 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Reinforcement Learning for Robust Building Control
Dec 16, 2023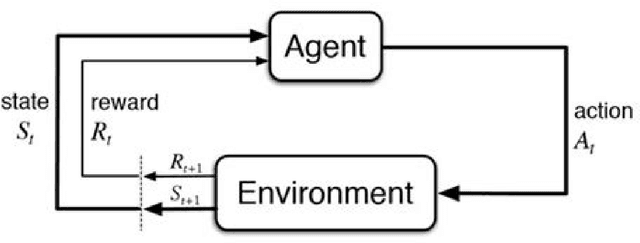
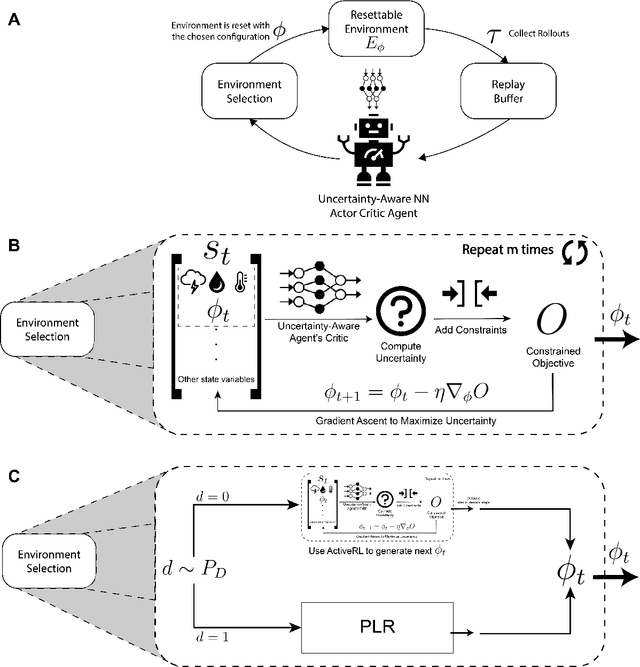
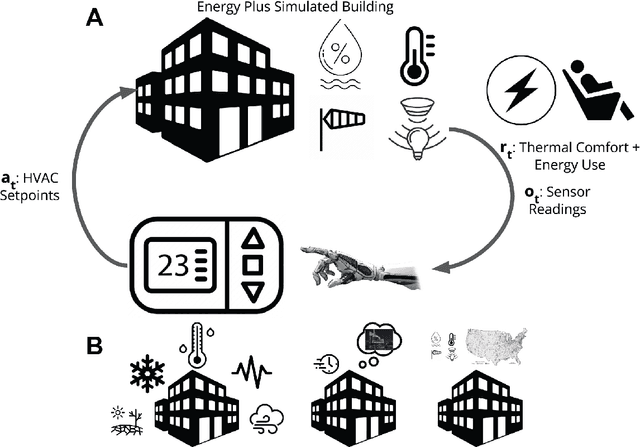
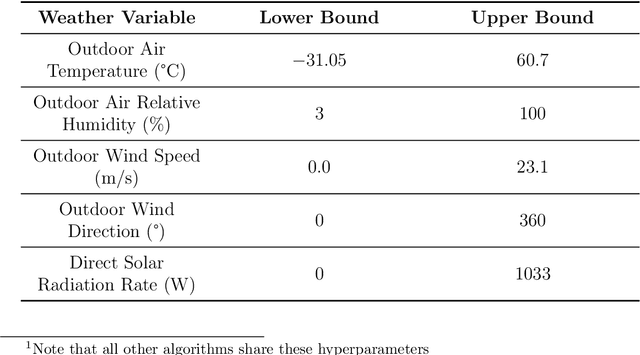
Reinforcement learning (RL) is a powerful tool for optimal control that has found great success in Atari games, the game of Go, robotic control, and building optimization. RL is also very brittle; agents often overfit to their training environment and fail to generalize to new settings. Unsupervised environment design (UED) has been proposed as a solution to this problem, in which the agent trains in environments that have been specially selected to help it learn. Previous UED algorithms focus on trying to train an RL agent that generalizes across a large distribution of environments. This is not necessarily desirable when we wish to prioritize performance in one environment over others. In this work, we will be examining the setting of robust RL building control, where we wish to train an RL agent that prioritizes performing well in normal weather while still being robust to extreme weather conditions. We demonstrate a novel UED algorithm, ActivePLR, that uses uncertainty-aware neural network architectures to generate new training environments at the limit of the RL agent's ability while being able to prioritize performance in a desired base environment. We show that ActivePLR is able to outperform state-of-the-art UED algorithms in minimizing energy usage while maximizing occupant comfort in the setting of building control.
Personalized Federated Hypernetworks for Privacy Preservation in Multi-Task Reinforcement Learning
Oct 19, 2022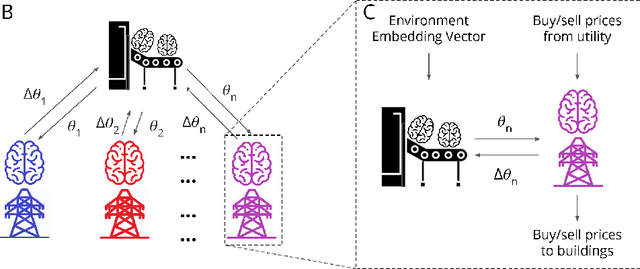
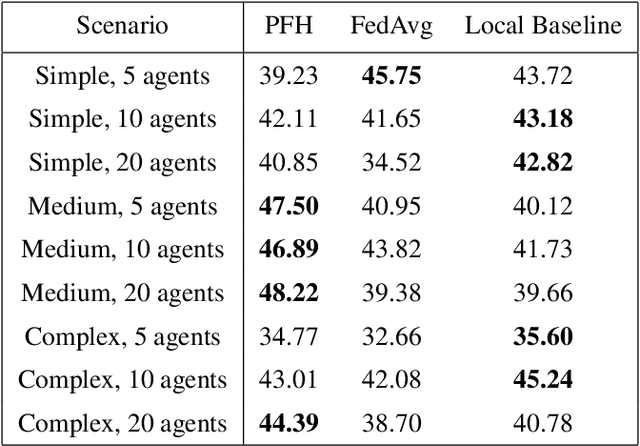
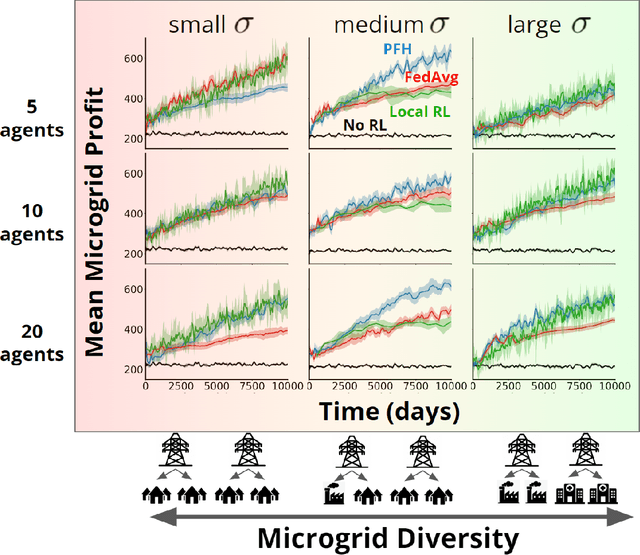
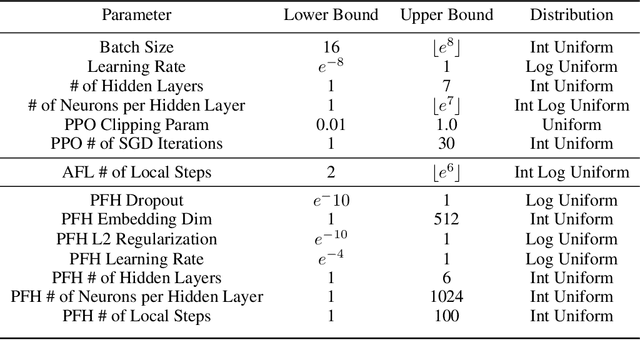
Multi-Agent Reinforcement Learning currently focuses on implementations where all data and training can be centralized to one machine. But what if local agents are split across multiple tasks, and need to keep data private between each? We develop the first application of Personalized Federated Hypernetworks (PFH) to Reinforcement Learning (RL). We then present a novel application of PFH to few-shot transfer, and demonstrate significant initial increases in learning. PFH has never been demonstrated beyond supervised learning benchmarks, so we apply PFH to an important domain: RL price-setting for energy demand response. We consider a general case across where agents are split across multiple microgrids, wherein energy consumption data must be kept private within each microgrid. Together, our work explores how the fields of personalized federated learning and RL can come together to make learning efficient across multiple tasks while keeping data secure.
Offline-Online Reinforcement Learning for Energy Pricing in Office Demand Response: Lowering Energy and Data Costs
Aug 14, 2021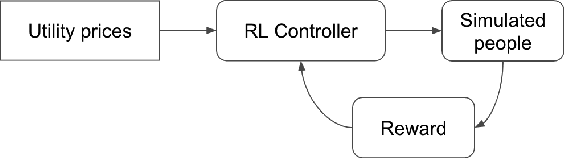

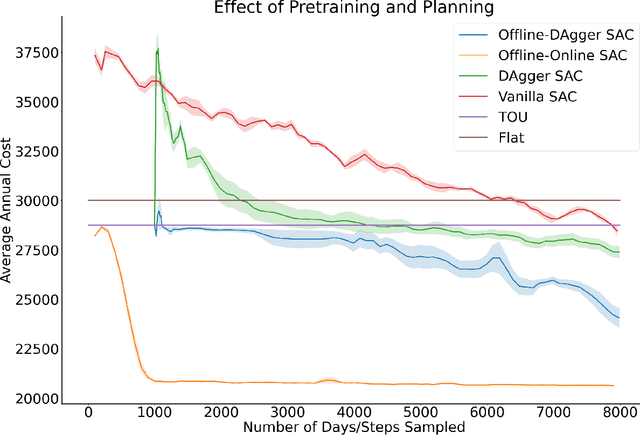
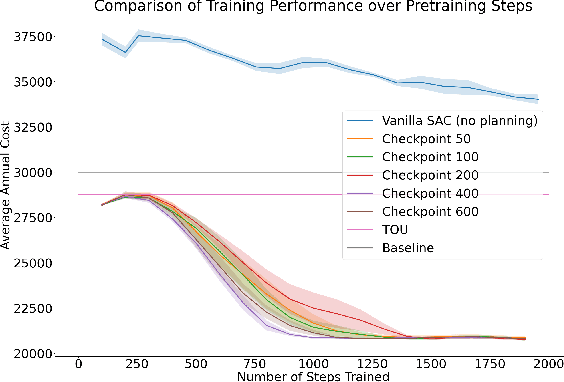
Our team is proposing to run a full-scale energy demand response experiment in an office building. Although this is an exciting endeavor which will provide value to the community, collecting training data for the reinforcement learning agent is costly and will be limited. In this work, we examine how offline training can be leveraged to minimize data costs (accelerate convergence) and program implementation costs. We present two approaches to doing so: pretraining our model to warm start the experiment with simulated tasks, and using a planning model trained to simulate the real world's rewards to the agent. We present results that demonstrate the utility of offline reinforcement learning to efficient price-setting in the energy demand response problem.
Using Meta Reinforcement Learning to Bridge the Gap between Simulation and Experiment in Energy Demand Response
May 17, 2021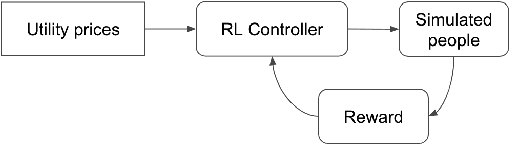
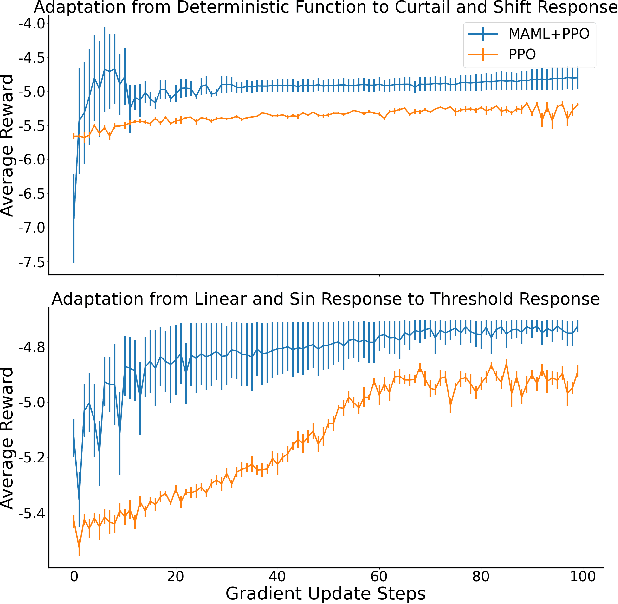
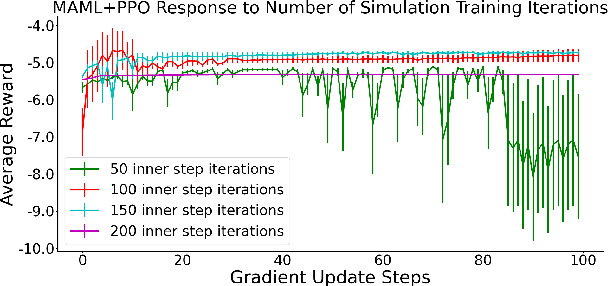
Our team is proposing to run a full-scale energy demand response experiment in an office building. Although this is an exciting endeavor which will provide value to the community, collecting training data for the reinforcement learning agent is costly and will be limited. In this work, we apply a meta-learning architecture to warm start the experiment with simulated tasks, to increase sample efficiency. We present results that demonstrate a similar a step up in complexity still corresponds with better learning.