 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Decoding: Improving Action Chunking via Closed-Loop Resampling
Aug 30, 2024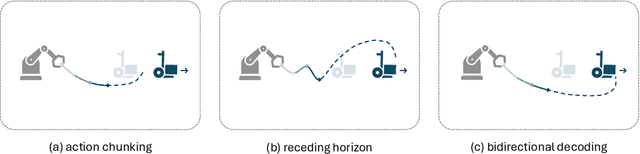
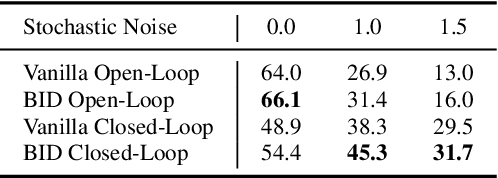
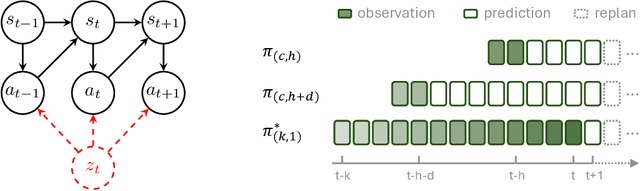
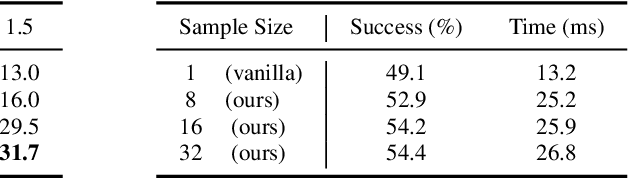
Predicting and executing a sequence of actions without intermediate replanning, known as action chunking, is increasingly used in robot learning from human demonstrations. However, its effects on learned policies remain puzzling: some studies highlight its importance for achieving strong performance, while others observe detrimental effects. In this paper, we first dissect the role of action chunking by analyzing the divergence between the learner and the demonstrator. We find that longer action chunks enable a policy to better capture temporal dependencies by taking into account more past states and actions within the chunk. However, this advantage comes at the cost of exacerbating errors in stochastic environments due to fewer observations of recent states. To address this, we propose Bidirectional Decoding (BID), a test-time inference algorithm that bridges action chunking with closed-loop operations. BID samples multiple predictions at each time step and searches for the optimal one based on two criteria: (i) backward coherence, which favors samples aligned with previous decisions, (ii) forward contrast, which favors samples close to outputs of a stronger policy and distant from those of a weaker policy. By coupling decisions within and across action chunks, BID enhances temporal consistency over extended sequences while enabling adaptive replanning in stochastic environments. Experimental results show that BID substantially outperforms conventional closed-loop operations of two state-of-the-art generative policies across seven simulation benchmarks and two real-world tasks.
To Err is Robotic: Rapid Value-Based Trial-and-Error during Deployment
Jun 22, 2024



When faced with a novel scenario, it can be hard to succeed on the first attempt. In these challenging situations, it is important to know how to retry quickly and meaningfully. Retrying behavior can emerge naturally in robots trained on diverse data, but such robot policies will typically only exhibit undirected retrying behavior and may not terminate a suboptimal approach before an unrecoverable mistake. We can improve these robot policies by instilling an explicit ability to try, evaluate, and retry a diverse range of strategies. We introduce Bellman-Guided Retrials, an algorithm that works on top of a base robot policy by monitoring the robot's progress, detecting when a change of plan is needed, and adapting the executed strategy until the robot succeeds. We start with a base policy trained on expert demonstrations of a variety of scenarios. Then, using the same expert demonstrations, we train a value function to estimate task completion. During test time, we use the value function to compare our expected rate of progress to our achieved rate of progress. If our current strategy fails to make progress at a reasonable rate, we recover the robot and sample a new strategy from the base policy while skewing it away from behaviors that have recently failed. We evaluate our method on simulated and real-world environments that contain a diverse suite of scenarios. We find that Bellman-Guided Retrials increases the average absolute success rates of base policies by more than 20% in simulation and 50% in real-world experiments, demonstrating a promising framework for instilling existing trained policies with explicit trial and error capabilities. For evaluation videos and other documentation, go to https://sites.google.com/view/to-err-robotic/home
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Behavior Retrieval: Few-Shot Imitation Learning by Querying Unlabeled Datasets
Apr 18, 2023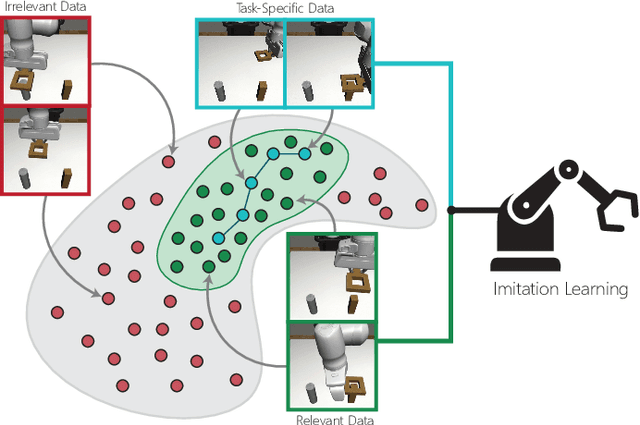
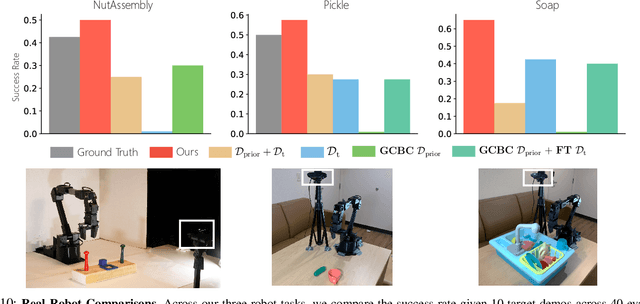
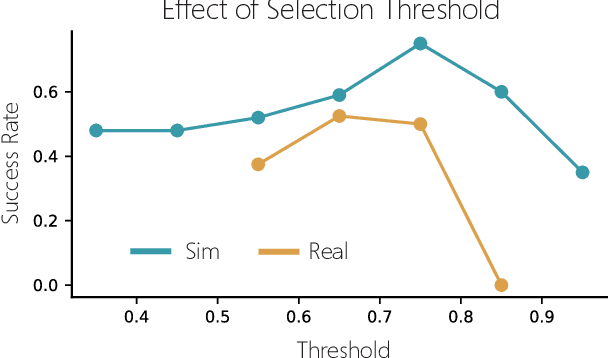
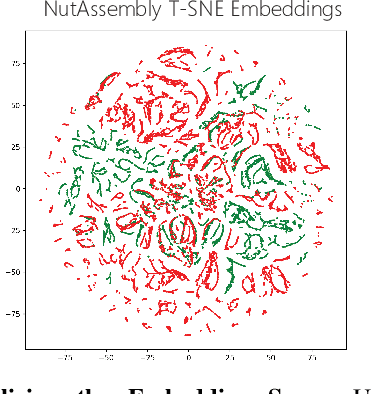
Enabling robots to learn novel visuomotor skills in a data-efficient manner remains an unsolved problem with myriad challenges. A popular paradigm for tackling this problem is through leveraging large unlabeled datasets that have many behaviors in them and then adapting a policy to a specific task using a small amount of task-specific human supervision (i.e. interventions or demonstrations). However, how best to leverage the narrow task-specific supervision and balance it with offline data remains an open question. Our key insight in this work is that task-specific data not only provides new data for an agent to train on but can also inform the type of prior data the agent should use for learning. Concretely, we propose a simple approach that uses a small amount of downstream expert data to selectively query relevant behaviors from an offline, unlabeled dataset (including many sub-optimal behaviors). The agent is then jointly trained on the expert and queried data. We observe that our method learns to query only the relevant transitions to the task, filtering out sub-optimal or task-irrelevant data. By doing so, it is able to learn more effectively from the mix of task-specific and offline data compared to naively mixing the data or only using the task-specific data. Furthermore, we find that our simple querying approach outperforms more complex goal-conditioned methods by 20% across simulated and real robotic manipulation tasks from images. See https://sites.google.com/view/behaviorretrieval for videos and code.
Play it by Ear: Learning Skills amidst Occlusion through Audio-Visual Imitation Learning
May 30, 2022
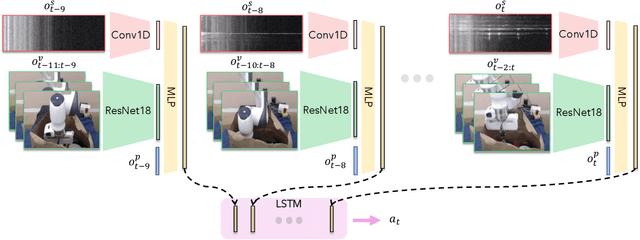
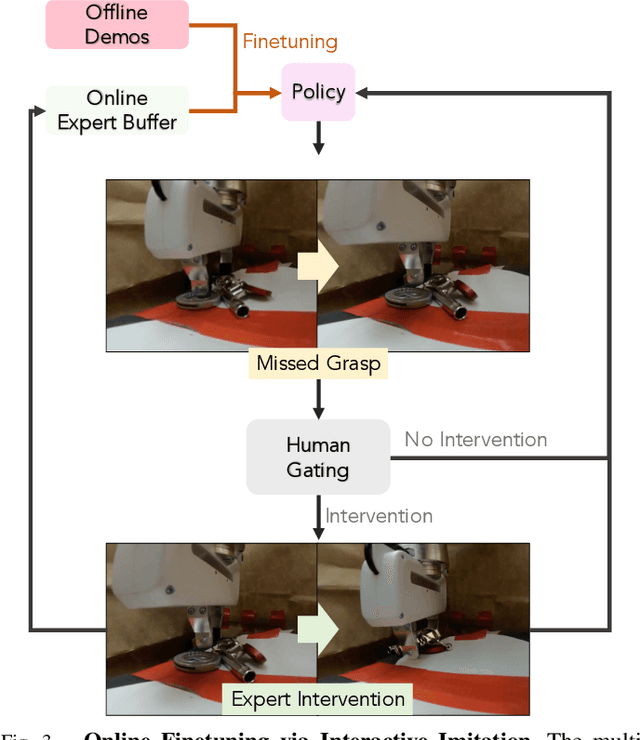

Humans are capable of completing a range of challenging manipulation tasks that require reasoning jointly over modalities such as vision, touch, and sound. Moreover, many such tasks are partially-observed; for example, taking a notebook out of a backpack will lead to visual occlusion and require reasoning over the history of audio or tactile information. While robust tactile sensing can be costly to capture on robots, microphones near or on a robot's gripper are a cheap and easy way to acquire audio feedback of contact events, which can be a surprisingly valuable data source for perception in the absence of vision. Motivated by the potential for sound to mitigate visual occlusion, we aim to learn a set of challenging partially-observed manipulation tasks from visual and audio inputs. Our proposed system learns these tasks by combining offline imitation learning from a modest number of tele-operated demonstrations and online finetuning using human provided interventions. In a set of simulated tasks, we find that our system benefits from using audio, and that by using online interventions we are able to improve the success rate of offline imitation learning by ~20%. Finally, we find that our system can complete a set of challenging, partially-observed tasks on a Franka Emika Panda robot, like extracting keys from a bag, with a 70% success rate, 50% higher than a policy that does not use audio.
Improving LSTM Neural Networks for Better Short-Term Wind Power Predictions
Aug 03, 2019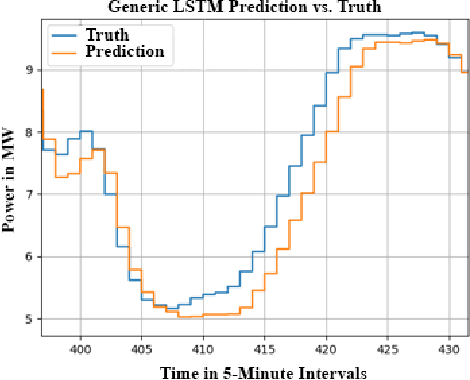
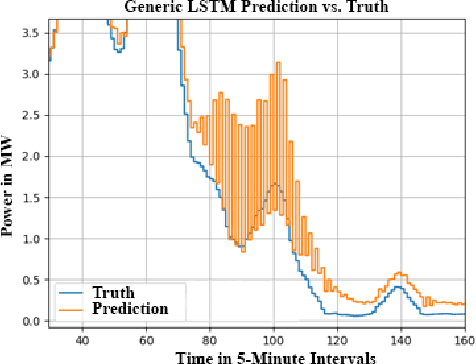

This paper improves wind power prediction via weather forecast-contextualized Long Short-Term Memory Neural Network (LSTM) models. Initially, only wind power data was fed to a generic LSTM, but this model performed poorly, with erratic and naive behavior observed on even low-variance data sections. To address this issue, weather forecast data was added to better contextualize the power data, and LSTM modifications were made to address specific model shortcomings. These models were tested through both a Normalized Mean Absolute Error and the Naive Ratio (NR), which is a score introduced by this paper to quantify the unwanted presence of naive character in trained models. Results showed an increased accuracy with the addition of weather forecast data on the modified models, as well as a decrease in naive character. Key contributions include making improved LSTM variants, usage of weather forecast data, and the introduction of a new model performance index.
Application of Autoencoder-Assisted Recurrent Neural Networks to Prevent Cases of Sudden Infant Death Syndrome
Apr 28, 2019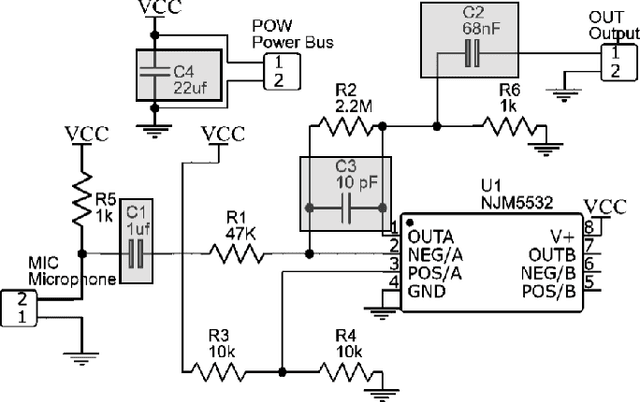

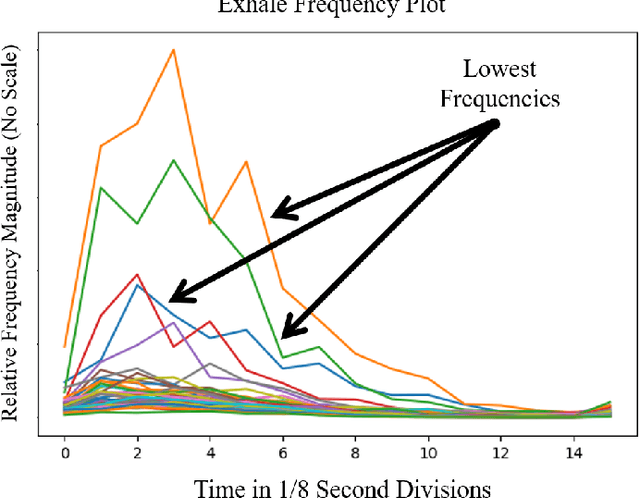
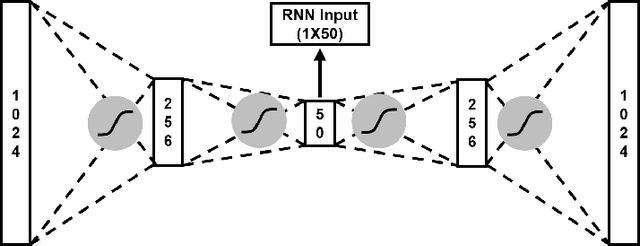
This project develops and trains a Recurrent Neural Network (RNN) that monitors sleeping infants from an auxiliary microphone for cases of Sudden Infant Death Syndrome (SIDS), manifested in sudden or gradual respiratory arrest. To minimize invasiveness and maximize economic viability, an electret microphone, and parabolic concentrator, paired with a specially designed and tuned amplifier circuit, was used as a very sensitive audio monitoring device, which fed data to the RNN model. This RNN was trained and operated in the frequency domain, where the respiratory activity is most unique from noise. In both training and operation, a Fourier transform and an autoencoder compression were applied to the raw audio, and this transformed audio data was fed into the model in 1/8 second time steps. In operation, this model flagged each perceived breath, and the time between breaths was analyzed through a statistical T-test for slope, which detected dangerous trends. The entire model achieved 92.5% accuracy on continuous data and had an 11.25-second response rate on data that emulated total respiratory arrest. Because of the compatibility of the trained model with many off-the-shelf devices like Android phones and Raspberry Pi's, free-standing processing hardware deployment is a very feasible future goal.