 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Human-Level Learning of Complex Physical Puzzles
Nov 14, 2020
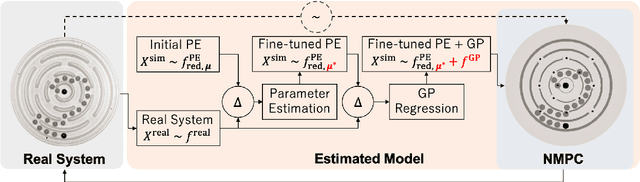
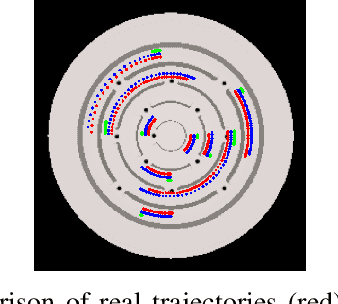
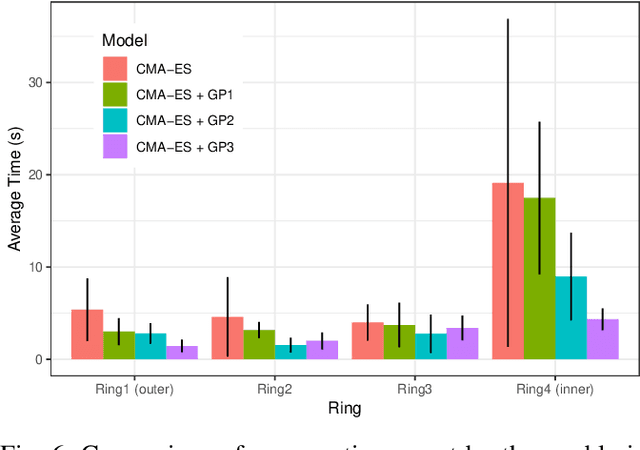
Humans quickly solve tasks in novel systems with complex dynamics, without requiring much interaction. While deep reinforcement learning algorithms have achieved tremendous success in many complex tasks, these algorithms need a large number of samples to learn meaningful policies. In this paper, we present a task for navigating a marble to the center of a circular maze. While this system is very intuitive and easy for humans to solve, it can be very difficult and inefficient for standard reinforcement learning algorithms to learn meaningful policies. We present a model that learns to move a marble in the complex environment within minutes of interacting with the real system. Learning consists of initializing a physics engine with parameters estimated using data from the real system. The error in the physics engine is then corrected using Gaussian process regression, which is used to model the residual between real observations and physics engine simulations. The physics engine equipped with the residual model is then used to control the marble in the maze environment using a model-predictive feedback over a receding horizon. We contrast the learning behavior against the time taken by humans to solve the problem to show comparable behavior. To the best of our knowledge, this is the first time that a hybrid model consisting of a full physics engine along with a statistical function approximator has been used to control a complex physical system in real-time using nonlinear model-predictive control (NMPC). Codes for the simulation environment can be downloaded here https://www.merl.com/research/license/CME . A video describing our method could be found here https://youtu.be/xaxNCXBovpc .
Can Increasing Input Dimensionality Improve Deep Reinforcement Learning?
Mar 03, 2020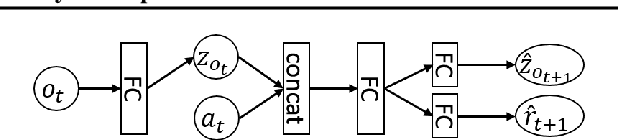

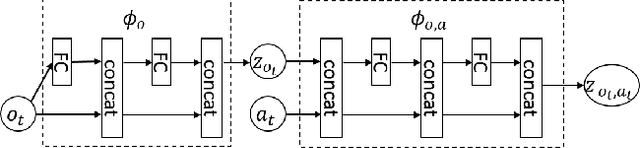
Deep reinforcement learning (RL) algorithms have recently achieved remarkable successes in various sequential decision making tasks, leveraging advances in methods for training large deep networks. However, these methods usually require large amounts of training data, which is often a big problem for real-world applications. One natural question to ask is whether learning good representations for states and using larger networks helps in learning better policies. In this paper, we try to study if increasing input dimensionality helps improve performance and sample efficiency of model-free deep RL algorithms. To do so, we propose an online feature extractor network (OFENet) that uses neural nets to produce good representations to be used as inputs to deep RL algorithms. Even though the high dimensionality of input is usually supposed to make learning of RL agents more difficult, we show that the RL agents in fact learn more efficiently with the high-dimensional representation than with the lower-dimensional state observations. We believe that stronger feature propagation together with larger networks (and thus larger search space) allows RL agents to learn more complex functions of states and thus improves the sample efficiency. Through numerical experiments, we show that the proposed method outperforms several other state-of-the-art algorithms in terms of both sample efficiency and performance.
Trajectory Optimization for Unknown Constrained Systems using Reinforcement Learning
Mar 13, 2019

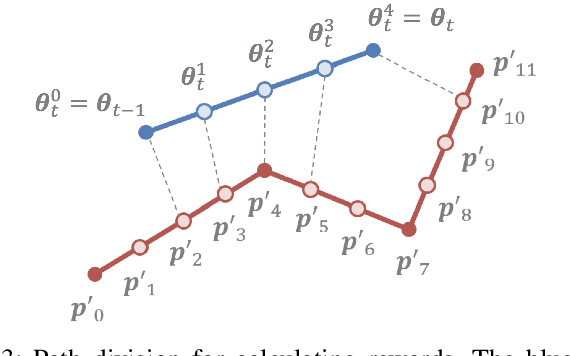
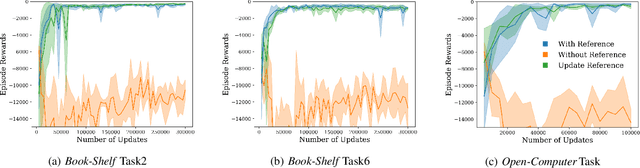
In this paper, we propose a reinforcement learning-based algorithm for trajectory optimization for constrained dynamical systems. This problem is motivated by the fact that for most robotic systems, the dynamics may not always be known. Generating smooth, dynamically feasible trajectories could be difficult for such systems. Using sampling-based algorithms for motion planning may result in trajectories that are prone to undesirable control jumps. However, they can usually provide a good reference trajectory which a model-free reinforcement learning algorithm can then exploit by limiting the search domain and quickly finding a dynamically smooth trajectory. We use this idea to train a reinforcement learning agent to learn a dynamically smooth trajectory in a curriculum learning setting. Furthermore, for generalization, we parameterize the policies with goal locations, so that the agent can be trained for multiple goals simultaneously. We show result in both simulated environments as well as real experiments, for a $6$-DoF manipulator arm operated in position-controlled mode to validate the proposed idea. We compare the proposed ideas against a PID controller which is used to track a designed trajectory in configuration space. Our experiments show that our RL agent trained with a reference path outperformed a model-free PID controller of the type commonly used on many robotic platforms for trajectory tracking.