 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Foreground and Background for vision-Language Navigation via Online Augmentation
Oct 01, 2025Following language instructions, vision-language navigation (VLN) agents are tasked with navigating unseen environments. While augmenting multifaceted visual representations has propelled advancements in VLN, the significance of foreground and background in visual observations remains underexplored. Intuitively, foreground regions provide semantic cues, whereas the background encompasses spatial connectivity information. Inspired on this insight, we propose a Consensus-driven Online Feature Augmentation strategy (COFA) with alternative foreground and background features to facilitate the navigable generalization. Specifically, we first leverage semantically-enhanced landmark identification to disentangle foreground and background as candidate augmented features. Subsequently, a consensus-driven online augmentation strategy encourages the agent to consolidate two-stage voting results on feature preferences according to diverse instructions and navigational locations. Experiments on REVERIE and R2R demonstrate that our online foreground-background augmentation boosts the generalization of baseline and attains state-of-the-art performance.
PhysioSync: Temporal and Cross-Modal Contrastive Learning Inspired by Physiological Synchronization for EEG-Based Emotion Recognition
Apr 24, 2025Electroencephalography (EEG) signals provide a promising and involuntary reflection of brain activity related to emotional states, offering significant advantages over behavioral cues like facial expressions. However, EEG signals are often noisy, affected by artifacts, and vary across individuals, complicating emotion recognition. While multimodal approaches have used Peripheral Physiological Signals (PPS) like GSR to complement EEG, they often overlook the dynamic synchronization and consistent semantics between the modalities. Additionally, the temporal dynamics of emotional fluctuations across different time resolutions in PPS remain underexplored. To address these challenges, we propose PhysioSync, a novel pre-training framework leveraging temporal and cross-modal contrastive learning, inspired by physiological synchronization phenomena. PhysioSync incorporates Cross-Modal Consistency Alignment (CM-CA) to model dynamic relationships between EEG and complementary PPS, enabling emotion-related synchronizations across modalities. Besides, it introduces Long- and Short-Term Temporal Contrastive Learning (LS-TCL) to capture emotional synchronization at different temporal resolutions within modalities. After pre-training, cross-resolution and cross-modal features are hierarchically fused and fine-tuned to enhance emotion recognition. Experiments on DEAP and DREAMER datasets demonstrate PhysioSync's advanced performance under uni-modal and cross-modal conditions, highlighting its effectiveness for EEG-centered emotion recognition.
Agent Journey Beyond RGB: Unveiling Hybrid Semantic-Spatial Environmental Representations for Vision-and-Language Navigation
Dec 10, 2024


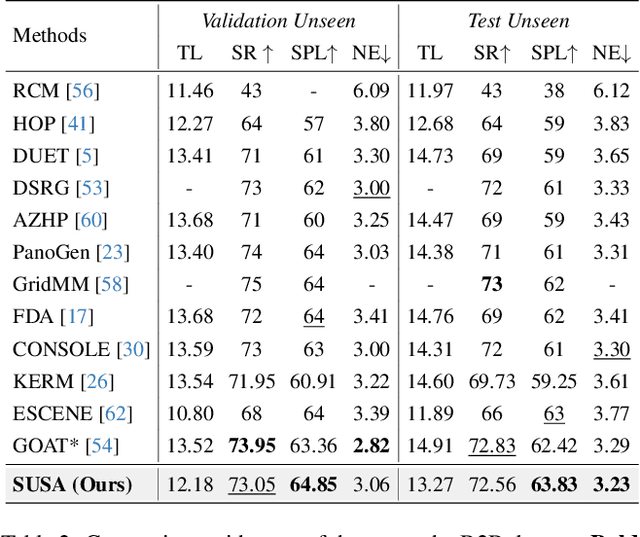
Navigating unseen environments based on natural language instructions remains difficult for egocentric agents in Vision-and-Language Navigation (VLN). While recent advancements have yielded promising outcomes, they primarily rely on RGB images for environmental representation, often overlooking the underlying semantic knowledge and spatial cues. Intuitively, humans inherently ground textual semantics within the spatial layout during indoor navigation. Inspired by this, we propose a versatile Semantic Understanding and Spatial Awareness (SUSA) architecture to facilitate navigation. SUSA includes a Textual Semantic Understanding (TSU) module, which narrows the modality gap between instructions and environments by generating and associating the descriptions of environmental landmarks in the agent's immediate surroundings. Additionally, a Depth-based Spatial Perception (DSP) module incrementally constructs a depth exploration map, enabling a more nuanced comprehension of environmental layouts. Experimental results demonstrate that SUSA hybrid semantic-spatial representations effectively enhance navigation performance, setting new state-of-the-art performance across three VLN benchmarks (REVERIE, R2R, and SOON). The source code will be publicly available.
Seeing is Believing? Enhancing Vision-Language Navigation using Visual Perturbations
Sep 09, 2024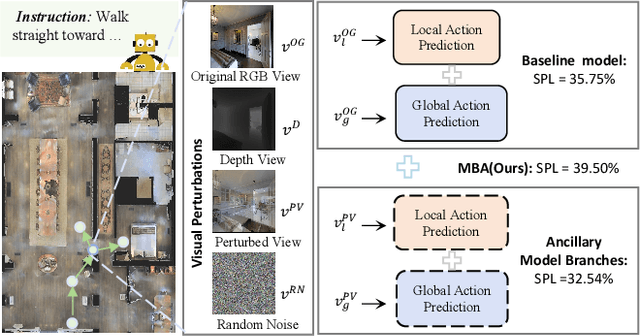

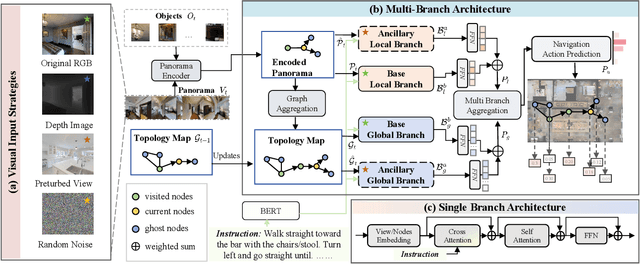

Autonomous navigation for an embodied agent guided by natural language instructions remains a formidable challenge in vision-and-language navigation (VLN). Despite remarkable recent progress in learning fine-grained and multifarious visual representations, the tendency to overfit to the training environments leads to unsatisfactory generalization performance. In this work, we present a versatile Multi-Branch Architecture (MBA) aimed at exploring and exploiting diverse visual inputs. Specifically, we introduce three distinct visual variants: ground-truth depth images, visual inputs integrated with incongruent views, and those infused with random noise to enrich the diversity of visual input representation and prevent overfitting to the original RGB observations. To adaptively fuse these varied inputs, the proposed MBA extend a base agent model into a multi-branch variant, where each branch processes a different visual input. Surprisingly, even random noise can further enhance navigation performance in unseen environments. Extensive experiments conducted on three VLN benchmarks (R2R, REVERIE, SOON) demonstrate that our proposed method equals or even surpasses state-of-the-art results. The source code will be publicly available.
Adversarial Score Distillation: When score distillation meets GAN
Dec 01, 2023Existing score distillation methods are sensitive to classifier-free guidance (CFG) scale: manifested as over-smoothness or instability at small CFG scales, while over-saturation at large ones. To explain and analyze these issues, we revisit the derivation of Score Distillation Sampling (SDS) and decipher existing score distillation with the Wasserstein Generative Adversarial Network (WGAN) paradigm. With the WGAN paradigm, we find that existing score distillation either employs a fixed sub-optimal discriminator or conducts incomplete discriminator optimization, resulting in the scale-sensitive issue. We propose the Adversarial Score Distillation (ASD), which maintains an optimizable discriminator and updates it using the complete optimization objective. Experiments show that the proposed ASD performs favorably in 2D distillation and text-to-3D tasks against existing methods. Furthermore, to explore the generalization ability of our WGAN paradigm, we extend ASD to the image editing task, which achieves competitive results. The project page and code are at https://github.com/2y7c3/ASD.
Multimodal Feature Extraction and Fusion for Emotional Reaction Intensity Estimation and Expression Classification in Videos with Transformers
Mar 16, 2023



In this paper, we present our solutions to the two sub-challenges of Affective Behavior Analysis in the wild (ABAW) 2023: the Emotional Reaction Intensity (ERI) Estimation Challenge and Expression (Expr) Classification Challenge. ABAW 2023 focuses on the problem of affective behavior analysis in the wild, with the goal of creating machines and robots that have the ability to understand human feelings, emotions and behaviors, which can effectively contribute to the advent of a more intelligent future. In our work, we use different models and tools for the Hume-Reaction dataset to extract features of various aspects, such as audio features, video features, etc. By analyzing, combining, and studying these multimodal features, we effectively improve the accuracy of the model for multimodal sentiment prediction. For the Emotional Reaction Intensity (ERI) Estimation Challenge, our method shows excellent results with a Pearson coefficient on the validation dataset, exceeding the baseline method by 84 percent.
Super-Resolution Neural Operator
Mar 05, 2023We propose Super-resolution Neural Operator (SRNO), a deep operator learning framework that can resolve high-resolution (HR) images at arbitrary scales from the low-resolution (LR) counterparts. Treating the LR-HR image pairs as continuous functions approximated with different grid sizes, SRNO learns the mapping between the corresponding function spaces. From the perspective of approximation theory, SRNO first embeds the LR input into a higher-dimensional latent representation space, trying to capture sufficient basis functions, and then iteratively approximates the implicit image function with a kernel integral mechanism, followed by a final dimensionality reduction step to generate the RGB representation at the target coordinates. The key characteristics distinguishing SRNO from prior continuous SR works are: 1) the kernel integral in each layer is efficiently implemented via the Galerkin-type attention, which possesses non-local properties in the spatial domain and therefore benefits the grid-free continuum; and 2) the multilayer attention architecture allows for the dynamic latent basis update, which is crucial for SR problems to "hallucinate" high-frequency information from the LR image. Experiments show that SRNO outperforms existing continuous SR methods in terms of both accuracy and running time. Our code is at https://github.com/2y7c3/Super-Resolution-Neural-Operator