 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Knowledge Identification and Fusion for Language Model Continual Learning
Feb 22, 2025Continual learning (CL) is crucial for deploying large language models (LLMs) in dynamic real-world environments without costly retraining. While recent model ensemble and model merging methods guided by parameter importance have gained popularity, they often struggle to balance knowledge transfer and forgetting, mainly due to the reliance on static importance estimates during sequential training. In this paper, we present Recurrent-KIF, a novel CL framework for Recurrent Knowledge Identification and Fusion, which enables dynamic estimation of parameter importance distributions to enhance knowledge transfer. Inspired by human continual learning, Recurrent-KIF employs an inner loop that rapidly adapts to new tasks while identifying important parameters, coupled with an outer loop that globally manages the fusion of new and historical knowledge through redundant knowledge pruning and key knowledge merging. These inner-outer loops iteratively perform multiple rounds of fusion, allowing Recurrent-KIF to leverage intermediate training information and adaptively adjust fusion strategies based on evolving importance distributions. Extensive experiments on two CL benchmarks with various model sizes (from 770M to 13B) demonstrate that Recurrent-KIF effectively mitigates catastrophic forgetting and enhances knowledge transfer.
MALoRA: Mixture of Asymmetric Low-Rank Adaptation for Enhanced Multi-Task Learning
Oct 30, 2024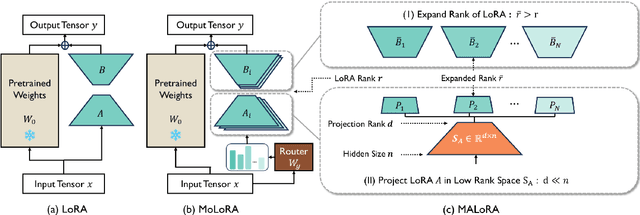

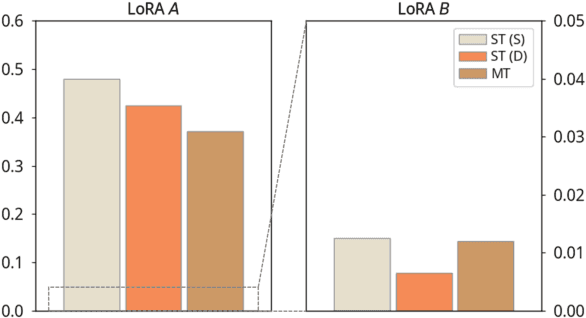

Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA have significantly improved the adaptation of LLMs to downstream tasks in a resource-efficient manner. However, in multi-task scenarios, challenges such as training imbalance and the seesaw effect frequently emerge. Mixture-of-LoRA (MoLoRA), which combines LoRA with sparse Mixture-of-Experts, mitigates some of these issues by promoting task-specific learning across experts. Despite this, MoLoRA remains inefficient in terms of training speed, parameter utilization, and overall multi-task performance. In this paper, we propose Mixture of Asymmetric Low-Rank Adaptaion (MALoRA), a flexible fine-tuning framework that leverages asymmetric optimization across LoRA experts. MALoRA reduces the number of trainable parameters by 30% to 48%, increases training speed by 1.2x, and matches the computational efficiency of single-task LoRA models. Additionally, MALoRA addresses overfitting issues commonly seen in high-rank configurations, enhancing performance stability. Extensive experiments across diverse multi-task learning scenarios demonstrate that MALoRA consistently outperforms all baseline methods in both inter-domain and intra-domain tasks.
UltraLink: An Open-Source Knowledge-Enhanced Multilingual Supervised Fine-tuning Dataset
Feb 18, 2024



Open-source large language models (LLMs) have gained significant strength across diverse fields. Nevertheless, the majority of studies primarily concentrate on English, with only limited exploration into the realm of multilingual abilities. In this work, we therefore construct an open-source multilingual supervised fine-tuning dataset. Different from previous works that simply translate English instructions, we consider both the language-specific and language-agnostic abilities of LLMs. Firstly, we introduce a knowledge-grounded data augmentation approach to elicit more language-specific knowledge of LLMs, improving their ability to serve users from different countries. Moreover, we find modern LLMs possess strong cross-lingual transfer capabilities, thus repeatedly learning identical content in various languages is not necessary. Consequently, we can substantially prune the language-agnostic supervised fine-tuning (SFT) data without any performance degradation, making multilingual SFT more efficient. The resulting UltraLink dataset comprises approximately 1 million samples across five languages (i.e., En, Zh, Ru, Fr, Es), and the proposed data construction method can be easily extended to other languages. UltraLink-LM, which is trained on UltraLink, outperforms several representative baselines across many tasks.