 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStability-Certified Reinforcement Learning via Spectral Normalization
Dec 26, 2020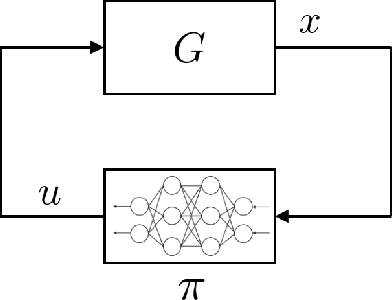
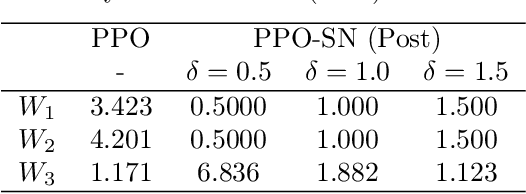

In this article, two types of methods from different perspectives based on spectral normalization are described for ensuring the stability of the system controlled by a neural network. The first one is that the L2 gain of the feedback system is bounded less than 1 to satisfy the stability condition derived from the small-gain theorem. While explicitly including the stability condition, the first method may provide an insufficient performance on the neural network controller due to its strict stability condition. To overcome this difficulty, the second one is proposed, which improves the performance while ensuring the local stability with a larger region of attraction. In the second method, the stability is ensured by solving linear matrix inequalities after training the neural network controller. The spectral normalization proposed in this article improves the feasibility of the a-posteriori stability test by constructing tighter local sectors. The numerical experiments show that the second method provides enough performance compared with the first one while ensuring enough stability compared with the existing reinforcement learning algorithms.
Deep Reactive Planning in Dynamic Environments
Nov 05, 2020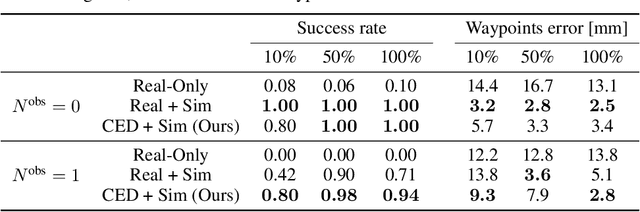
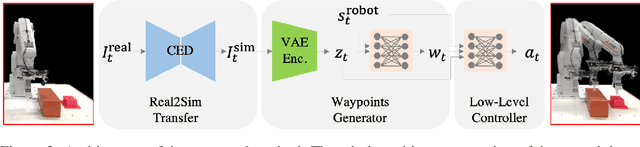


The main novelty of the proposed approach is that it allows a robot to learn an end-to-end policy which can adapt to changes in the environment during execution. While goal conditioning of policies has been studied in the RL literature, such approaches are not easily extended to cases where the robot's goal can change during execution. This is something that humans are naturally able to do. However, it is difficult for robots to learn such reflexes (i.e., to naturally respond to dynamic environments), especially when the goal location is not explicitly provided to the robot, and instead needs to be perceived through a vision sensor. In the current work, we present a method that can achieve such behavior by combining traditional kinematic planning, deep learning, and deep reinforcement learning in a synergistic fashion to generalize to arbitrary environments. We demonstrate the proposed approach for several reaching and pick-and-place tasks in simulation, as well as on a real system of a 6-DoF industrial manipulator. A video describing our work could be found \url{https://youtu.be/hE-Ew59GRPQ}.
Can Increasing Input Dimensionality Improve Deep Reinforcement Learning?
Mar 03, 2020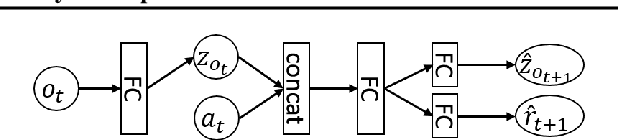

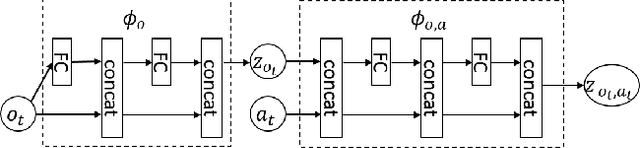
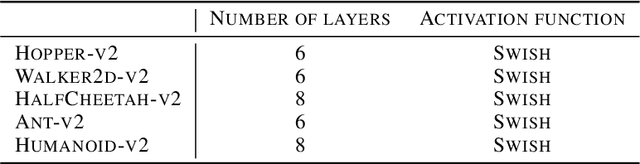
Deep reinforcement learning (RL) algorithms have recently achieved remarkable successes in various sequential decision making tasks, leveraging advances in methods for training large deep networks. However, these methods usually require large amounts of training data, which is often a big problem for real-world applications. One natural question to ask is whether learning good representations for states and using larger networks helps in learning better policies. In this paper, we try to study if increasing input dimensionality helps improve performance and sample efficiency of model-free deep RL algorithms. To do so, we propose an online feature extractor network (OFENet) that uses neural nets to produce good representations to be used as inputs to deep RL algorithms. Even though the high dimensionality of input is usually supposed to make learning of RL agents more difficult, we show that the RL agents in fact learn more efficiently with the high-dimensional representation than with the lower-dimensional state observations. We believe that stronger feature propagation together with larger networks (and thus larger search space) allows RL agents to learn more complex functions of states and thus improves the sample efficiency. Through numerical experiments, we show that the proposed method outperforms several other state-of-the-art algorithms in terms of both sample efficiency and performance.
Trajectory Optimization for Unknown Constrained Systems using Reinforcement Learning
Mar 13, 2019

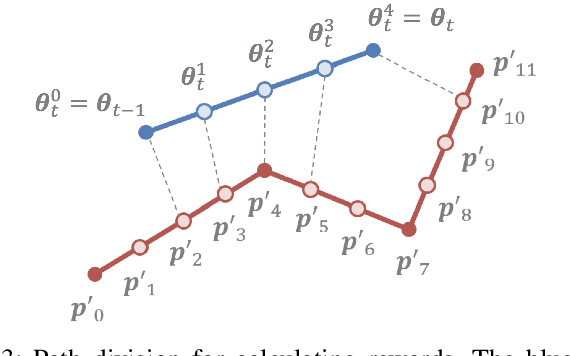
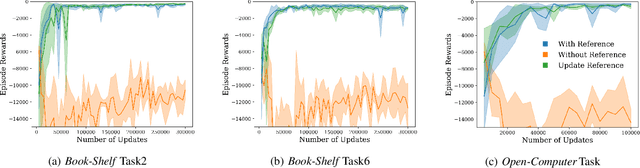
In this paper, we propose a reinforcement learning-based algorithm for trajectory optimization for constrained dynamical systems. This problem is motivated by the fact that for most robotic systems, the dynamics may not always be known. Generating smooth, dynamically feasible trajectories could be difficult for such systems. Using sampling-based algorithms for motion planning may result in trajectories that are prone to undesirable control jumps. However, they can usually provide a good reference trajectory which a model-free reinforcement learning algorithm can then exploit by limiting the search domain and quickly finding a dynamically smooth trajectory. We use this idea to train a reinforcement learning agent to learn a dynamically smooth trajectory in a curriculum learning setting. Furthermore, for generalization, we parameterize the policies with goal locations, so that the agent can be trained for multiple goals simultaneously. We show result in both simulated environments as well as real experiments, for a $6$-DoF manipulator arm operated in position-controlled mode to validate the proposed idea. We compare the proposed ideas against a PID controller which is used to track a designed trajectory in configuration space. Our experiments show that our RL agent trained with a reference path outperformed a model-free PID controller of the type commonly used on many robotic platforms for trajectory tracking.