 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Relay-Based Collaborative Framework for Optimizing Synchronization in Split Federated Learning over Wireless Networks
Mar 18, 2025


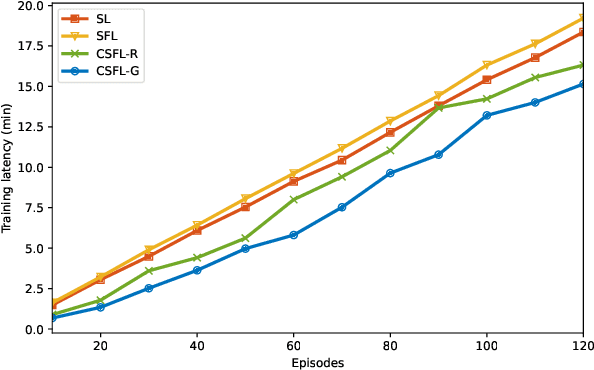
Split Federated Learning (SFL) offers a promising approach for distributed model training in edge computing, combining the strengths of split learning in reducing computational demands on edge devices and enhancing data privacy, with the role of federated aggregation to ensure model convergence and synchronization across users. However, synchronization issues caused by user heterogeneity have hindered the development of the framework. To optimize synchronization efficiency among users and improve overall system performance, we propose a collaborative SFL framework (CSFL). Based on the model's partitioning capabilities, we design a mechanism called the collaborative relay optimization mechanism (CROM), where the assistance provided by high-efficiency users is seen as a relay process, with the portion of the model they compute acting as the relay point. Wireless communication between users facilitates real-time collaboration, allowing high-efficiency users to assist bottleneck users in handling part of the model's computation, thereby alleviating the computational load on bottleneck users. Simulation results show that our proposed CSFL framework reduces synchronization delays and improves overall system throughput while maintaining similar performance and convergence rate to the SFL framework. This demonstrates that the collaboration not only reduces synchronization waiting time but also accelerates model convergence.
Personalized Class Incremental Context-Aware Food Classification for Food Intake Monitoring Systems
Mar 09, 2025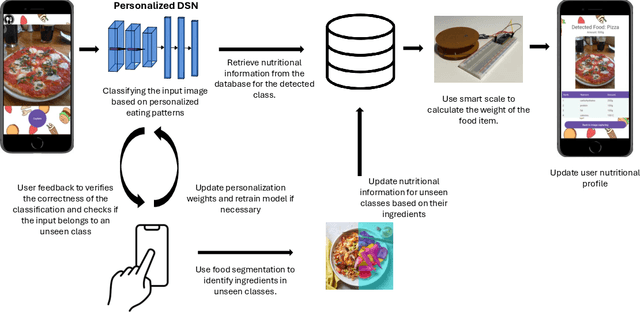
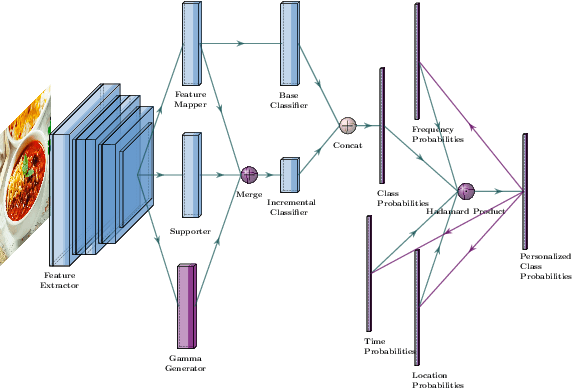
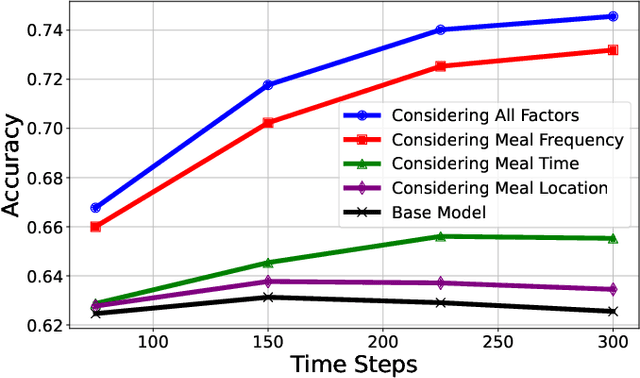
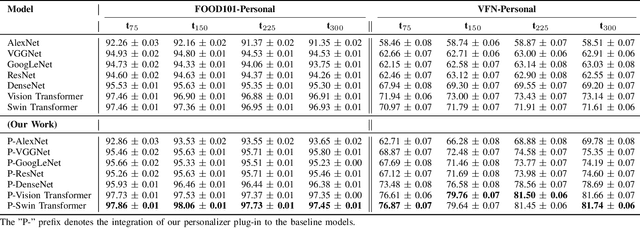
Accurate food intake monitoring is crucial for maintaining a healthy diet and preventing nutrition-related diseases. With the diverse range of foods consumed across various cultures, classic food classification models have limitations due to their reliance on fixed-sized food datasets. Studies show that people consume only a small range of foods across the existing ones, each consuming a unique set of foods. Existing class-incremental models have low accuracy for the new classes and lack personalization. This paper introduces a personalized, class-incremental food classification model designed to overcome these challenges and improve the performance of food intake monitoring systems. Our approach adapts itself to the new array of food classes, maintaining applicability and accuracy, both for new and existing classes by using personalization. Our model's primary focus is personalization, which improves classification accuracy by prioritizing a subset of foods based on an individual's eating habits, including meal frequency, times, and locations. A modified version of DSN is utilized to expand on the appearance of new food classes. Additionally, we propose a comprehensive framework that integrates this model into a food intake monitoring system. This system analyzes meal images provided by users, makes use of a smart scale to estimate food weight, utilizes a nutrient content database to calculate the amount of each macro-nutrient, and creates a dietary user profile through a mobile application. Finally, experimental evaluations on two new benchmark datasets FOOD101-Personal and VFN-Personal, personalized versions of well-known datasets for food classification, are conducted to demonstrate the effectiveness of our model in improving the classification accuracy of both new and existing classes, addressing the limitations of both conventional and class-incremental food classification models.
Towards Intelligent Transportation with Pedestrians and Vehicles In-the-Loop: A Surveillance Video-Assisted Federated Digital Twin Framework
Mar 06, 2025In intelligent transportation systems (ITSs), incorporating pedestrians and vehicles in-the-loop is crucial for developing realistic and safe traffic management solutions. However, there is falls short of simulating complex real-world ITS scenarios, primarily due to the lack of a digital twin implementation framework for characterizing interactions between pedestrians and vehicles at different locations in different traffic environments. In this article, we propose a surveillance video assisted federated digital twin (SV-FDT) framework to empower ITSs with pedestrians and vehicles in-the-loop. Specifically, SVFDT builds comprehensive pedestrian-vehicle interaction models by leveraging multi-source traffic surveillance videos. Its architecture consists of three layers: (i) the end layer, which collects traffic surveillance videos from multiple sources; (ii) the edge layer, responsible for semantic segmentation-based visual understanding, twin agent-based interaction modeling, and local digital twin system (LDTS) creation in local regions; and (iii) the cloud layer, which integrates LDTSs across different regions to construct a global DT model in realtime. We analyze key design requirements and challenges and present core guidelines for SVFDT's system implementation. A testbed evaluation demonstrates its effectiveness in optimizing traffic management. Comparisons with traditional terminal-server frameworks highlight SV-FDT's advantages in mirroring delays, recognition accuracy, and subjective evaluation. Finally, we identify some open challenges and discuss future research directions.
Edge Computing Enabled Real-Time Video Analysis via Adaptive Spatial-Temporal Semantic Filtering
Feb 29, 2024



This paper proposes a novel edge computing enabled real-time video analysis system for intelligent visual devices. The proposed system consists of a tracking-assisted object detection module (TAODM) and a region of interesting module (ROIM). TAODM adaptively determines the offloading decision to process each video frame locally with a tracking algorithm or to offload it to the edge server inferred by an object detection model. ROIM determines each offloading frame's resolution and detection model configuration to ensure that the analysis results can return in time. TAODM and ROIM interact jointly to filter the repetitive spatial-temporal semantic information to maximize the processing rate while ensuring high video analysis accuracy. Unlike most existing works, this paper investigates the real-time video analysis systems where the intelligent visual device connects to the edge server through a wireless network with fluctuating network conditions. We decompose the real-time video analysis problem into the offloading decision and configurations selection sub-problems. To solve these two sub-problems, we introduce a double deep Q network (DDQN) based offloading approach and a contextual multi-armed bandit (CMAB) based adaptive configurations selection approach, respectively. A DDQN-CMAB reinforcement learning (DCRL) training framework is further developed to integrate these two approaches to improve the overall video analyzing performance. Extensive simulations are conducted to evaluate the performance of the proposed solution, and demonstrate its superiority over counterparts.
Energy-Efficient UAV Swarm Assisted MEC with Dynamic Clustering and Scheduling
Feb 29, 2024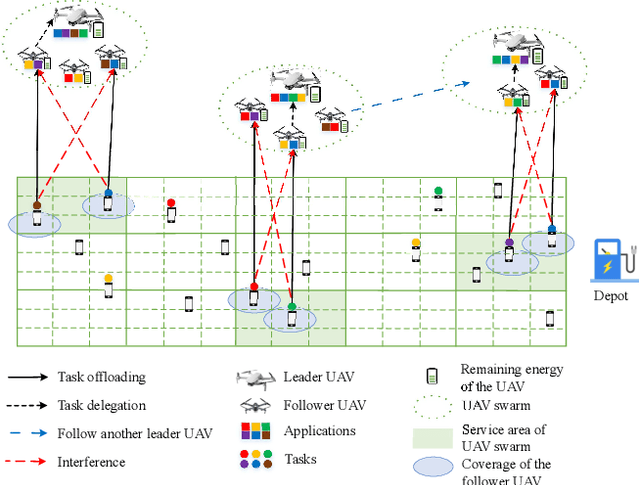
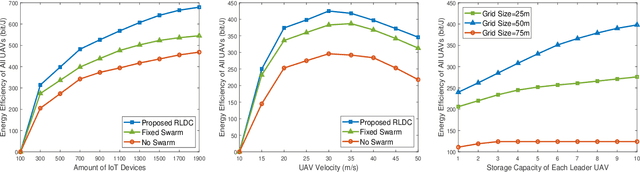
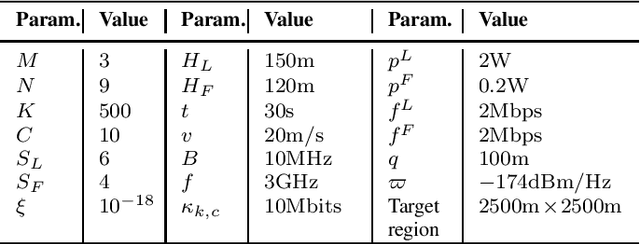
In this paper, the energy-efficient unmanned aerial vehicle (UAV) swarm assisted mobile edge computing (MEC) with dynamic clustering and scheduling is studied. In the considered system model, UAVs are divided into multiple swarms, with each swarm consisting of a leader UAV and several follower UAVs to provide computing services to end-users. Unlike existing work, we allow UAVs to dynamically cluster into different swarms, i.e., each follower UAV can change its leader based on the time-varying spatial positions, updated application placement, etc. in a dynamic manner. Meanwhile, UAVs are required to dynamically schedule their energy replenishment, application placement, trajectory planning and task delegation. With the aim of maximizing the long-term energy efficiency of the UAV swarm assisted MEC system, a joint optimization problem of dynamic clustering and scheduling is formulated. Taking into account the underlying cooperation and competition among intelligent UAVs, we further reformulate this optimization problem as a combination of a series of strongly coupled multi-agent stochastic games, and then propose a novel reinforcement learning-based UAV swarm dynamic coordination (RLDC) algorithm for obtaining the equilibrium. Simulations are conducted to evaluate the performance of the RLDC algorithm and demonstrate its superiority over counterparts.
A Revolution of Personalized Healthcare: Enabling Human Digital Twin with Mobile AIGC
Jul 22, 2023Mobile Artificial Intelligence-Generated Content (AIGC) technology refers to the adoption of AI algorithms deployed at mobile edge networks to automate the information creation process while fulfilling the requirements of end users. Mobile AIGC has recently attracted phenomenal attentions and can be a key enabling technology for an emerging application, called human digital twin (HDT). HDT empowered by the mobile AIGC is expected to revolutionize the personalized healthcare by generating rare disease data, modeling high-fidelity digital twin, building versatile testbeds, and providing 24/7 customized medical services. To promote the development of this new breed of paradigm, in this article, we propose a system architecture of mobile AIGC-driven HDT and highlight the corresponding design requirements and challenges. Moreover, we illustrate two use cases, i.e., mobile AIGC-driven HDT in customized surgery planning and personalized medication. In addition, we conduct an experimental study to prove the effectiveness of the proposed mobile AIGC-driven HDT solution, which shows a particular application in a virtual physical therapy teaching platform. Finally, we conclude this article by briefly discussing several open issues and future directions.
Active RIS-aided EH-NOMA Networks: A Deep Reinforcement Learning Approach
Apr 11, 2023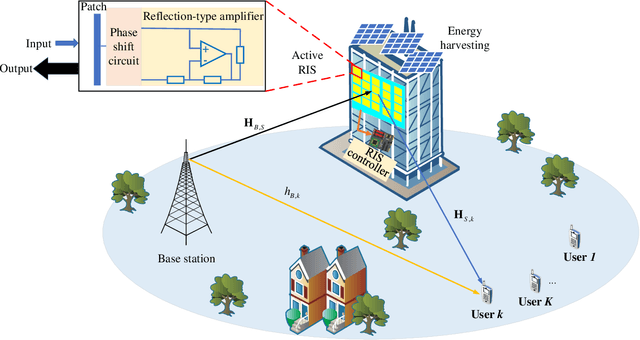
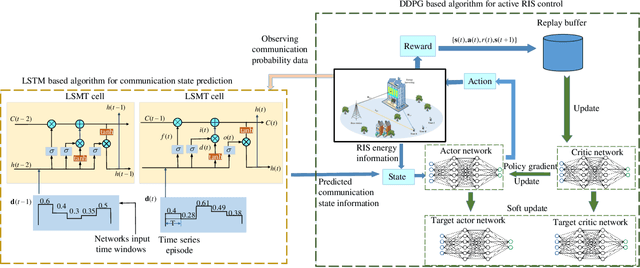
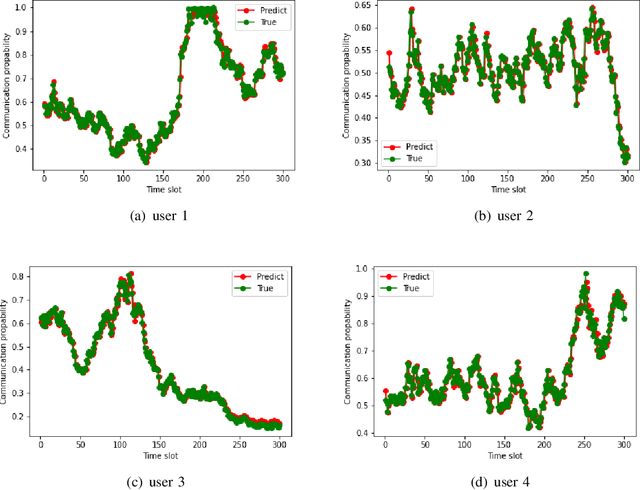
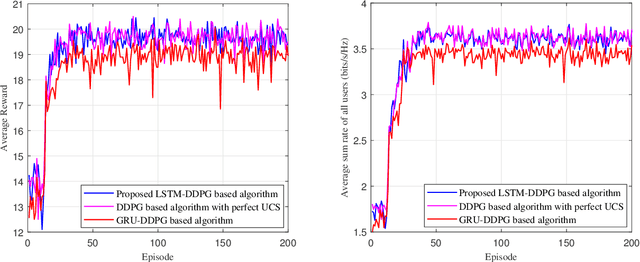
An active reconfigurable intelligent surface (RIS)-aided multi-user downlink communication system is investigated, where non-orthogonal multiple access (NOMA) is employed to improve spectral efficiency, and the active RIS is powered by energy harvesting (EH). The problem of joint control of the RIS's amplification matrix and phase shift matrix is formulated to maximize the communication success ratio with considering the quality of service (QoS) requirements of users, dynamic communication state, and dynamic available energy of RIS. To tackle this non-convex problem, a cascaded deep learning algorithm namely long short-term memory-deep deterministic policy gradient (LSTM-DDPG) is designed. First, an advanced LSTM based algorithm is developed to predict users' dynamic communication state. Then, based on the prediction results, a DDPG based algorithm is proposed to joint control the amplification matrix and phase shift matrix of the RIS. Finally, simulation results verify the accuracy of the prediction of the proposed LSTM algorithm, and demonstrate that the LSTM-DDPG algorithm has a significant advantage over other benchmark algorithms in terms of communication success ratio performance.
Outage Performance of Uplink Rate Splitting Multiple Access with Randomly Deployed Users
May 03, 2022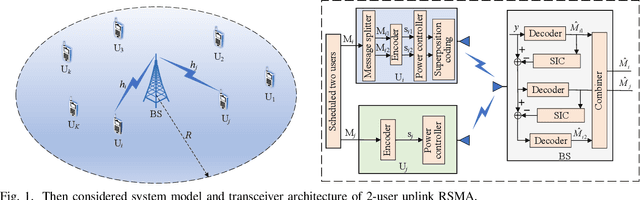
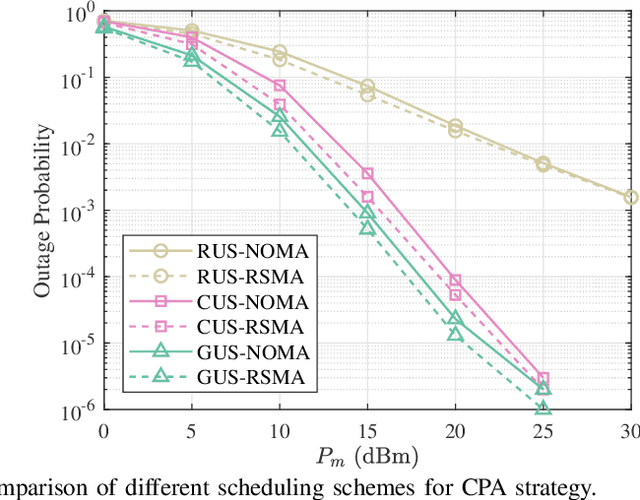
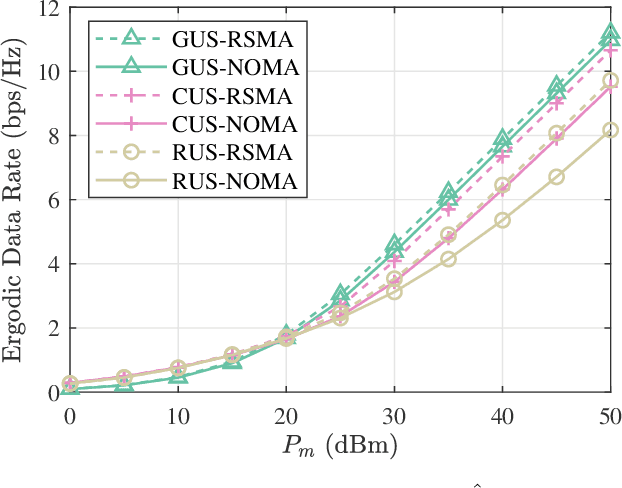
Rate splitting multiple access (RSMA) is a promising solution to improve spectral efficiency and provide better fairness for the upcoming sixth-generation (6G) networks. In this paper, the outage performance of uplink RSMA transmission with randomly deployed users is investigated, taking both user scheduling schemes and power allocation strategies into consideration. Specifically, the greedy user scheduling (GUS) and cumulative distribution function (CDF) based user scheduling (CUS) schemes are considered, which could maximize the rate performance and guarantee access fairness, respectively. Meanwhile, we re-investigate cognitive power allocation (CPA) strategy, and propose a new rate-fairness oriented power allocation (FPA) strategy to enhance the scheduled users rate fairness. By employing order statistics and stochastic geometry, an analytical expression of the outage probability for each scheduling scheme combining power allocation is derived to characterize the performance. To get more insights, the achieved diversity order of each scheme is also derived. Theoretical results demonstrate that both GUS and CUS schemes applying CPA or FPA strategy can achieve full diversity orders, and the application of CPA strategy in RSMA can effectively eliminate the secondary user's diversity order constraint from the primary user. Simulation results corroborate the accuracy of the analytical expressions, and show that the proposed FPA strategy can achieve excellent rate fairness performance in high signal-to-noise ratio region.
Deep Reinforcement Learning Based Multidimensional Resource Management for Energy Harvesting Cognitive NOMA Communications
Sep 17, 2021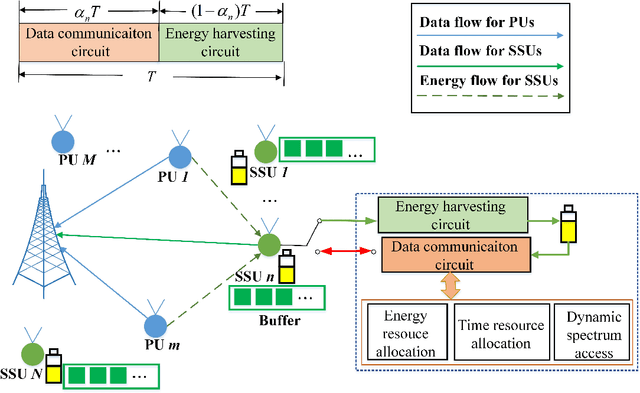
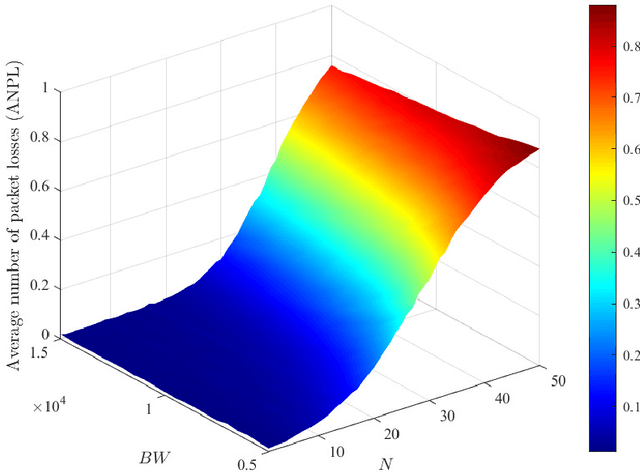
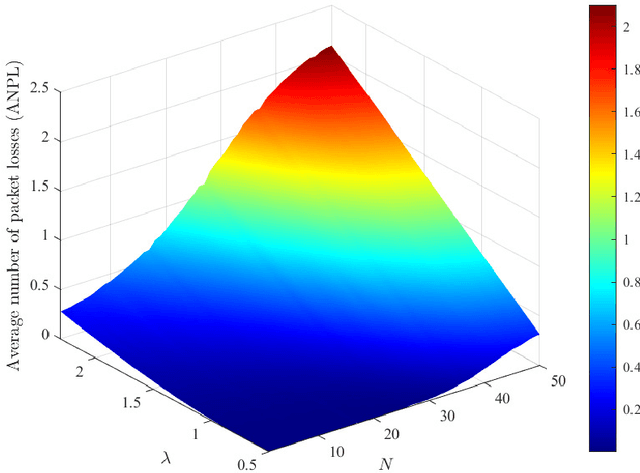
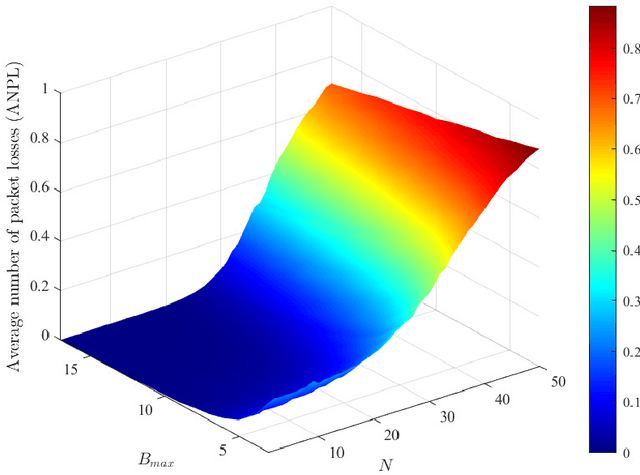
The combination of energy harvesting (EH), cognitive radio (CR), and non-orthogonal multiple access (NOMA) is a promising solution to improve energy efficiency and spectral efficiency of the upcoming beyond fifth generation network (B5G), especially for support the wireless sensor communications in Internet of things (IoT) system. However, how to realize intelligent frequency, time, and energy resource allocation to support better performances is an important problem to be solved. In this paper, we study joint spectrum, energy, and time resource management for the EH-CR-NOMA IoT systems. Our goal is to minimize the number of data packets losses for all secondary sensing users (SSU), while satisfying the constraints on the maximum charging battery capacity, maximum transmitting power, maximum buffer capacity, and minimum data rate of primary users (PU) and SSUs. Due to the non-convexity of this optimization problem and the stochastic nature of the wireless environment, we propose a distributed multidimensional resource management algorithm based on deep reinforcement learning (DRL). Considering the continuity of the resources to be managed, the deep deterministic policy gradient (DDPG) algorithm is adopted, based on which each agent (SSU) can manage its own multidimensional resources without collaboration. In addition, a simplified but practical action adjuster (AA) is introduced for improving the training efficiency and battery performance protection. The provided results show that the convergence speed of the proposed algorithm is about 4 times faster than that of DDPG, and the average number of packet losses (ANPL) is about 8 times lower than that of the greedy algorithm.