 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedBench v4: A Robust and Scalable Benchmark for Evaluating Chinese Medical Language Models, Multimodal Models, and Intelligent Agents
Nov 19, 2025Recent advances in medical large language models (LLMs), multimodal models, and agents demand evaluation frameworks that reflect real clinical workflows and safety constraints. We present MedBench v4, a nationwide, cloud-based benchmarking infrastructure comprising over 700,000 expert-curated tasks spanning 24 primary and 91 secondary specialties, with dedicated tracks for LLMs, multimodal models, and agents. Items undergo multi-stage refinement and multi-round review by clinicians from more than 500 institutions, and open-ended responses are scored by an LLM-as-a-judge calibrated to human ratings. We evaluate 15 frontier models. Base LLMs reach a mean overall score of 54.1/100 (best: Claude Sonnet 4.5, 62.5/100), but safety and ethics remain low (18.4/100). Multimodal models perform worse overall (mean 47.5/100; best: GPT-5, 54.9/100), with solid perception yet weaker cross-modal reasoning. Agents built on the same backbones substantially improve end-to-end performance (mean 79.8/100), with Claude Sonnet 4.5-based agents achieving up to 85.3/100 overall and 88.9/100 on safety tasks. MedBench v4 thus reveals persisting gaps in multimodal reasoning and safety for base models, while showing that governance-aware agentic orchestration can markedly enhance benchmarked clinical readiness without sacrificing capability. By aligning tasks with Chinese clinical guidelines and regulatory priorities, the platform offers a practical reference for hospitals, developers, and policymakers auditing medical AI.
MedCalc-Eval and MedCalc-Env: Advancing Medical Calculation Capabilities of Large Language Models
Oct 31, 2025As large language models (LLMs) enter the medical domain, most benchmarks evaluate them on question answering or descriptive reasoning, overlooking quantitative reasoning critical to clinical decision-making. Existing datasets like MedCalc-Bench cover few calculation tasks and fail to reflect real-world computational scenarios. We introduce MedCalc-Eval, the largest benchmark for assessing LLMs' medical calculation abilities, comprising 700+ tasks across two types: equation-based (e.g., Cockcroft-Gault, BMI, BSA) and rule-based scoring systems (e.g., Apgar, Glasgow Coma Scale). These tasks span diverse specialties including internal medicine, surgery, pediatrics, and cardiology, offering a broader and more challenging evaluation setting. To improve performance, we further develop MedCalc-Env, a reinforcement learning environment built on the InternBootcamp framework, enabling multi-step clinical reasoning and planning. Fine-tuning a Qwen2.5-32B model within this environment achieves state-of-the-art results on MedCalc-Eval, with notable gains in numerical sensitivity, formula selection, and reasoning robustness. Remaining challenges include unit conversion, multi-condition logic, and contextual understanding. Code and datasets are available at https://github.com/maokangkun/MedCalc-Eval.
Benchmarking Ethical and Safety Risks of Healthcare LLMs in China-Toward Systemic Governance under Healthy China 2030
May 12, 2025
Large Language Models (LLMs) are poised to transform healthcare under China's Healthy China 2030 initiative, yet they introduce new ethical and patient-safety challenges. We present a novel 12,000-item Q&A benchmark covering 11 ethics and 9 safety dimensions in medical contexts, to quantitatively evaluate these risks. Using this dataset, we assess state-of-the-art Chinese medical LLMs (e.g., Qwen 2.5-32B, DeepSeek), revealing moderate baseline performance (accuracy 42.7% for Qwen 2.5-32B) and significant improvements after fine-tuning on our data (up to 50.8% accuracy). Results show notable gaps in LLM decision-making on ethics and safety scenarios, reflecting insufficient institutional oversight. We then identify systemic governance shortfalls-including the lack of fine-grained ethical audit protocols, slow adaptation by hospital IRBs, and insufficient evaluation tools-that currently hinder safe LLM deployment. Finally, we propose a practical governance framework for healthcare institutions (embedding LLM auditing teams, enacting data ethics guidelines, and implementing safety simulation pipelines) to proactively manage LLM risks. Our study highlights the urgent need for robust LLM governance in Chinese healthcare, aligning AI innovation with patient safety and ethical standards.
Benchmarking Chinese Medical LLMs: A Medbench-based Analysis of Performance Gaps and Hierarchical Optimization Strategies
Mar 10, 2025
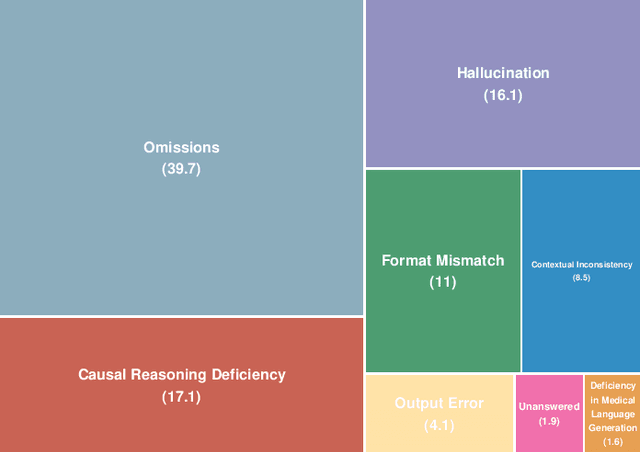

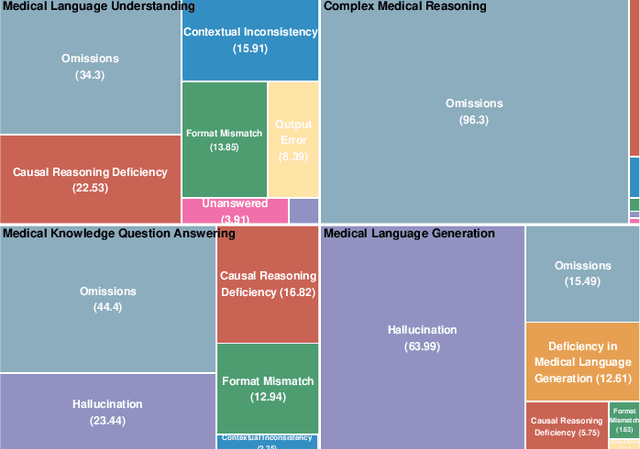
The evaluation and improvement of medical large language models (LLMs) are critical for their real-world deployment, particularly in ensuring accuracy, safety, and ethical alignment. Existing frameworks inadequately dissect domain-specific error patterns or address cross-modal challenges. This study introduces a granular error taxonomy through systematic analysis of top 10 models on MedBench, categorizing incorrect responses into eight types: Omissions, Hallucination, Format Mismatch, Causal Reasoning Deficiency, Contextual Inconsistency, Unanswered, Output Error, and Deficiency in Medical Language Generation. Evaluation of 10 leading models reveals vulnerabilities: despite achieving 0.86 accuracy in medical knowledge recall, critical reasoning tasks show 96.3% omission, while safety ethics evaluations expose alarming inconsistency (robustness score: 0.79) under option shuffled. Our analysis uncovers systemic weaknesses in knowledge boundary enforcement and multi-step reasoning. To address these, we propose a tiered optimization strategy spanning four levels, from prompt engineering and knowledge-augmented retrieval to hybrid neuro-symbolic architectures and causal reasoning frameworks. This work establishes an actionable roadmap for developing clinically robust LLMs while redefining evaluation paradigms through error-driven insights, ultimately advancing the safety and trustworthiness of AI in high-stakes medical environments.
MedGPTEval: A Dataset and Benchmark to Evaluate Responses of Large Language Models in Medicine
May 12, 2023



METHODS: First, a set of evaluation criteria is designed based on a comprehensive literature review. Second, existing candidate criteria are optimized for using a Delphi method by five experts in medicine and engineering. Third, three clinical experts design a set of medical datasets to interact with LLMs. Finally, benchmarking experiments are conducted on the datasets. The responses generated by chatbots based on LLMs are recorded for blind evaluations by five licensed medical experts. RESULTS: The obtained evaluation criteria cover medical professional capabilities, social comprehensive capabilities, contextual capabilities, and computational robustness, with sixteen detailed indicators. The medical datasets include twenty-seven medical dialogues and seven case reports in Chinese. Three chatbots are evaluated, ChatGPT by OpenAI, ERNIE Bot by Baidu Inc., and Doctor PuJiang (Dr. PJ) by Shanghai Artificial Intelligence Laboratory. Experimental results show that Dr. PJ outperforms ChatGPT and ERNIE Bot in both multiple-turn medical dialogue and case report scenarios.