 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedRIR: Rethinking Information Representation in Federated Learning
Feb 02, 2025Mobile and Web-of-Things (WoT) devices at the network edge generate vast amounts of data for machine learning applications, yet privacy concerns hinder centralized model training. Federated Learning (FL) allows clients (devices) to collaboratively train a shared model coordinated by a central server without transfer private data, but inherent statistical heterogeneity among clients presents challenges, often leading to a dilemma between clients' needs for personalized local models and the server's goal of building a generalized global model. Existing FL methods typically prioritize either global generalization or local personalization, resulting in a trade-off between these two objectives and limiting the full potential of diverse client data. To address this challenge, we propose a novel framework that simultaneously enhances global generalization and local personalization by Rethinking Information Representation in the Federated learning process (FedRIR). Specifically, we introduce Masked Client-Specific Learning (MCSL), which isolates and extracts fine-grained client-specific features tailored to each client's unique data characteristics, thereby enhancing personalization. Concurrently, the Information Distillation Module (IDM) refines the global shared features by filtering out redundant client-specific information, resulting in a purer and more robust global representation that enhances generalization. By integrating the refined global features with the isolated client-specific features, we construct enriched representations that effectively capture both global patterns and local nuances, thereby improving the performance of downstream tasks on the client. The code is available at https://github.com/Deep-Imaging-Group/FedRIR.
Energizing Federated Learning via Filter-Aware Attention
Nov 18, 2023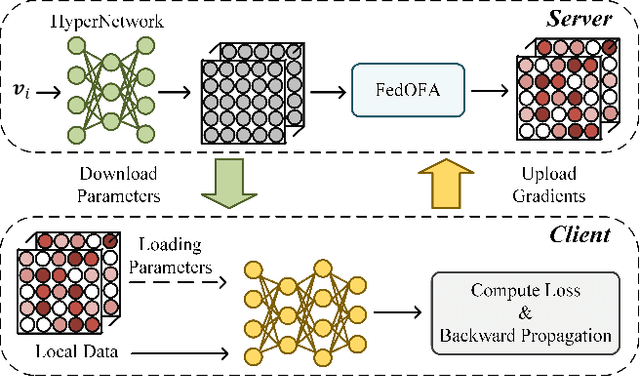
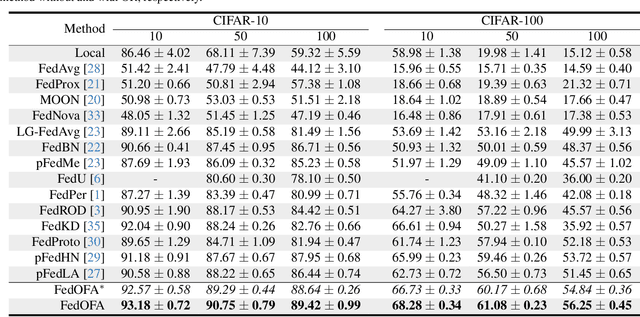
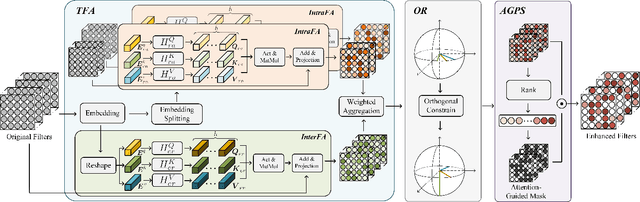
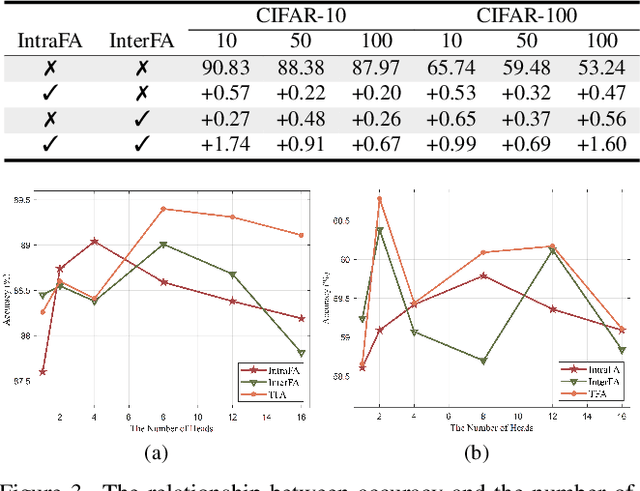
Federated learning (FL) is a promising distributed paradigm, eliminating the need for data sharing but facing challenges from data heterogeneity. Personalized parameter generation through a hypernetwork proves effective, yet existing methods fail to personalize local model structures. This leads to redundant parameters struggling to adapt to diverse data distributions. To address these limitations, we propose FedOFA, utilizing personalized orthogonal filter attention for parameter recalibration. The core is the Two-stream Filter-aware Attention (TFA) module, meticulously designed to extract personalized filter-aware attention maps, incorporating Intra-Filter Attention (IntraFa) and Inter-Filter Attention (InterFA) streams. These streams enhance representation capability and explore optimal implicit structures for local models. Orthogonal regularization minimizes redundancy by averting inter-correlation between filters. Furthermore, we introduce an Attention-Guided Pruning Strategy (AGPS) for communication efficiency. AGPS selectively retains crucial neurons while masking redundant ones, reducing communication costs without performance sacrifice. Importantly, FedOFA operates on the server side, incurring no additional computational cost on the client, making it advantageous in communication-constrained scenarios. Extensive experiments validate superior performance over state-of-the-art approaches, with code availability upon paper acceptance.
FedCliP: Federated Learning with Client Pruning
Jan 17, 2023


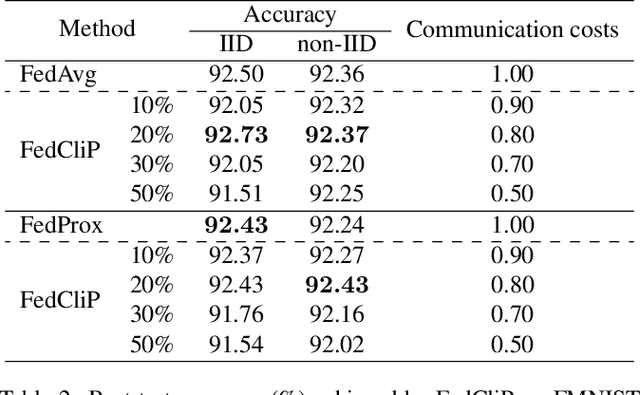
Federated learning (FL) is a newly emerging distributed learning paradigm that allows numerous participating clients to train machine learning models collaboratively, each with its data distribution and without sharing their data. One fundamental bottleneck in FL is the heavy communication overheads of high-dimensional models between the distributed clients and the central server. Previous works often condense models into compact formats by gradient compression or distillation to overcome communication limitations. In contrast, we propose FedCliP in this work, the first communication efficient FL training framework from a macro perspective, which can position valid clients participating in FL quickly and constantly prune redundant clients. Specifically, We first calculate the reliability score based on the training loss and model divergence as an indicator to measure the client pruning. We propose a valid client determination approximation framework based on the reliability score with Gaussian Scale Mixture (GSM) modeling for federated participating clients pruning. Besides, we develop a communication efficient client pruning training method in the FL scenario. Experimental results on MNIST dataset show that FedCliP has up to 10%~70% communication costs for converged models at only a 0.2% loss in accuracy.
Hyper RPCA: Joint Maximum Correntropy Criterion and Laplacian Scale Mixture Modeling On-the-Fly for Moving Object Detection
Jun 14, 2020
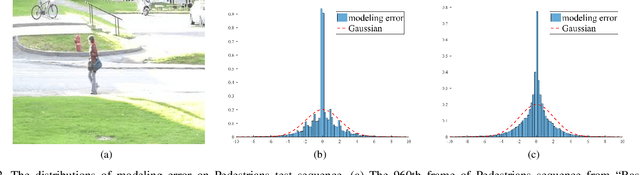

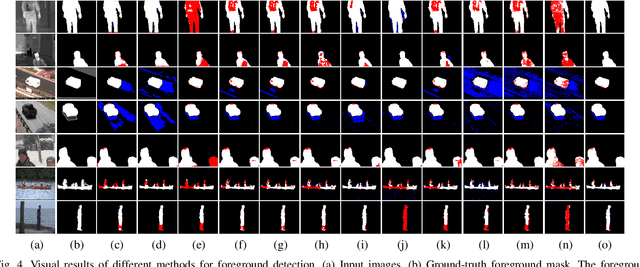
Moving object detection is critical for automated video analysis in many vision-related tasks, such as surveillance tracking, video compression coding, etc. Robust Principal Component Analysis (RPCA), as one of the most popular moving object modelling methods, aims to separate the temporally varying (i.e., moving) foreground objects from the static background in video, assuming the background frames to be low-rank while the foreground to be spatially sparse. Classic RPCA imposes sparsity of the foreground component using l1-norm, and minimizes the modeling error via 2-norm. We show that such assumptions can be too restrictive in practice, which limits the effectiveness of the classic RPCA, especially when processing videos with dynamic background, camera jitter, camouflaged moving object, etc. In this paper, we propose a novel RPCA-based model, called Hyper RPCA, to detect moving objects on the fly. Different from classic RPCA, the proposed Hyper RPCA jointly applies the maximum correntropy criterion (MCC) for the modeling error, and Laplacian scale mixture (LSM) model for foreground objects. Extensive experiments have been conducted, and the results demonstrate that the proposed Hyper RPCA has competitive performance for foreground detection to the state-of-the-art algorithms on several well-known benchmark datasets.