 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive RIS-aided EH-NOMA Networks: A Deep Reinforcement Learning Approach
Apr 11, 2023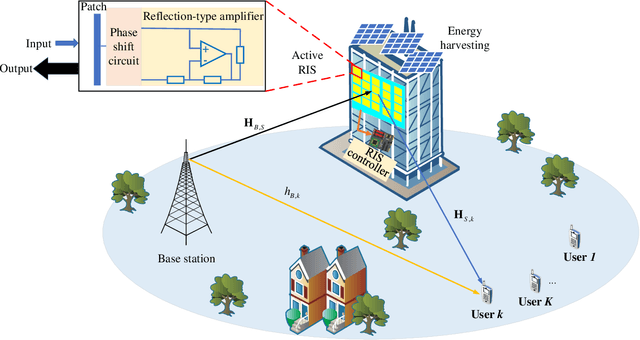
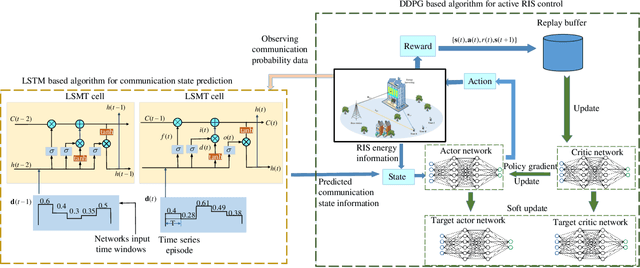
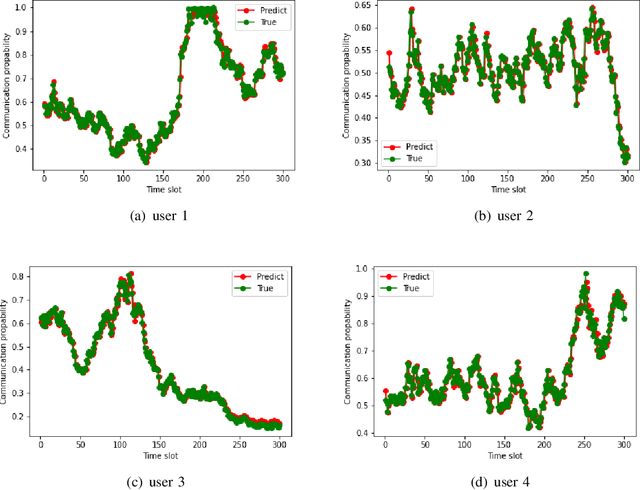
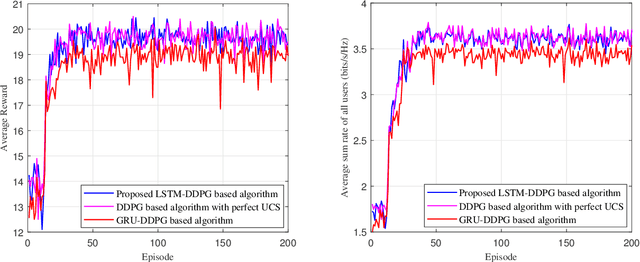
An active reconfigurable intelligent surface (RIS)-aided multi-user downlink communication system is investigated, where non-orthogonal multiple access (NOMA) is employed to improve spectral efficiency, and the active RIS is powered by energy harvesting (EH). The problem of joint control of the RIS's amplification matrix and phase shift matrix is formulated to maximize the communication success ratio with considering the quality of service (QoS) requirements of users, dynamic communication state, and dynamic available energy of RIS. To tackle this non-convex problem, a cascaded deep learning algorithm namely long short-term memory-deep deterministic policy gradient (LSTM-DDPG) is designed. First, an advanced LSTM based algorithm is developed to predict users' dynamic communication state. Then, based on the prediction results, a DDPG based algorithm is proposed to joint control the amplification matrix and phase shift matrix of the RIS. Finally, simulation results verify the accuracy of the prediction of the proposed LSTM algorithm, and demonstrate that the LSTM-DDPG algorithm has a significant advantage over other benchmark algorithms in terms of communication success ratio performance.
Deep Reinforcement Learning Based Multidimensional Resource Management for Energy Harvesting Cognitive NOMA Communications
Sep 17, 2021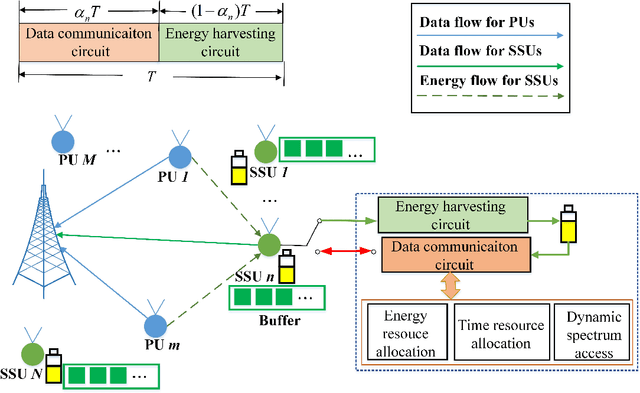
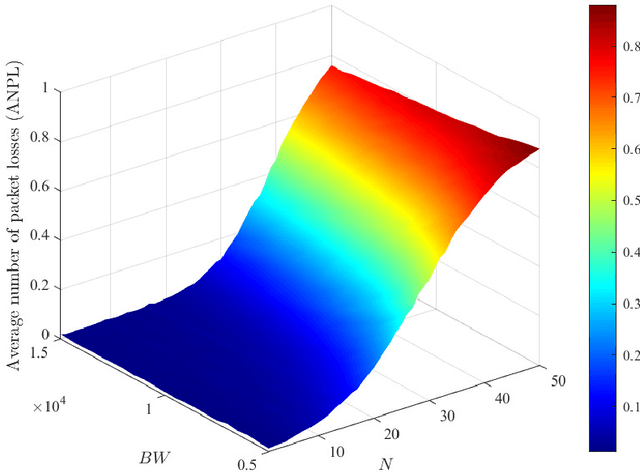
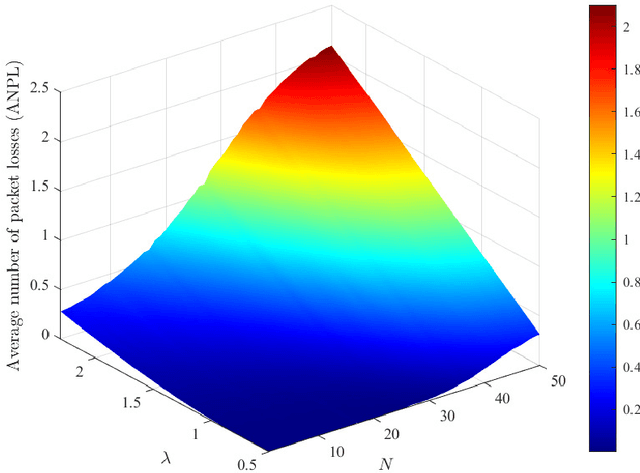
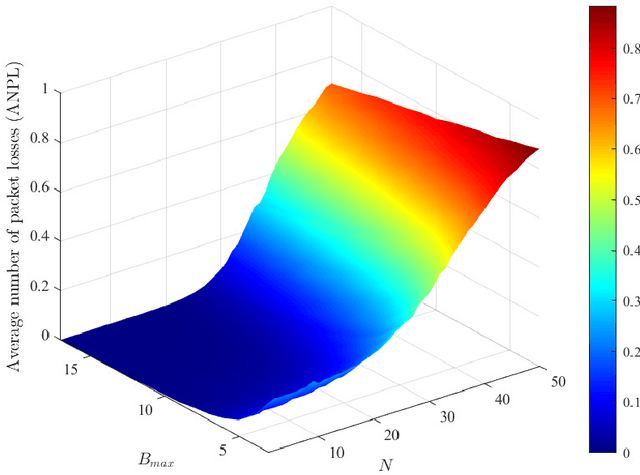
The combination of energy harvesting (EH), cognitive radio (CR), and non-orthogonal multiple access (NOMA) is a promising solution to improve energy efficiency and spectral efficiency of the upcoming beyond fifth generation network (B5G), especially for support the wireless sensor communications in Internet of things (IoT) system. However, how to realize intelligent frequency, time, and energy resource allocation to support better performances is an important problem to be solved. In this paper, we study joint spectrum, energy, and time resource management for the EH-CR-NOMA IoT systems. Our goal is to minimize the number of data packets losses for all secondary sensing users (SSU), while satisfying the constraints on the maximum charging battery capacity, maximum transmitting power, maximum buffer capacity, and minimum data rate of primary users (PU) and SSUs. Due to the non-convexity of this optimization problem and the stochastic nature of the wireless environment, we propose a distributed multidimensional resource management algorithm based on deep reinforcement learning (DRL). Considering the continuity of the resources to be managed, the deep deterministic policy gradient (DDPG) algorithm is adopted, based on which each agent (SSU) can manage its own multidimensional resources without collaboration. In addition, a simplified but practical action adjuster (AA) is introduced for improving the training efficiency and battery performance protection. The provided results show that the convergence speed of the proposed algorithm is about 4 times faster than that of DDPG, and the average number of packet losses (ANPL) is about 8 times lower than that of the greedy algorithm.
Intelligent Reflecting Surface Assisted Anti-Jamming Communications Based on Reinforcement Learning
Dec 23, 2020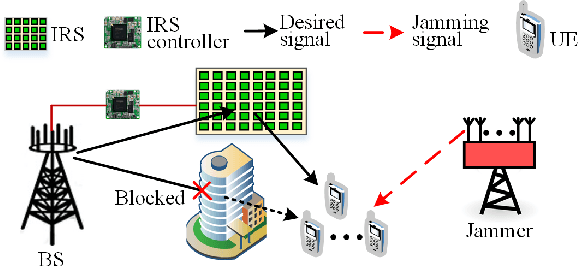
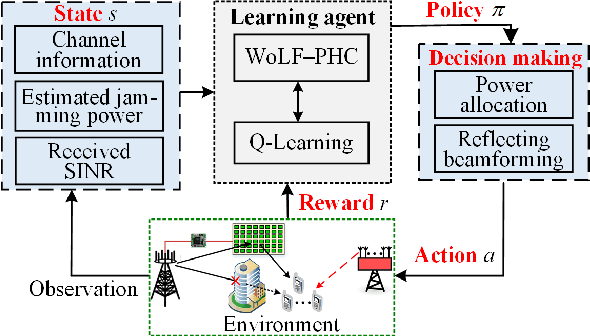
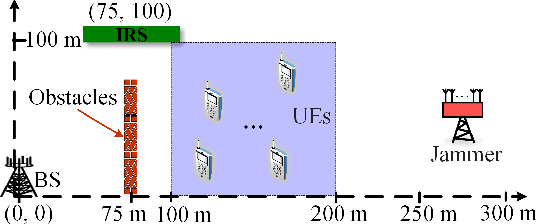
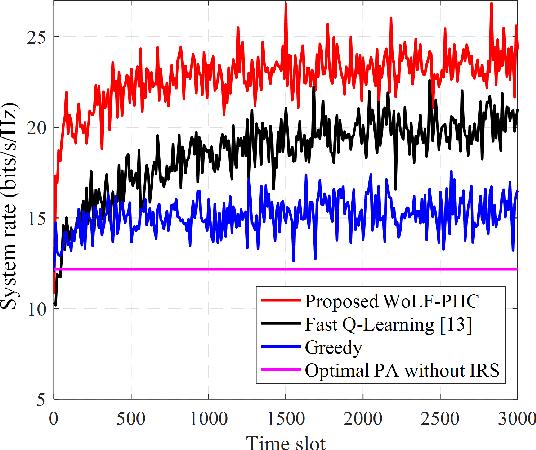
Malicious jamming launched by smart jammer, which attacks legitimate transmissions has been regarded as one of the critical security challenges in wireless communications. Thus, this paper exploits intelligent reflecting surface (IRS) to enhance anti-jamming communication performance and mitigate jamming interference by adjusting the surface reflecting elements at the IRS. Aiming to enhance the communication performance against smart jammer, an optimization problem for jointly optimizing power allocation at the base station (BS) and reflecting beamforming at the IRS is formulated. As the jamming model and jamming behavior are dynamic and unknown, a win or learn fast policy hill-climbing (WoLF-PHC) learning approach is proposed to jointly optimize the anti-jamming power allocation and reflecting beamforming strategy without the knowledge of the jamming model. Simulation results demonstrate that the proposed anti-jamming based-learning approach can efficiently improve both the IRS-assisted system rate and transmission protection level compared with existing solutions.
Privacy-Preserving Federated Learning for UAV-Enabled Networks: Learning-Based Joint Scheduling and Resource Management
Nov 28, 2020

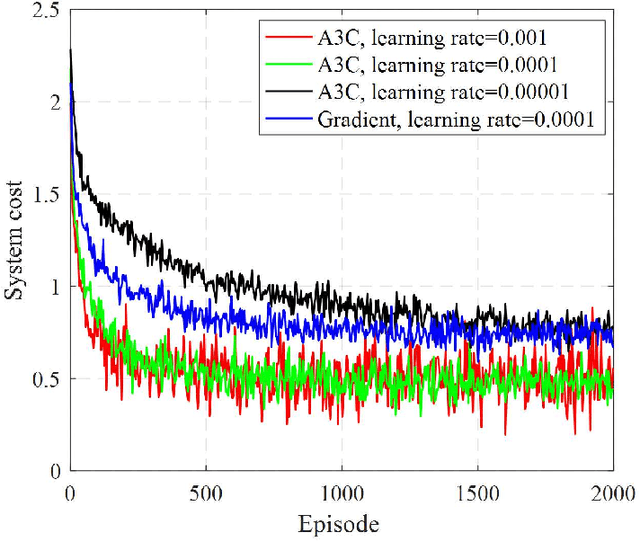

Unmanned aerial vehicles (UAVs) are capable of serving as flying base stations (BSs) for supporting data collection, artificial intelligence (AI) model training, and wireless communications. However, due to the privacy concerns of devices and limited computation or communication resource of UAVs, it is impractical to send raw data of devices to UAV servers for model training. Moreover, due to the dynamic channel condition and heterogeneous computing capacity of devices in UAV-enabled networks, the reliability and efficiency of data sharing require to be further improved. In this paper, we develop an asynchronous federated learning (AFL) framework for multi-UAV-enabled networks, which can provide asynchronous distributed computing by enabling model training locally without transmitting raw sensitive data to UAV servers. The device selection strategy is also introduced into the AFL framework to keep the low-quality devices from affecting the learning efficiency and accuracy. Moreover, we propose an asynchronous advantage actor-critic (A3C) based joint device selection, UAVs placement, and resource management algorithm to enhance the federated convergence speed and accuracy. Simulation results demonstrate that our proposed framework and algorithm achieve higher learning accuracy and faster federated execution time compared to other existing solutions.