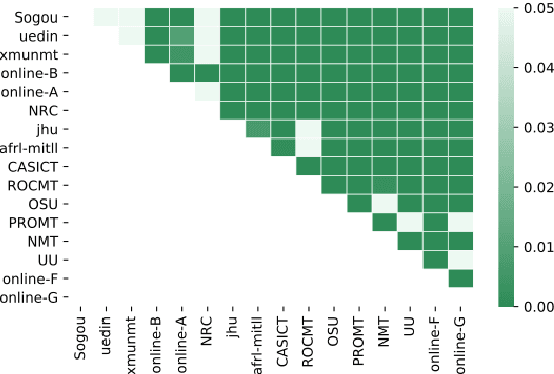
Statistical significance testing centered on p-values is commonly used to compare NLP system performance, but p-values alone are insufficient because statistical significance differs from practical significance. The latter can be measured by estimating effect size. In this paper, we propose a three-stage procedure for comparing NLP system performance and provide a toolkit, NLPStatTest, that automates the process. Users can upload NLP system evaluation scores and the toolkit will analyze these scores, run appropriate significance tests, estimate effect size, and conduct power analysis to estimate Type II error. The toolkit provides a convenient and systematic way to compare NLP system performance that goes beyond statistical significance testing