 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMALoRA: Mixture of Asymmetric Low-Rank Adaptation for Enhanced Multi-Task Learning
Paper and Code
Oct 30, 2024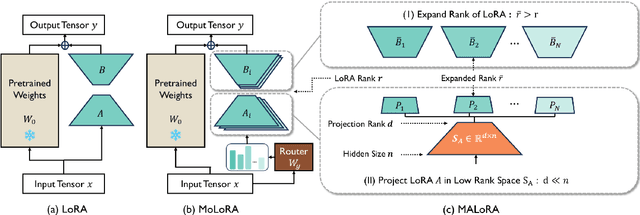

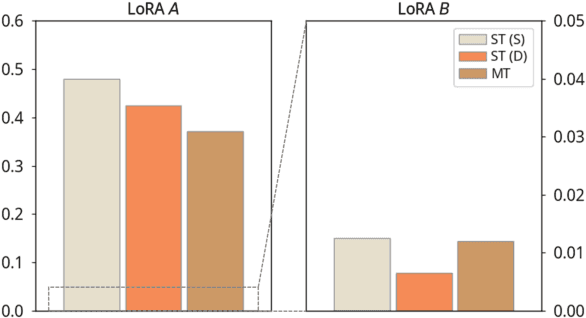

Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA have significantly improved the adaptation of LLMs to downstream tasks in a resource-efficient manner. However, in multi-task scenarios, challenges such as training imbalance and the seesaw effect frequently emerge. Mixture-of-LoRA (MoLoRA), which combines LoRA with sparse Mixture-of-Experts, mitigates some of these issues by promoting task-specific learning across experts. Despite this, MoLoRA remains inefficient in terms of training speed, parameter utilization, and overall multi-task performance. In this paper, we propose Mixture of Asymmetric Low-Rank Adaptaion (MALoRA), a flexible fine-tuning framework that leverages asymmetric optimization across LoRA experts. MALoRA reduces the number of trainable parameters by 30% to 48%, increases training speed by 1.2x, and matches the computational efficiency of single-task LoRA models. Additionally, MALoRA addresses overfitting issues commonly seen in high-rank configurations, enhancing performance stability. Extensive experiments across diverse multi-task learning scenarios demonstrate that MALoRA consistently outperforms all baseline methods in both inter-domain and intra-domain tasks.