 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDCGen: Cross-Domain Conditional Generation via Normalizing Flows and Adversarial Training
Paper and Code
Aug 25, 2021
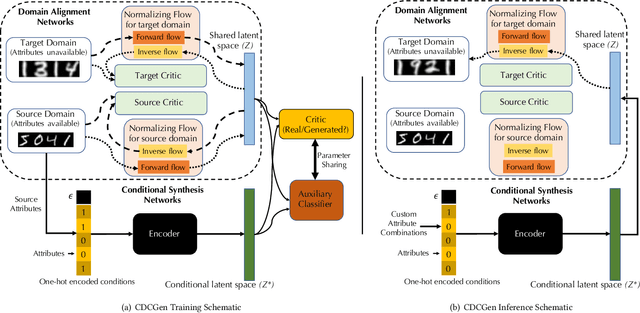


How to generate conditional synthetic data for a domain without utilizing information about its labels/attributes? Our work presents a solution to the above question. We propose a transfer learning-based framework utilizing normalizing flows, coupled with both maximum-likelihood and adversarial training. We model a source domain (labels available) and a target domain (labels unavailable) with individual normalizing flows, and perform domain alignment to a common latent space using adversarial discriminators. Due to the invertible property of flow models, the mapping has exact cycle consistency. We also learn the joint distribution of the data samples and attributes in the source domain by employing an encoder to map attributes to the latent space via adversarial training. During the synthesis phase, given any combination of attributes, our method can generate synthetic samples conditioned on them in the target domain. Empirical studies confirm the effectiveness of our method on benchmarked datasets. We envision our method to be particularly useful for synthetic data generation in label-scarce systems by generating non-trivial augmentations via attribute transformations. These synthetic samples will introduce more entropy into the label-scarce domain than their geometric and photometric transformation counterparts, helpful for robust downstream tasks.