 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning for Smart and Energy-Efficient Buildings
Nov 27, 2022Energy consumption in buildings, both residential and commercial, accounts for approximately 40% of all energy usage in the U.S., and similar numbers are being reported from countries around the world. This significant amount of energy is used to maintain a comfortable, secure, and productive environment for the occupants. So, it is crucial that the energy consumption in buildings must be optimized, all the while maintaining satisfactory levels of occupant comfort, health, and safety. Recently, Machine Learning has been proven to be an invaluable tool in deriving important insights from data and optimizing various systems. In this work, we review the ways in which machine learning has been leveraged to make buildings smart and energy-efficient. For the convenience of readers, we provide a brief introduction of several machine learning paradigms and the components and functioning of each smart building system we cover. Finally, we discuss challenges faced while implementing machine learning algorithms in smart buildings and provide future avenues for research at the intersection of smart buildings and machine learning.
Personalized Federated Hypernetworks for Privacy Preservation in Multi-Task Reinforcement Learning
Oct 19, 2022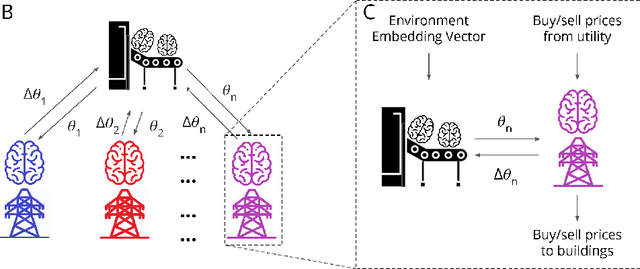
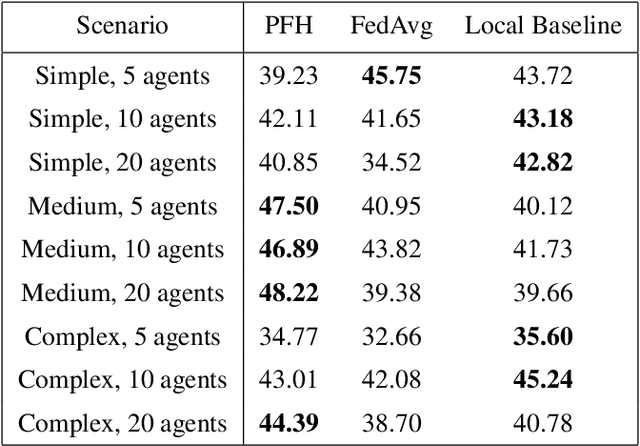
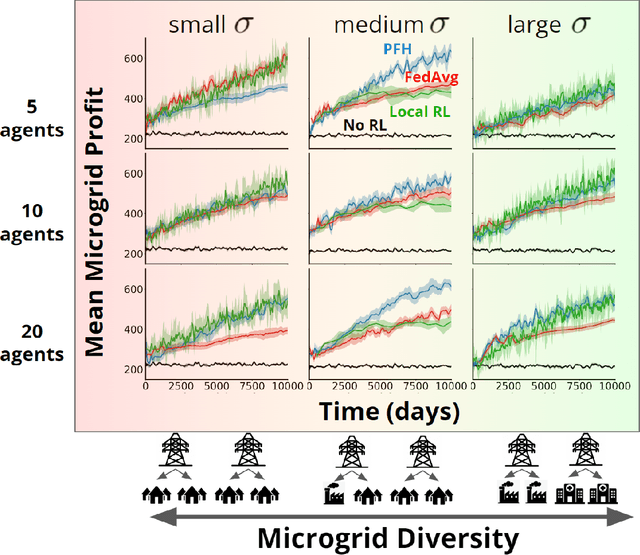
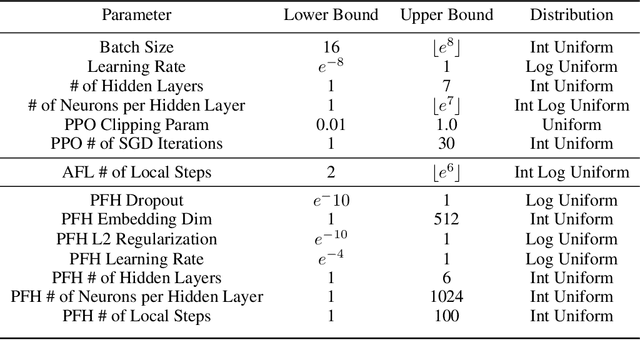
Multi-Agent Reinforcement Learning currently focuses on implementations where all data and training can be centralized to one machine. But what if local agents are split across multiple tasks, and need to keep data private between each? We develop the first application of Personalized Federated Hypernetworks (PFH) to Reinforcement Learning (RL). We then present a novel application of PFH to few-shot transfer, and demonstrate significant initial increases in learning. PFH has never been demonstrated beyond supervised learning benchmarks, so we apply PFH to an important domain: RL price-setting for energy demand response. We consider a general case across where agents are split across multiple microgrids, wherein energy consumption data must be kept private within each microgrid. Together, our work explores how the fields of personalized federated learning and RL can come together to make learning efficient across multiple tasks while keeping data secure.
Conditional Synthetic Data Generation for Personal Thermal Comfort Models
Mar 10, 2022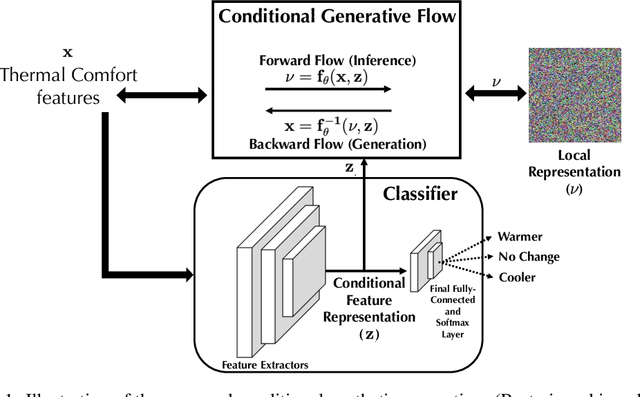

Personal thermal comfort models aim to predict an individual's thermal comfort response, instead of the average response of a large group. Recently, machine learning algorithms have proven to be having enormous potential as a candidate for personal thermal comfort models. But, often within the normal settings of a building, personal thermal comfort data obtained via experiments are heavily class-imbalanced. There are a disproportionately high number of data samples for the "Prefer No Change" class, as compared with the "Prefer Warmer" and "Prefer Cooler" classes. Machine learning algorithms trained on such class-imbalanced data perform sub-optimally when deployed in the real world. To develop robust machine learning-based applications using the above class-imbalanced data, as well as for privacy-preserving data sharing, we propose to implement a state-of-the-art conditional synthetic data generator to generate synthetic data corresponding to the low-frequency classes. Via experiments, we show that the synthetic data generated has a distribution that mimics the real data distribution. The proposed method can be extended for use by other smart building datasets/use-cases.
Conditional Synthetic Data Generation for Robust Machine Learning Applications with Limited Pandemic Data
Sep 14, 2021

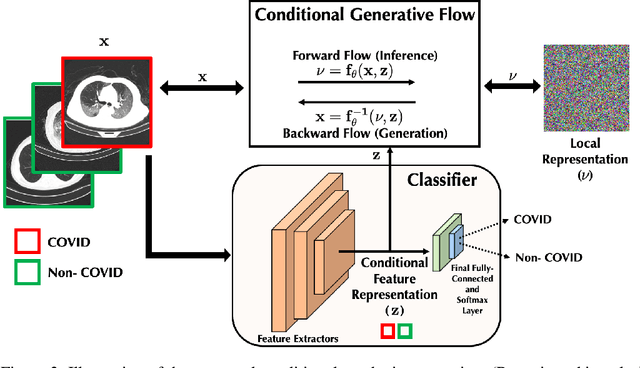
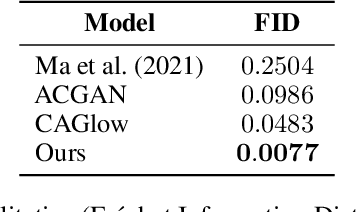
$\textbf{Background:}$ At the onset of a pandemic, such as COVID-19, data with proper labeling/attributes corresponding to the new disease might be unavailable or sparse. Machine Learning (ML) models trained with the available data, which is limited in quantity and poor in diversity, will often be biased and inaccurate. At the same time, ML algorithms designed to fight pandemics must have good performance and be developed in a time-sensitive manner. To tackle the challenges of limited data, and label scarcity in the available data, we propose generating conditional synthetic data, to be used alongside real data for developing robust ML models. $\textbf{Methods:}$ We present a hybrid model consisting of a conditional generative flow and a classifier for conditional synthetic data generation. The classifier decouples the feature representation for the condition, which is fed to the flow to extract the local noise. We generate synthetic data by manipulating the local noise with fixed conditional feature representation. We also propose a semi-supervised approach to generate synthetic samples in the absence of labels for a majority of the available data. $\textbf{Results:}$ We performed conditional synthetic generation for chest computed tomography (CT) scans corresponding to normal, COVID-19, and pneumonia afflicted patients. We show that our method significantly outperforms existing models both on qualitative and quantitative performance, and our semi-supervised approach can efficiently synthesize conditional samples under label scarcity. As an example of downstream use of synthetic data, we show improvement in COVID-19 detection from CT scans with conditional synthetic data augmentation.
CDCGen: Cross-Domain Conditional Generation via Normalizing Flows and Adversarial Training
Aug 25, 2021
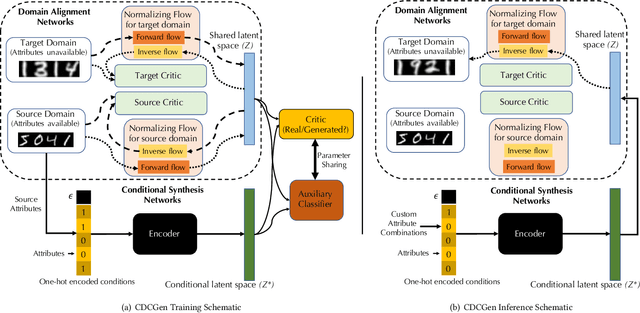


How to generate conditional synthetic data for a domain without utilizing information about its labels/attributes? Our work presents a solution to the above question. We propose a transfer learning-based framework utilizing normalizing flows, coupled with both maximum-likelihood and adversarial training. We model a source domain (labels available) and a target domain (labels unavailable) with individual normalizing flows, and perform domain alignment to a common latent space using adversarial discriminators. Due to the invertible property of flow models, the mapping has exact cycle consistency. We also learn the joint distribution of the data samples and attributes in the source domain by employing an encoder to map attributes to the latent space via adversarial training. During the synthesis phase, given any combination of attributes, our method can generate synthetic samples conditioned on them in the target domain. Empirical studies confirm the effectiveness of our method on benchmarked datasets. We envision our method to be particularly useful for synthetic data generation in label-scarce systems by generating non-trivial augmentations via attribute transformations. These synthetic samples will introduce more entropy into the label-scarce domain than their geometric and photometric transformation counterparts, helpful for robust downstream tasks.
Design, Benchmarking and Explainability Analysis of a Game-Theoretic Framework towards Energy Efficiency in Smart Infrastructure
Oct 16, 2019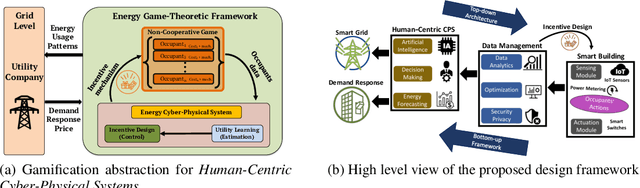
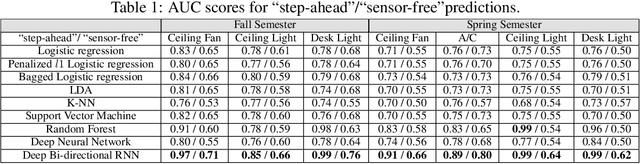
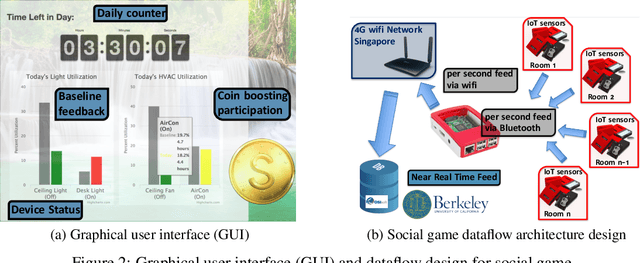
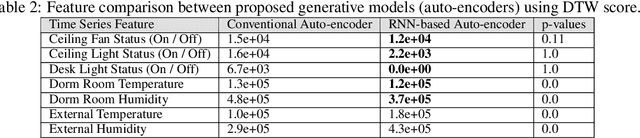
In this paper, we propose a gamification approach as a novel framework for smart building infrastructure with the goal of motivating human occupants to reconsider personal energy usage and to have positive effects on their environment. Human interaction in the context of cyber-physical systems is a core component and consideration in the implementation of any smart building technology. Research has shown that the adoption of human-centric building services and amenities leads to improvements in the operational efficiency of these cyber-physical systems directed towards controlling building energy usage. We introduce a strategy in form of a game-theoretic framework that incorporates humans-in-the-loop modeling by creating an interface to allow building managers to interact with occupants and potentially incentivize energy efficient behavior. Prior works on game theoretic analysis typically rely on the assumption that the utility function of each individual agent is known a priori. Instead, we propose novel utility learning framework for benchmarking that employs robust estimations of occupant actions towards energy efficiency. To improve forecasting performance, we extend the utility learning scheme by leveraging deep bi-directional recurrent neural networks. Using the proposed methods on data gathered from occupant actions for resources such as room lighting, we forecast patterns of energy resource usage to demonstrate the prediction performance of the methods. The results of our study show that we can achieve a highly accurate representation of the ground truth for occupant energy resource usage. We also demonstrate the explainable nature on human decision making towards energy usage inherent in the dataset using graphical lasso and granger causality algorithms. Finally, we open source the de-identified, high-dimensional data pertaining to the energy game-theoretic framework.
A Novel Graphical Lasso based approach towards Segmentation Analysis in Energy Game-Theoretic Frameworks
Oct 05, 2019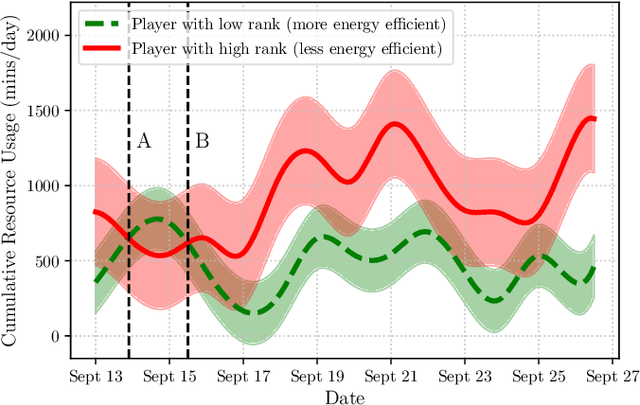
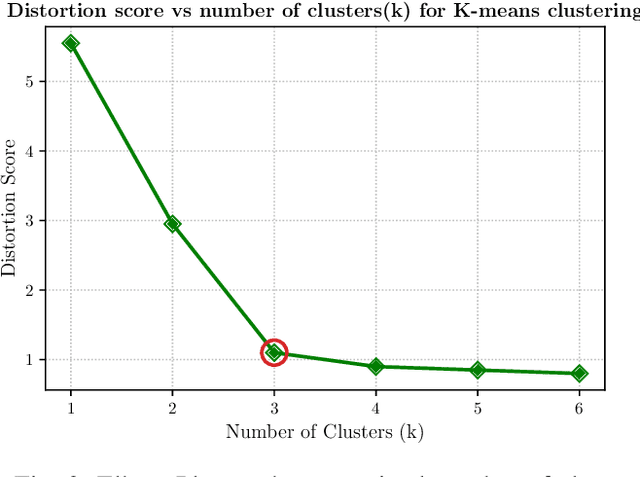
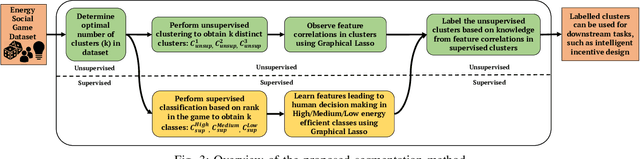
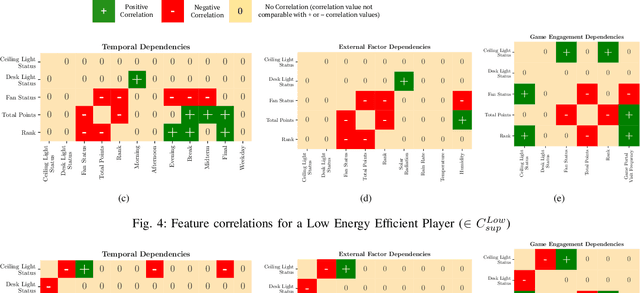
Energy game-theoretic frameworks have emerged to be a successful strategy to encourage energy efficient behavior in large scale by leveraging human-in-the-loop strategy. A number of such frameworks have been introduced over the years which formulate the energy saving process as a competitive game with appropriate incentives for energy efficient players. However, prior works involve an incentive design mechanism which is dependent on knowledge of utility functions for all the players in the game, which is hard to compute especially when the number of players is high, common in energy game-theoretic frameworks. Our research proposes that the utilities of players in such a framework can be grouped together to a relatively small number of clusters, and the clusters can then be targeted with tailored incentives. The key to above segmentation analysis is to learn the features leading to human decision making towards energy usage in competitive environments. We propose a novel graphical lasso based approach to perform such segmentation, by studying the feature correlations in a real-world energy social game dataset. To further improve the explainability of the model, we perform causality study using grangers causality. Proposed segmentation analysis results in characteristic clusters demonstrating different energy usage behaviors. We also present avenues to implement intelligent incentive design using proposed segmentation method.
Efficient Task-Specific Data Valuation for Nearest Neighbor Algorithms
Sep 11, 2019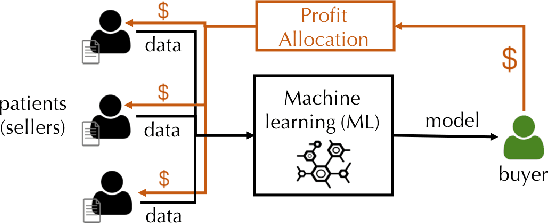

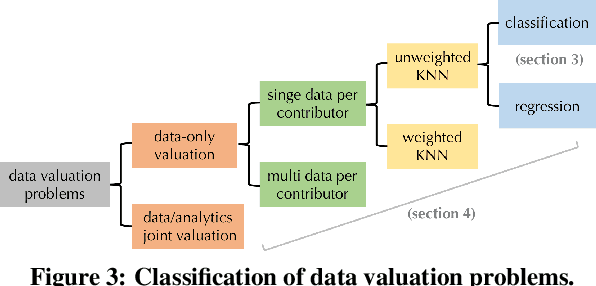

Given a data set $\mathcal{D}$ containing millions of data points and a data consumer who is willing to pay for \$$X$ to train a machine learning (ML) model over $\mathcal{D}$, how should we distribute this \$$X$ to each data point to reflect its "value"? In this paper, we define the "relative value of data" via the Shapley value, as it uniquely possesses properties with appealing real-world interpretations, such as fairness, rationality and decentralizability. For general, bounded utility functions, the Shapley value is known to be challenging to compute: to get Shapley values for all $N$ data points, it requires $O(2^N)$ model evaluations for exact computation and $O(N\log N)$ for $(\epsilon, \delta)$-approximation. In this paper, we focus on one popular family of ML models relying on $K$-nearest neighbors ($K$NN). The most surprising result is that for unweighted $K$NN classifiers and regressors, the Shapley value of all $N$ data points can be computed, exactly, in $O(N\log N)$ time -- an exponential improvement on computational complexity! Moreover, for $(\epsilon, \delta)$-approximation, we are able to develop an algorithm based on Locality Sensitive Hashing (LSH) with only sublinear complexity $O(N^{h(\epsilon,K)}\log N)$ when $\epsilon$ is not too small and $K$ is not too large. We empirically evaluate our algorithms on up to $10$ million data points and even our exact algorithm is up to three orders of magnitude faster than the baseline approximation algorithm. The LSH-based approximation algorithm can accelerate the value calculation process even further. We then extend our algorithms to other scenarios such as (1) weighed $K$NN classifiers, (2) different data points are clustered by different data curators, and (3) there are data analysts providing computation who also requires proper valuation.
Dimensionality Reduction Flows
Aug 05, 2019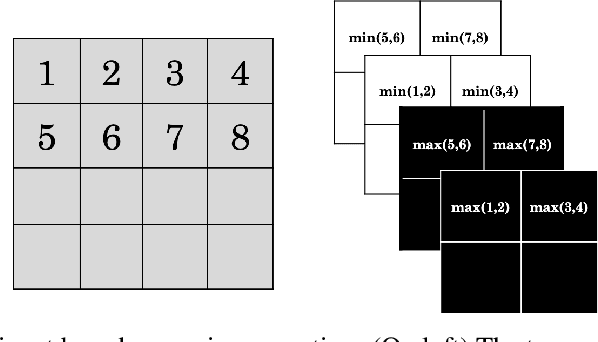



Deep generative modelling using flows has gained popularity owing to the tractable exact log-likelihood estimation with efficient training and synthesis process. Trained flow models carry rich information about the structure and local variance in input data. However, a bottleneck for flow models to scale with increasing dimensions is that the latent space has same size as the high-dimensional input space. In this paper, we propose methods to reduce the latent space dimension of flow models. Our first approach includes replacing standard high dimensional prior with a learned prior from a low dimensional noise space. Further improving to achieve exact log-likelihood with reduced dimensionality, our second approach presents an improved multi-scale architecture (Dinh et al., 2016) via likelihood contribution based factorization of dimensions. Using our method over state-of-the-art flow models, we demonstrate improvements in log-likelihood score on standard image benchmarks. Our work ventures a data dependent factorization scheme which is more efficient than static counterparts in prior works.
Segmentation Analysis in Human Centric Cyber-Physical Systems using Graphical Lasso
Oct 24, 2018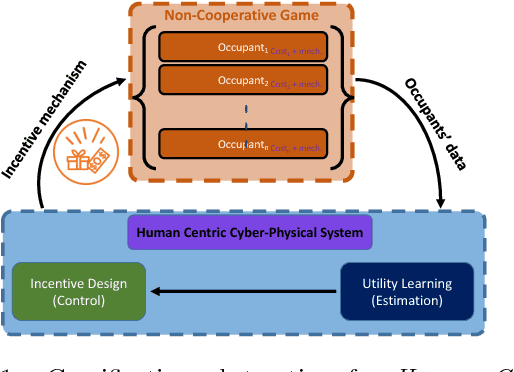

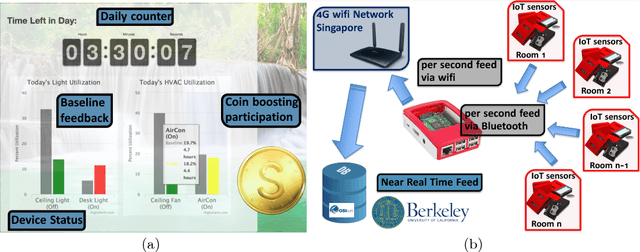

A generalized gamification framework is introduced as a form of smart infrastructure with potential to improve sustainability and energy efficiency by leveraging humans-in-the-loop strategy. The proposed framework enables a Human-Centric Cyber-Physical System using an interface to allow building managers to interact with occupants. The interface is designed for occupant engagement-integration supporting learning of their preferences over resources in addition to understanding how preferences change as a function of external stimuli such as physical control, time or incentives. Towards intelligent and autonomous incentive design, a noble statistical learning algorithm performing occupants energy usage behavior segmentation is proposed. We apply the proposed algorithm, Graphical Lasso, on energy resource usage data by the occupants to obtain feature correlations--dependencies. Segmentation analysis results in characteristic clusters demonstrating different energy usage behaviors. The features--factors characterizing human decision-making are made explainable.