 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters in Orchestrating Robot Policies: A Systematic Study of Hierarchical VLA Agents
Jun 09, 2026Hierarchical vision-language-action (Hi-VLA) systems have emerged as a promising paradigm for complex robot manipulation, by using high-level VLM planners to decompose tasks into language subgoals executed by low-level VLA controllers. Despite recent empirical progress, there is a lack of unified design principles for these systems: existing Hi-VLA systems differ in how they choose and connect planners, controllers, mechanisms to switch between the two, and how observations and memory are represented in the planner. In this paper, we present a systematic study of Hi-VLA design for robot manipulation. We unify representative Hi-VLA agents under an options-style control framework and benchmark core design choices across short-horizon, long-horizon, and reasoning-intensive tasks. Our analysis distills practical principles for building Hi-VLA systems, showing how model choices and interface mechanisms jointly shape performance. Applying these principles yields a substantially stronger system than either flat VLA control or a naively designed hierarchy, across experiments both in simulation and on a real ALOHA robot. Overall, our results provide a foundation for building more capable, robust, and principled hierarchical VLA agents. More information and video at jiahenghu.github.io/hi-vla.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Robot Data Curation with Mutual Information Estimators
Feb 12, 2025The performance of imitation learning policies often hinges on the datasets with which they are trained. Consequently, investment in data collection for robotics has grown across both industrial and academic labs. However, despite the marked increase in the quantity of demonstrations collected, little work has sought to assess the quality of said data despite mounting evidence of its importance in other areas such as vision and language. In this work, we take a critical step towards addressing the data quality in robotics. Given a dataset of demonstrations, we aim to estimate the relative quality of individual demonstrations in terms of both state diversity and action predictability. To do so, we estimate the average contribution of a trajectory towards the mutual information between states and actions in the entire dataset, which precisely captures both the entropy of the state distribution and the state-conditioned entropy of actions. Though commonly used mutual information estimators require vast amounts of data often beyond the scale available in robotics, we introduce a novel technique based on k-nearest neighbor estimates of mutual information on top of simple VAE embeddings of states and actions. Empirically, we demonstrate that our approach is able to partition demonstration datasets by quality according to human expert scores across a diverse set of benchmarks spanning simulation and real world environments. Moreover, training policies based on data filtered by our method leads to a 5-10% improvement in RoboMimic and better performance on real ALOHA and Franka setups.
Bidirectional Decoding: Improving Action Chunking via Closed-Loop Resampling
Aug 30, 2024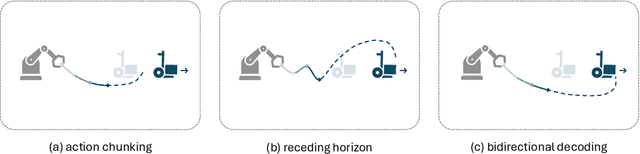
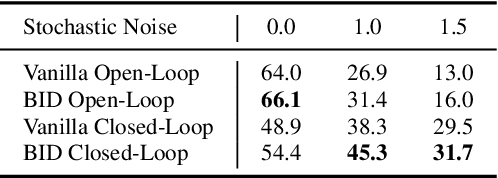
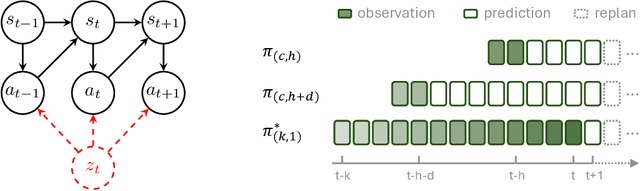
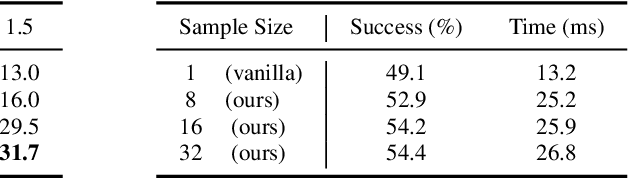
Predicting and executing a sequence of actions without intermediate replanning, known as action chunking, is increasingly used in robot learning from human demonstrations. However, its effects on learned policies remain puzzling: some studies highlight its importance for achieving strong performance, while others observe detrimental effects. In this paper, we first dissect the role of action chunking by analyzing the divergence between the learner and the demonstrator. We find that longer action chunks enable a policy to better capture temporal dependencies by taking into account more past states and actions within the chunk. However, this advantage comes at the cost of exacerbating errors in stochastic environments due to fewer observations of recent states. To address this, we propose Bidirectional Decoding (BID), a test-time inference algorithm that bridges action chunking with closed-loop operations. BID samples multiple predictions at each time step and searches for the optimal one based on two criteria: (i) backward coherence, which favors samples aligned with previous decisions, (ii) forward contrast, which favors samples close to outputs of a stronger policy and distant from those of a weaker policy. By coupling decisions within and across action chunks, BID enhances temporal consistency over extended sequences while enabling adaptive replanning in stochastic environments. Experimental results show that BID substantially outperforms conventional closed-loop operations of two state-of-the-art generative policies across seven simulation benchmarks and two real-world tasks.
Affordance-Guided Reinforcement Learning via Visual Prompting
Jul 14, 2024Robots equipped with reinforcement learning (RL) have the potential to learn a wide range of skills solely from a reward signal. However, obtaining a robust and dense reward signal for general manipulation tasks remains a challenge. Existing learning-based approaches require significant data, such as demonstrations or examples of success and failure, to learn task-specific reward functions. Recently, there is also a growing adoption of large multi-modal foundation models for robotics. These models can perform visual reasoning in physical contexts and generate coarse robot motions for various manipulation tasks. Motivated by this range of capability, in this work, we propose and study rewards shaped by vision-language models (VLMs). State-of-the-art VLMs have demonstrated an impressive ability to reason about affordances through keypoints in zero-shot, and we leverage this to define dense rewards for robotic learning. On a real-world manipulation task specified by natural language description, we find that these rewards improve the sample efficiency of autonomous RL and enable successful completion of the task in 20K online finetuning steps. Additionally, we demonstrate the robustness of the approach to reductions in the number of in-domain demonstrations used for pretraining, reaching comparable performance in 35K online finetuning steps.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
Efficient Data Collection for Robotic Manipulation via Compositional Generalization
Mar 08, 2024



Data collection has become an increasingly important problem in robotic manipulation, yet there still lacks much understanding of how to effectively collect data to facilitate broad generalization. Recent works on large-scale robotic data collection typically vary a wide range of environmental factors during data collection, such as object types and table textures. While these works attempt to cover a diverse variety of scenarios, they do not explicitly account for the possible compositional abilities of policies trained on the data. If robot policies are able to compose different environmental factors of variation (e.g., object types, table heights) from their training data to succeed when encountering unseen factor combinations, then we can exploit this to avoid collecting data for situations that composition would address. To investigate this possibility, we conduct thorough empirical studies both in simulation and on a real robot that compare data collection strategies and assess whether visual imitation learning policies can compose environmental factors. We find that policies do exhibit composition, although leveraging prior robotic datasets is critical for this on a real robot. We use these insights to provide better practices for in-domain data collection by proposing data collection strategies that exploit composition, which can induce better generalization than naive approaches for the same amount of effort during data collection. We further demonstrate that a real robot policy trained on data from such a strategy achieves a success rate of 77.5% when transferred to entirely new environments that encompass unseen combinations of environmental factors, whereas policies trained using data collected without accounting for environmental variation fail to transfer effectively, with a success rate of only 2.5%. We provide videos at http://iliad.stanford.edu/robot-data-comp/.
PIVOT: Iterative Visual Prompting Elicits Actionable Knowledge for VLMs
Feb 12, 2024



Vision language models (VLMs) have shown impressive capabilities across a variety of tasks, from logical reasoning to visual understanding. This opens the door to richer interaction with the world, for example robotic control. However, VLMs produce only textual outputs, while robotic control and other spatial tasks require outputting continuous coordinates, actions, or trajectories. How can we enable VLMs to handle such settings without fine-tuning on task-specific data? In this paper, we propose a novel visual prompting approach for VLMs that we call Prompting with Iterative Visual Optimization (PIVOT), which casts tasks as iterative visual question answering. In each iteration, the image is annotated with a visual representation of proposals that the VLM can refer to (e.g., candidate robot actions, localizations, or trajectories). The VLM then selects the best ones for the task. These proposals are iteratively refined, allowing the VLM to eventually zero in on the best available answer. We investigate PIVOT on real-world robotic navigation, real-world manipulation from images, instruction following in simulation, and additional spatial inference tasks such as localization. We find, perhaps surprisingly, that our approach enables zero-shot control of robotic systems without any robot training data, navigation in a variety of environments, and other capabilities. Although current performance is far from perfect, our work highlights potentials and limitations of this new regime and shows a promising approach for Internet-Scale VLMs in robotic and spatial reasoning domains. Website: pivot-prompt.github.io and HuggingFace: https://huggingface.co/spaces/pivot-prompt/pivot-prompt-demo.
Decomposing the Generalization Gap in Imitation Learning for Visual Robotic Manipulation
Jul 07, 2023



What makes generalization hard for imitation learning in visual robotic manipulation? This question is difficult to approach at face value, but the environment from the perspective of a robot can often be decomposed into enumerable factors of variation, such as the lighting conditions or the placement of the camera. Empirically, generalization to some of these factors have presented a greater obstacle than others, but existing work sheds little light on precisely how much each factor contributes to the generalization gap. Towards an answer to this question, we study imitation learning policies in simulation and on a real robot language-conditioned manipulation task to quantify the difficulty of generalization to different (sets of) factors. We also design a new simulated benchmark of 19 tasks with 11 factors of variation to facilitate more controlled evaluations of generalization. From our study, we determine an ordering of factors based on generalization difficulty, that is consistent across simulation and our real robot setup.
Supervised Pretraining Can Learn In-Context Reinforcement Learning
Jun 26, 2023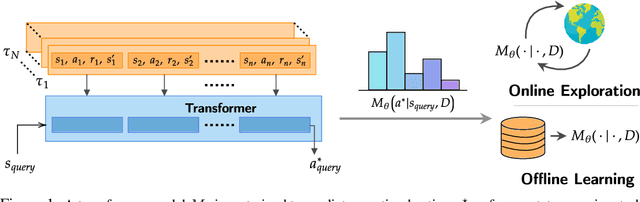
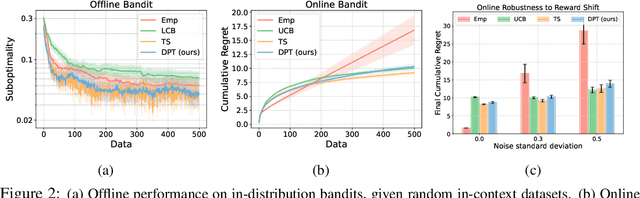
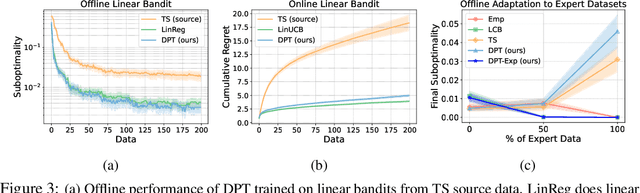
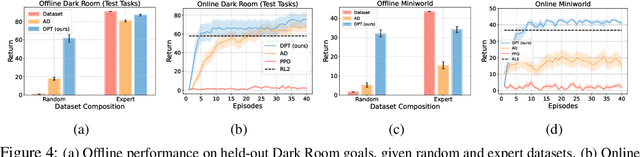
Large transformer models trained on diverse datasets have shown a remarkable ability to learn in-context, achieving high few-shot performance on tasks they were not explicitly trained to solve. In this paper, we study the in-context learning capabilities of transformers in decision-making problems, i.e., reinforcement learning (RL) for bandits and Markov decision processes. To do so, we introduce and study Decision-Pretrained Transformer (DPT), a supervised pretraining method where the transformer predicts an optimal action given a query state and an in-context dataset of interactions, across a diverse set of tasks. This procedure, while simple, produces a model with several surprising capabilities. We find that the pretrained transformer can be used to solve a range of RL problems in-context, exhibiting both exploration online and conservatism offline, despite not being explicitly trained to do so. The model also generalizes beyond the pretraining distribution to new tasks and automatically adapts its decision-making strategies to unknown structure. Theoretically, we show DPT can be viewed as an efficient implementation of Bayesian posterior sampling, a provably sample-efficient RL algorithm. We further leverage this connection to provide guarantees on the regret of the in-context algorithm yielded by DPT, and prove that it can learn faster than algorithms used to generate the pretraining data. These results suggest a promising yet simple path towards instilling strong in-context decision-making abilities in transformers.