 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransFlower: An Explainable Transformer-Based Model with Flow-to-Flow Attention for Commuting Flow Prediction
Feb 23, 2024Understanding the link between urban planning and commuting flows is crucial for guiding urban development and policymaking. This research, bridging computer science and urban studies, addresses the challenge of integrating these fields with their distinct focuses. Traditional urban studies methods, like the gravity and radiation models, often underperform in complex scenarios due to their limited handling of multiple variables and reliance on overly simplistic and unrealistic assumptions, such as spatial isotropy. While deep learning models offer improved accuracy, their black-box nature poses a trade-off between performance and explainability -- both vital for analyzing complex societal phenomena like commuting flows. To address this, we introduce TransFlower, an explainable, transformer-based model employing flow-to-flow attention to predict urban commuting patterns. It features a geospatial encoder with an anisotropy-aware relative location encoder for nuanced flow representation. Following this, the transformer-based flow predictor enhances this by leveraging attention mechanisms to efficiently capture flow interactions. Our model outperforms existing methods by up to 30.8% Common Part of Commuters, offering insights into mobility dynamics crucial for urban planning and policy decisions.
Timestamps as Prompts for Geography-Aware Location Recommendation
Apr 09, 2023Location recommendation plays a vital role in improving users' travel experience. The timestamp of the POI to be predicted is of great significance, since a user will go to different places at different times. However, most existing methods either do not use this kind of temporal information, or just implicitly fuse it with other contextual information. In this paper, we revisit the problem of location recommendation and point out that explicitly modeling temporal information is a great help when the model needs to predict not only the next location but also further locations. In addition, state-of-the-art methods do not make effective use of geographic information and suffer from the hard boundary problem when encoding geographic information by gridding. To this end, a Temporal Prompt-based and Geography-aware (TPG) framework is proposed. The temporal prompt is firstly designed to incorporate temporal information of any further check-in. A shifted window mechanism is then devised to augment geographic data for addressing the hard boundary problem. Via extensive comparisons with existing methods and ablation studies on five real-world datasets, we demonstrate the effectiveness and superiority of the proposed method under various settings. Most importantly, our proposed model has the superior ability of interval prediction. In particular, the model can predict the location that a user wants to go to at a certain time while the most recent check-in behavioral data is masked, or it can predict specific future check-in (not just the next one) at a given timestamp.
End-to-End Personalized Next Location Recommendation via Contrastive User Preference Modeling
Mar 22, 2023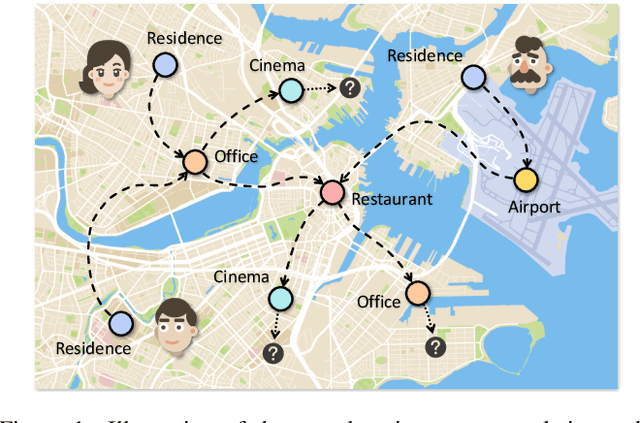
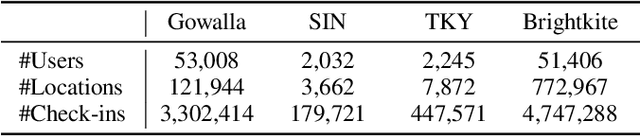
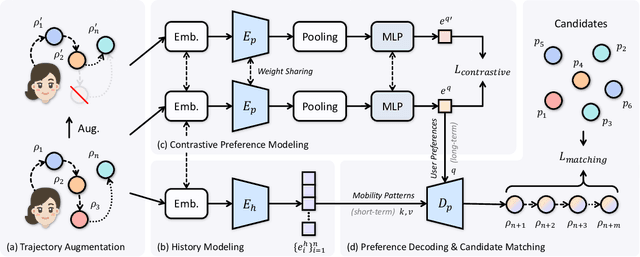
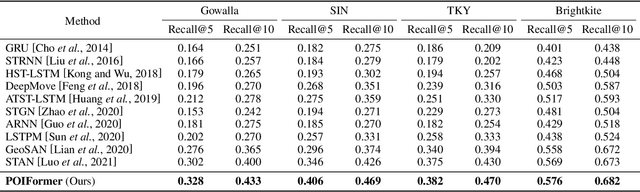
Predicting the next location is a highly valuable and common need in many location-based services such as destination prediction and route planning. The goal of next location recommendation is to predict the next point-of-interest a user might go to based on the user's historical trajectory. Most existing models learn mobility patterns merely from users' historical check-in sequences while overlooking the significance of user preference modeling. In this work, a novel Point-of-Interest Transformer (POIFormer) with contrastive user preference modeling is developed for end-to-end next location recommendation. This model consists of three major modules: history encoder, query generator, and preference decoder. History encoder is designed to model mobility patterns from historical check-in sequences, while query generator explicitly learns user preferences to generate user-specific intention queries. Finally, preference decoder combines the intention queries and historical information to predict the user's next location. Extensive comparisons with representative schemes and ablation studies on four real-world datasets demonstrate the effectiveness and superiority of the proposed scheme under various settings.
Against Adversarial Learning: Naturally Distinguish Known and Unknown in Open Set Domain Adaptation
Nov 04, 2020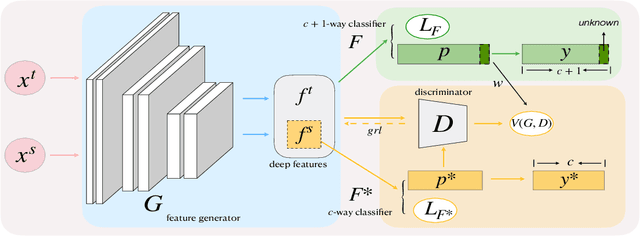
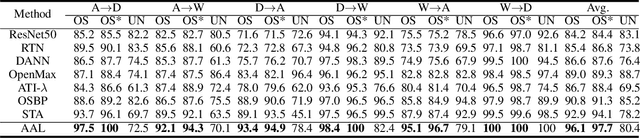
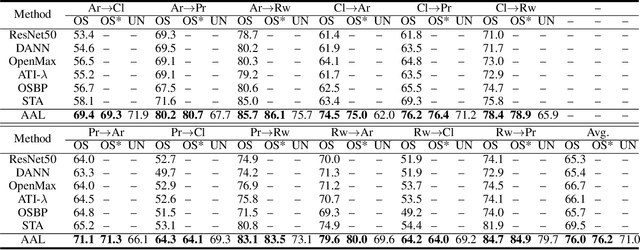
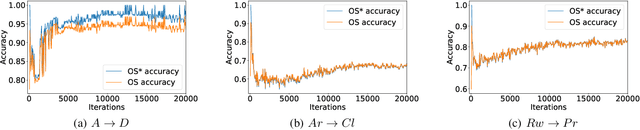
Open set domain adaptation refers to the scenario that the target domain contains categories that do not exist in the source domain. It is a more common situation in the reality compared with the typical closed set domain adaptation where the source domain and the target domain contain the same categories. The main difficulty of open set domain adaptation is that we need to distinguish which target data belongs to the unknown classes when machine learning models only have concepts about what they know. In this paper, we propose an "against adversarial learning" method that can distinguish unknown target data and known data naturally without setting any additional hyper parameters and the target data predicted to the known classes can be classified at the same time. Experimental results show that the proposed method can make significant improvement in performance compared with several state-of-the-art methods.
Mixed Set Domain Adaptation
Nov 04, 2020



In the settings of conventional domain adaptation, categories of the source dataset are from the same domain (or domains for multi-source domain adaptation), which is not always true in reality. In this paper, we propose \textbf{\textit{Mixed Set Domain Adaptation} (MSDA)}. Under the settings of MSDA, different categories of the source dataset are not all collected from the same domain(s). For instance, category $1\sim k$ are collected from domain $\alpha$ while category $k+1\sim c$ are collected from domain $\beta$. Under such situation, domain adaptation performance will be further influenced because of the distribution discrepancy inside the source data. A feature element-wise weighting (FEW) method that can reduce distribution discrepancy between different categories is also proposed for MSDA. Experimental results and quality analysis show the significance of solving MSDA problem and the effectiveness of the proposed method.
Deep Adversarial Domain Adaptation Based on Multi-layer Joint Kernelized Distance
Oct 09, 2020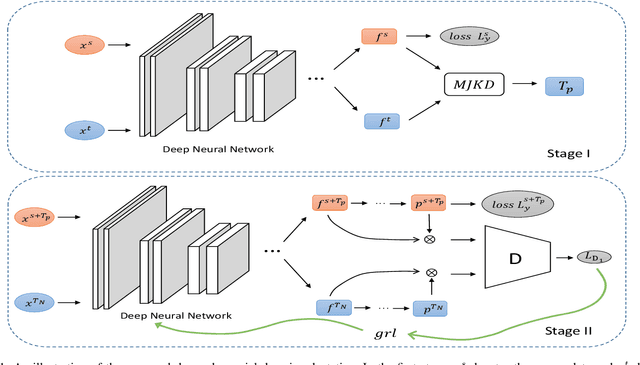

Domain adaptation refers to the learning scenario that a model learned from the source data is applied on the target data which have the same categories but different distribution. While it has been widely applied, the distribution discrepancy between source data and target data can substantially affect the adaptation performance. The problem has been recently addressed by employing adversarial learning and distinctive adaptation performance has been reported. In this paper, a deep adversarial domain adaptation model based on a multi-layer joint kernelized distance metric is proposed. By utilizing the abstract features extracted from deep networks, the multi-layer joint kernelized distance (MJKD) between the $j$th target data predicted as the $m$th category and all the source data of the $m'$th category is computed. Base on MJKD, a class-balanced selection strategy is utilized in each category to select target data that are most likely to be classified correctly and treat them as labeled data using their pseudo labels. Then an adversarial architecture is used to draw the newly generated labeled training data and the remaining target data close to each other. In this way, the target data itself provide valuable information to enhance the domain adaptation. An analysis of the proposed method is also given and the experimental results demonstrate that the proposed method can achieve a better performance than a number of state-of-the-art methods.
Adversarial Deep Network Embedding for Cross-network Node Classification
Feb 18, 2020
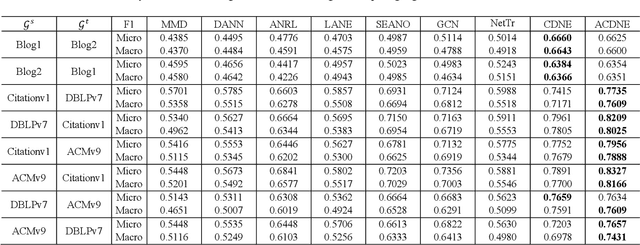

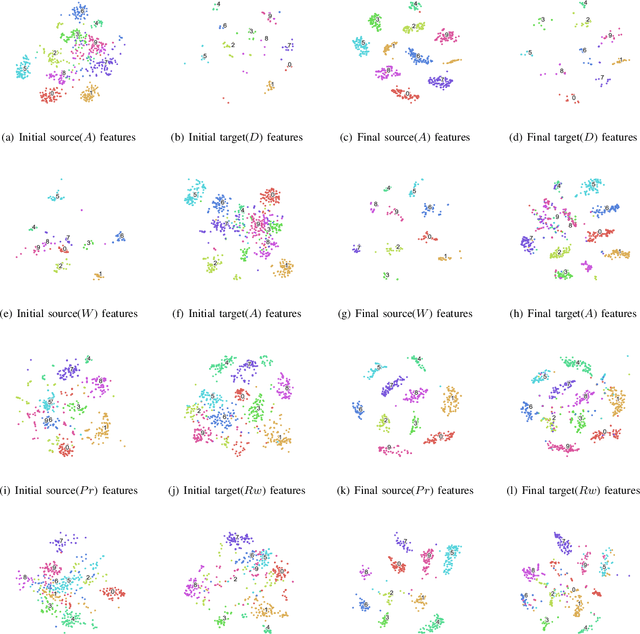
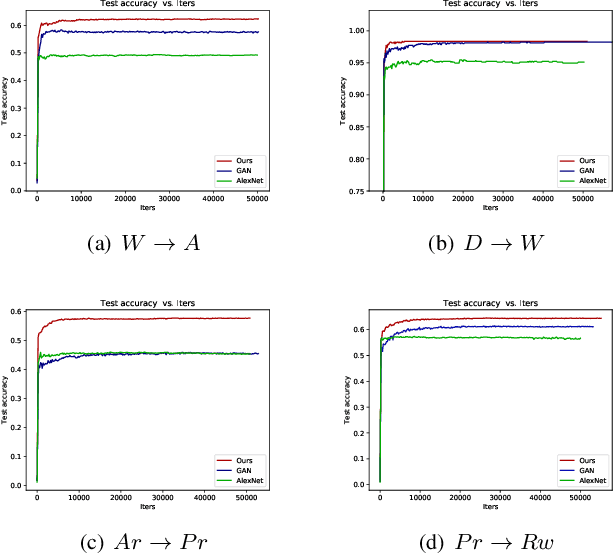
In this paper, the task of cross-network node classification, which leverages the abundant labeled nodes from a source network to help classify unlabeled nodes in a target network, is studied. The existing domain adaptation algorithms generally fail to model the network structural information, and the current network embedding models mainly focus on single-network applications. Thus, both of them cannot be directly applied to solve the cross-network node classification problem. This motivates us to propose an adversarial cross-network deep network embedding (ACDNE) model to integrate adversarial domain adaptation with deep network embedding so as to learn network-invariant node representations that can also well preserve the network structural information. In ACDNE, the deep network embedding module utilizes two feature extractors to jointly preserve attributed affinity and topological proximities between nodes. In addition, a node classifier is incorporated to make node representations label-discriminative. Moreover, an adversarial domain adaptation technique is employed to make node representations network-invariant. Extensive experimental results demonstrate that the proposed ACDNE model achieves the state-of-the-art performance in cross-network node classification.
Variational Metric Scaling for Metric-Based Meta-Learning
Dec 26, 2019



Metric-based meta-learning has attracted a lot of attention due to its effectiveness and efficiency in few-shot learning. Recent studies show that metric scaling plays a crucial role in the performance of metric-based meta-learning algorithms. However, there still lacks a principled method for learning the metric scaling parameter automatically. In this paper, we recast metric-based meta-learning from a Bayesian perspective and develop a variational metric scaling framework for learning a proper metric scaling parameter. Firstly, we propose a stochastic variational method to learn a single global scaling parameter. To better fit the embedding space to a given data distribution, we extend our method to learn a dimensional scaling vector to transform the embedding space. Furthermore, to learn task-specific embeddings, we generate task-dependent dimensional scaling vectors with amortized variational inference. Our method is end-to-end without any pre-training and can be used as a simple plug-and-play module for existing metric-based meta-algorithms. Experiments on mini-ImageNet show that our methods can be used to consistently improve the performance of existing metric-based meta-algorithms including prototypical networks and TADAM.
Theoretic Analysis and Extremely Easy Algorithms for Domain Adaptive Feature Learning
Aug 10, 2017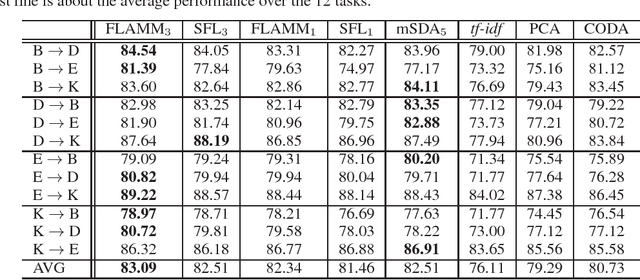
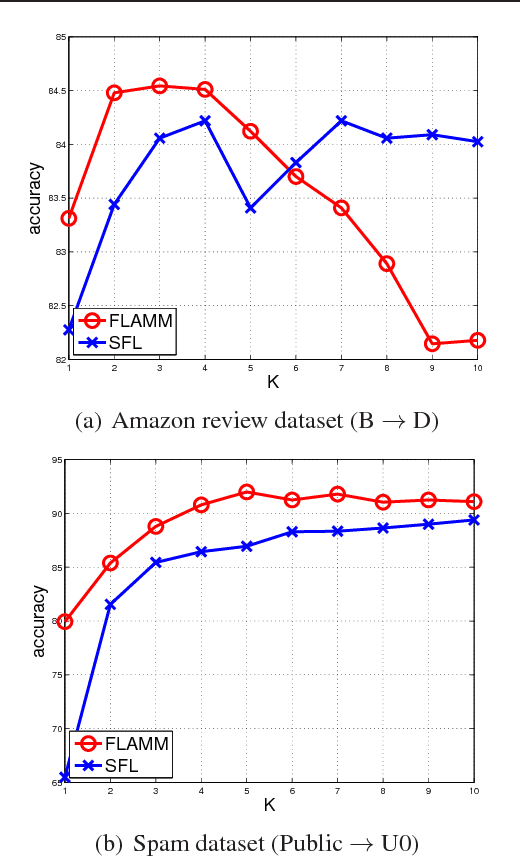

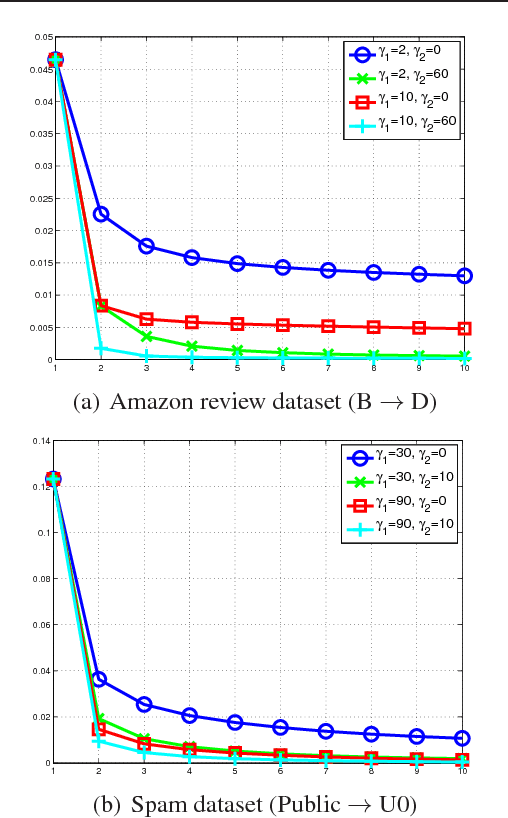
Domain adaptation problems arise in a variety of applications, where a training dataset from the \textit{source} domain and a test dataset from the \textit{target} domain typically follow different distributions. The primary difficulty in designing effective learning models to solve such problems lies in how to bridge the gap between the source and target distributions. In this paper, we provide comprehensive analysis of feature learning algorithms used in conjunction with linear classifiers for domain adaptation. Our analysis shows that in order to achieve good adaptation performance, the second moments of the source domain distribution and target domain distribution should be similar. Based on our new analysis, a novel extremely easy feature learning algorithm for domain adaptation is proposed. Furthermore, our algorithm is extended by leveraging multiple layers, leading to a deep linear model. We evaluate the effectiveness of the proposed algorithms in terms of domain adaptation tasks on the Amazon review dataset and the spam dataset from the ECML/PKDD 2006 discovery challenge.