 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascade Feature Aggregation for Human Pose Estimation
Apr 08, 2019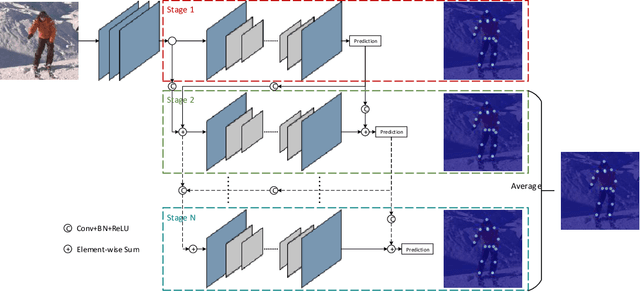
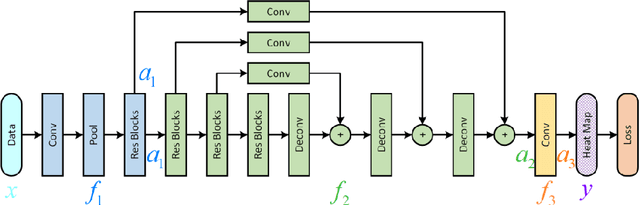
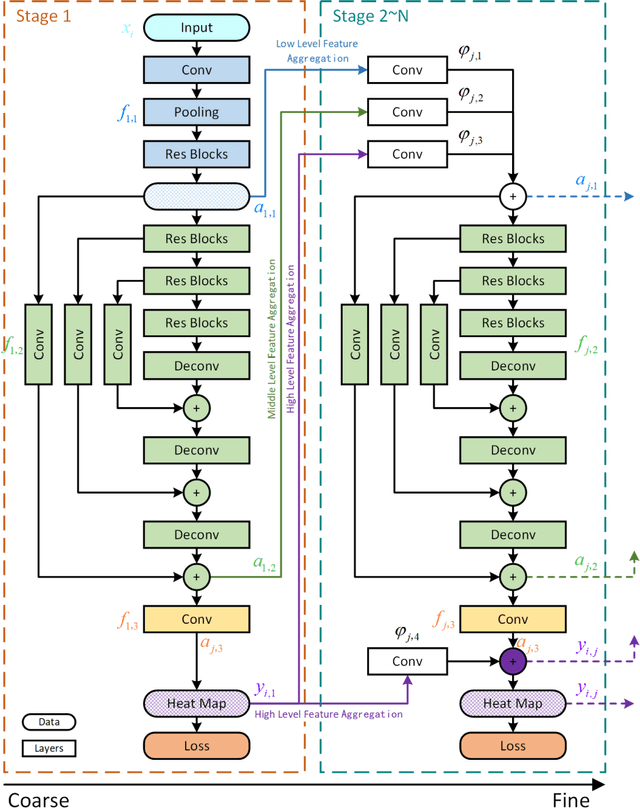
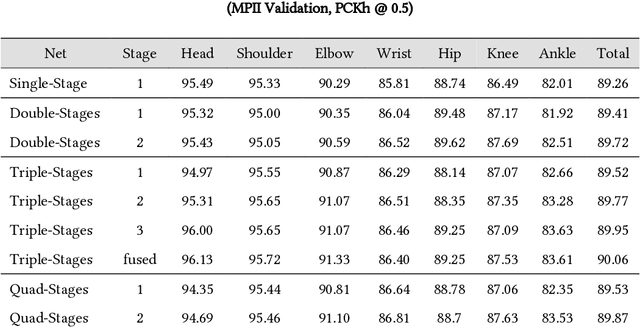
Human pose estimation plays an important role in many computer vision tasks and has been studied for many decades. However, due to complex appearance variations from poses, illuminations, occlusions and low resolutions, it still remains a challenging problem. Taking the advantage of high-level semantic information from deep convolutional neural networks is an effective way to improve the accuracy of human pose estimation. In this paper, we propose a novel Cascade Feature Aggregation (CFA) method, which cascades several hourglass networks for robust human pose estimation. Features from different stages are aggregated to obtain abundant contextual information, leading to robustness to poses, partial occlusions and low resolution. Moreover, results from different stages are fused to further improve the localization accuracy. The extensive experiments on MPII datasets and LIP datasets demonstrate that our proposed CFA outperforms the state-of-the-art and achieves the best performance on the state-of-the-art benchmark MPII.