 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Implicit Memory for Video World Models
Jun 01, 2026Video world models aim to simulate controllable visual environments, but long-horizon rollouts depend on what the model remembers after observations leave its native context window. Explicit memories retain frames or online 3D reconstructions, which can suffer from heuristic retrieval errors, redundant appearance storage, or reconstruction artifacts. Implicit memories compress history into a compact state, but existing designs are not explicitly constrained to encode cross-view scene geometry. We propose GIM-World, a geometry-aware implicit memory framework for video world models. A lightweight transformer encoder compresses variable-length history into fixed-size memory tokens, a camera-queryable geometry head distills 3D scene structure from a frozen foundation model into the memory during training, and an information-guided pruning rule keeps encoding cost bounded as history grows. The geometry teacher is discarded at inference, leaving a lightweight memory module. Experiments on MIND show that GIM-World better preserves long-horizon geometric and visual consistency than both explicit- and implicit-memory baselines.
Towards 3D-Aware Video Diffusion Models: Render-Free Human Motion Control with Mesh Tokenization
Jun 01, 2026Diffusion models have shown remarkable success in video generation. However, whether such models are truly aware of the 3D structure underlying visual observations, rather than simply reproducing plausible 2D projections, remains an open question. In this work, we investigate this question through human motion control, a task that requires precise modelling of 3D human geometry, motion, camera viewpoint, and scene context. Unlike prior methods that rely on rendered 2D motion guidance videos, we propose a render-free framework that conditions video generation directly on compressed 3D human mesh tokens. This representation preserves full 3D geometric information while enabling a unified token-based generation pipeline that processes video tokens jointly with motion tokens in a DiT-based architecture. This design requires the model to reason jointly about appearance, 3D structure, and camera viewpoint during video generation. Experimental results demonstrate strong performance on human motion control benchmarks, while reducing artifacts induced by view-dependent 2D guidance and trajectory-pose mismatches during editing. These findings suggest that video diffusion models, when equipped with mesh tokenization, can better capture complex 3D human structures and their interactions with the surrounding environment.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
GOGS: High-Fidelity Geometry and Relighting for Glossy Objects via Gaussian Surfels
Aug 20, 2025Inverse rendering of glossy objects from RGB imagery remains fundamentally limited by inherent ambiguity. Although NeRF-based methods achieve high-fidelity reconstruction via dense-ray sampling, their computational cost is prohibitive. Recent 3D Gaussian Splatting achieves high reconstruction efficiency but exhibits limitations under specular reflections. Multi-view inconsistencies introduce high-frequency surface noise and structural artifacts, while simplified rendering equations obscure material properties, leading to implausible relighting results. To address these issues, we propose GOGS, a novel two-stage framework based on 2D Gaussian surfels. First, we establish robust surface reconstruction through physics-based rendering with split-sum approximation, enhanced by geometric priors from foundation models. Second, we perform material decomposition by leveraging Monte Carlo importance sampling of the full rendering equation, modeling indirect illumination via differentiable 2D Gaussian ray tracing and refining high-frequency specular details through spherical mipmap-based directional encoding that captures anisotropic highlights. Extensive experiments demonstrate state-of-the-art performance in geometry reconstruction, material separation, and photorealistic relighting under novel illuminations, outperforming existing inverse rendering approaches.
3DV-TON: Textured 3D-Guided Consistent Video Try-on via Diffusion Models
Apr 24, 2025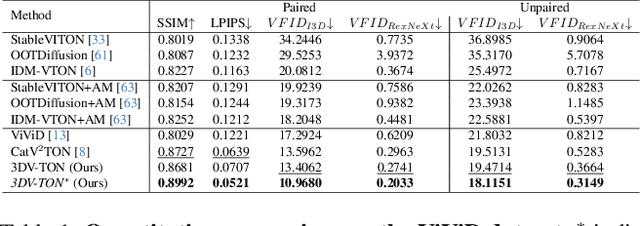


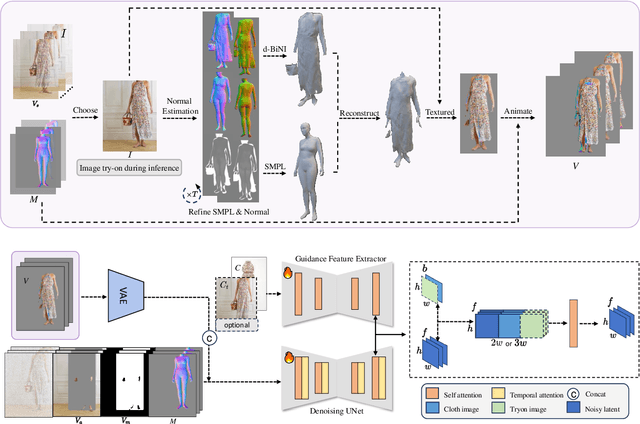
Video try-on replaces clothing in videos with target garments. Existing methods struggle to generate high-quality and temporally consistent results when handling complex clothing patterns and diverse body poses. We present 3DV-TON, a novel diffusion-based framework for generating high-fidelity and temporally consistent video try-on results. Our approach employs generated animatable textured 3D meshes as explicit frame-level guidance, alleviating the issue of models over-focusing on appearance fidelity at the expanse of motion coherence. This is achieved by enabling direct reference to consistent garment texture movements throughout video sequences. The proposed method features an adaptive pipeline for generating dynamic 3D guidance: (1) selecting a keyframe for initial 2D image try-on, followed by (2) reconstructing and animating a textured 3D mesh synchronized with original video poses. We further introduce a robust rectangular masking strategy that successfully mitigates artifact propagation caused by leaking clothing information during dynamic human and garment movements. To advance video try-on research, we introduce HR-VVT, a high-resolution benchmark dataset containing 130 videos with diverse clothing types and scenarios. Quantitative and qualitative results demonstrate our superior performance over existing methods. The project page is at this link https://2y7c3.github.io/3DV-TON/
RealisDance-DiT: Simple yet Strong Baseline towards Controllable Character Animation in the Wild
Apr 21, 2025
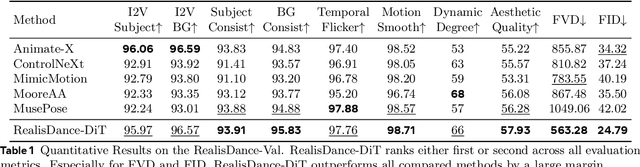

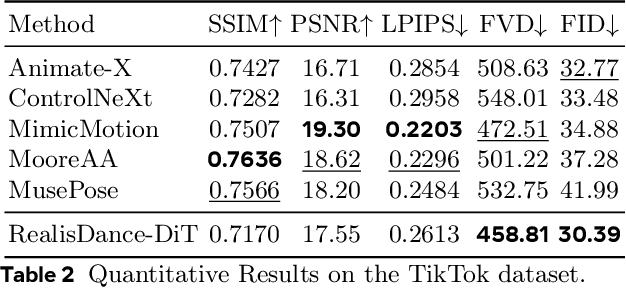
Controllable character animation remains a challenging problem, particularly in handling rare poses, stylized characters, character-object interactions, complex illumination, and dynamic scenes. To tackle these issues, prior work has largely focused on injecting pose and appearance guidance via elaborate bypass networks, but often struggles to generalize to open-world scenarios. In this paper, we propose a new perspective that, as long as the foundation model is powerful enough, straightforward model modifications with flexible fine-tuning strategies can largely address the above challenges, taking a step towards controllable character animation in the wild. Specifically, we introduce RealisDance-DiT, built upon the Wan-2.1 video foundation model. Our sufficient analysis reveals that the widely adopted Reference Net design is suboptimal for large-scale DiT models. Instead, we demonstrate that minimal modifications to the foundation model architecture yield a surprisingly strong baseline. We further propose the low-noise warmup and "large batches and small iterations" strategies to accelerate model convergence during fine-tuning while maximally preserving the priors of the foundation model. In addition, we introduce a new test dataset that captures diverse real-world challenges, complementing existing benchmarks such as TikTok dataset and UBC fashion video dataset, to comprehensively evaluate the proposed method. Extensive experiments show that RealisDance-DiT outperforms existing methods by a large margin.
Adversarial Score Distillation: When score distillation meets GAN
Dec 01, 2023Existing score distillation methods are sensitive to classifier-free guidance (CFG) scale: manifested as over-smoothness or instability at small CFG scales, while over-saturation at large ones. To explain and analyze these issues, we revisit the derivation of Score Distillation Sampling (SDS) and decipher existing score distillation with the Wasserstein Generative Adversarial Network (WGAN) paradigm. With the WGAN paradigm, we find that existing score distillation either employs a fixed sub-optimal discriminator or conducts incomplete discriminator optimization, resulting in the scale-sensitive issue. We propose the Adversarial Score Distillation (ASD), which maintains an optimizable discriminator and updates it using the complete optimization objective. Experiments show that the proposed ASD performs favorably in 2D distillation and text-to-3D tasks against existing methods. Furthermore, to explore the generalization ability of our WGAN paradigm, we extend ASD to the image editing task, which achieves competitive results. The project page and code are at https://github.com/2y7c3/ASD.
Communication Efficiency Optimization of Federated Learning for Computing and Network Convergence of 6G Networks
Nov 28, 2023Federated learning effectively addresses issues such as data privacy by collaborating across participating devices to train global models. However, factors such as network topology and device computing power can affect its training or communication process in complex network environments. A new network architecture and paradigm with computing-measurable, perceptible, distributable, dispatchable, and manageable capabilities, computing and network convergence (CNC) of 6G networks can effectively support federated learning training and improve its communication efficiency. By guiding the participating devices' training in federated learning based on business requirements, resource load, network conditions, and arithmetic power of devices, CNC can reach this goal. In this paper, to improve the communication efficiency of federated learning in complex networks, we study the communication efficiency optimization of federated learning for computing and network convergence of 6G networks, methods that gives decisions on its training process for different network conditions and arithmetic power of participating devices in federated learning. The experiments address two architectures that exist for devices in federated learning and arrange devices to participate in training based on arithmetic power while achieving optimization of communication efficiency in the process of transferring model parameters. The results show that the method we proposed can (1) cope well with complex network situations (2) effectively balance the delay distribution of participating devices for local training (3) improve the communication efficiency during the transfer of model parameters (4) improve the resource utilization in the network.
Super-Resolution Neural Operator
Mar 05, 2023We propose Super-resolution Neural Operator (SRNO), a deep operator learning framework that can resolve high-resolution (HR) images at arbitrary scales from the low-resolution (LR) counterparts. Treating the LR-HR image pairs as continuous functions approximated with different grid sizes, SRNO learns the mapping between the corresponding function spaces. From the perspective of approximation theory, SRNO first embeds the LR input into a higher-dimensional latent representation space, trying to capture sufficient basis functions, and then iteratively approximates the implicit image function with a kernel integral mechanism, followed by a final dimensionality reduction step to generate the RGB representation at the target coordinates. The key characteristics distinguishing SRNO from prior continuous SR works are: 1) the kernel integral in each layer is efficiently implemented via the Galerkin-type attention, which possesses non-local properties in the spatial domain and therefore benefits the grid-free continuum; and 2) the multilayer attention architecture allows for the dynamic latent basis update, which is crucial for SR problems to "hallucinate" high-frequency information from the LR image. Experiments show that SRNO outperforms existing continuous SR methods in terms of both accuracy and running time. Our code is at https://github.com/2y7c3/Super-Resolution-Neural-Operator
Mutual Information-Based Unsupervised Feature Transformation for Heterogeneous Feature Subset Selection
Mar 29, 2015Conventional mutual information (MI) based feature selection (FS) methods are unable to handle heterogeneous feature subset selection properly because of data format differences or estimation methods of MI between feature subset and class label. A way to solve this problem is feature transformation (FT). In this study, a novel unsupervised feature transformation (UFT) which can transform non-numerical features into numerical features is developed and tested. The UFT process is MI-based and independent of class label. MI-based FS algorithms, such as Parzen window feature selector (PWFS), minimum redundancy maximum relevance feature selection (mRMR), and normalized MI feature selection (NMIFS), can all adopt UFT for pre-processing of non-numerical features. Unlike traditional FT methods, the proposed UFT is unbiased while PWFS is utilized to its full advantage. Simulations and analyses of large-scale datasets showed that feature subset selected by the integrated method, UFT-PWFS, outperformed other FT-FS integrated methods in classification accuracy.