 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Task-Specific Data Valuation for Nearest Neighbor Algorithms
Sep 11, 2019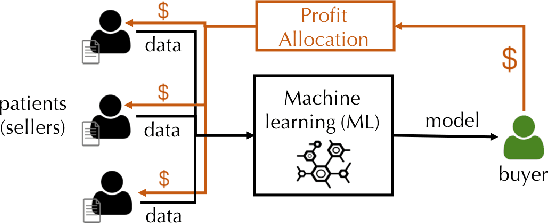

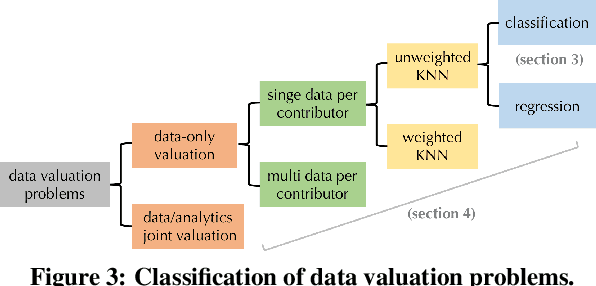

Given a data set $\mathcal{D}$ containing millions of data points and a data consumer who is willing to pay for \$$X$ to train a machine learning (ML) model over $\mathcal{D}$, how should we distribute this \$$X$ to each data point to reflect its "value"? In this paper, we define the "relative value of data" via the Shapley value, as it uniquely possesses properties with appealing real-world interpretations, such as fairness, rationality and decentralizability. For general, bounded utility functions, the Shapley value is known to be challenging to compute: to get Shapley values for all $N$ data points, it requires $O(2^N)$ model evaluations for exact computation and $O(N\log N)$ for $(\epsilon, \delta)$-approximation. In this paper, we focus on one popular family of ML models relying on $K$-nearest neighbors ($K$NN). The most surprising result is that for unweighted $K$NN classifiers and regressors, the Shapley value of all $N$ data points can be computed, exactly, in $O(N\log N)$ time -- an exponential improvement on computational complexity! Moreover, for $(\epsilon, \delta)$-approximation, we are able to develop an algorithm based on Locality Sensitive Hashing (LSH) with only sublinear complexity $O(N^{h(\epsilon,K)}\log N)$ when $\epsilon$ is not too small and $K$ is not too large. We empirically evaluate our algorithms on up to $10$ million data points and even our exact algorithm is up to three orders of magnitude faster than the baseline approximation algorithm. The LSH-based approximation algorithm can accelerate the value calculation process even further. We then extend our algorithms to other scenarios such as (1) weighed $K$NN classifiers, (2) different data points are clustered by different data curators, and (3) there are data analysts providing computation who also requires proper valuation.
Quantitative Overfitting Management for Human-in-the-loop ML Application Development with ease.ml/meter
Jun 06, 2019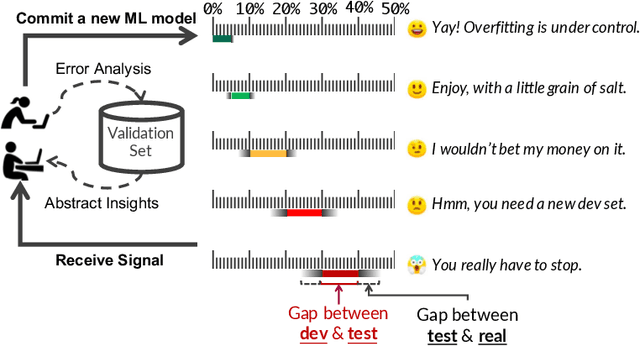
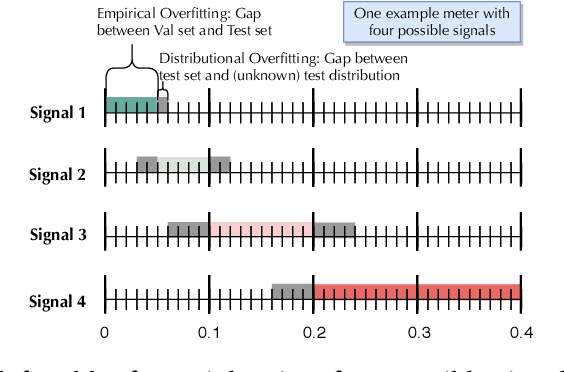
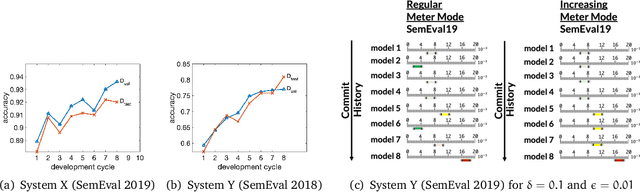
Simplifying machine learning (ML) application development, including distributed computation, programming interface, resource management, model selection, etc, has attracted intensive interests recently. These research efforts have significantly improved the efficiency and the degree of automation of developing ML models. In this paper, we take a first step in an orthogonal direction towards automated quality management for human-in-the-loop ML application development. We build ease. ml/meter, a system that can automatically detect and measure the degree of overfitting during the whole lifecycle of ML application development. ease. ml/meter returns overfitting signals with strong probabilistic guarantees, based on which developers can take appropriate actions. In particular, ease. ml/meter provides principled guidelines to simple yet nontrivial questions regarding desired validation and test data sizes, which are among commonest questions raised by developers. The fact that ML application development is typically a continuous procedure further worsens the situation: The validation and test data sets can lose their statistical power quickly due to multiple accesses, especially in the presence of adaptive analysis. ease. ml/meter addresses these challenges by leveraging a collection of novel techniques and optimizations, resulting in practically tractable data sizes without compromising the probabilistic guarantees. We present the design and implementation details of ease. ml/meter, as well as detailed theoretical analysis and empirical evaluation of its effectiveness.
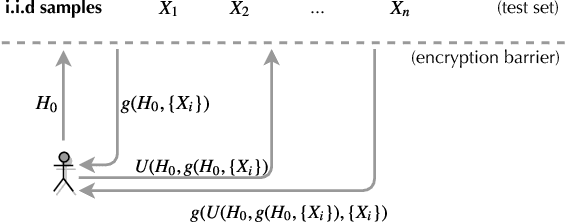
Towards Efficient Data Valuation Based on the Shapley Value
Feb 27, 2019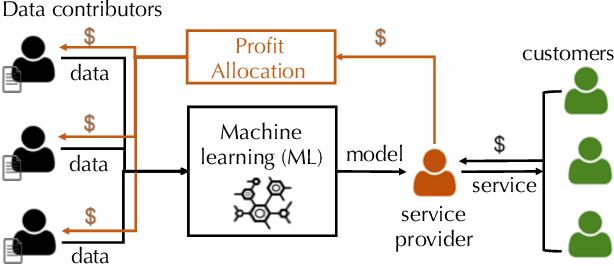

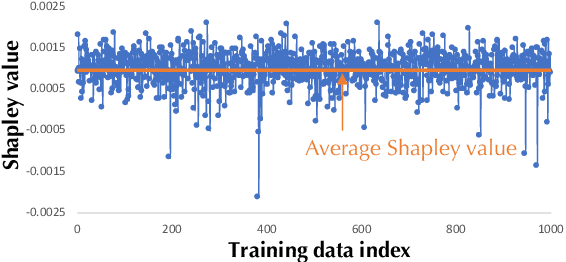
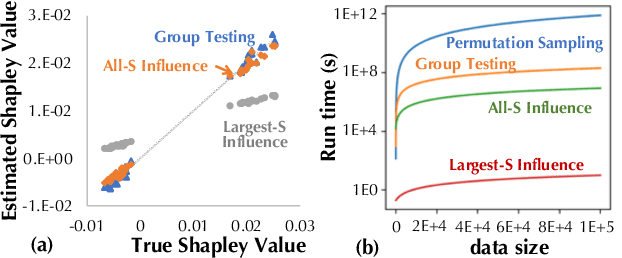
"How much is my data worth?" is an increasingly common question posed by organizations and individuals alike. An answer to this question could allow, for instance, fairly distributing profits among multiple data contributors and determining prospective compensation when data breaches happen. In this paper, we study the problem of data valuation by utilizing the Shapley value, a popular notion of value which originated in coopoerative game theory. The Shapley value defines a unique payoff scheme that satisfies many desiderata for the notion of data value. However, the Shapley value often requires exponential time to compute. To meet this challenge, we propose a repertoire of efficient algorithms for approximating the Shapley value. We also demonstrate the value of each training instance for various benchmark datasets.