 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Journey Beyond RGB: Unveiling Hybrid Semantic-Spatial Environmental Representations for Vision-and-Language Navigation
Paper and Code



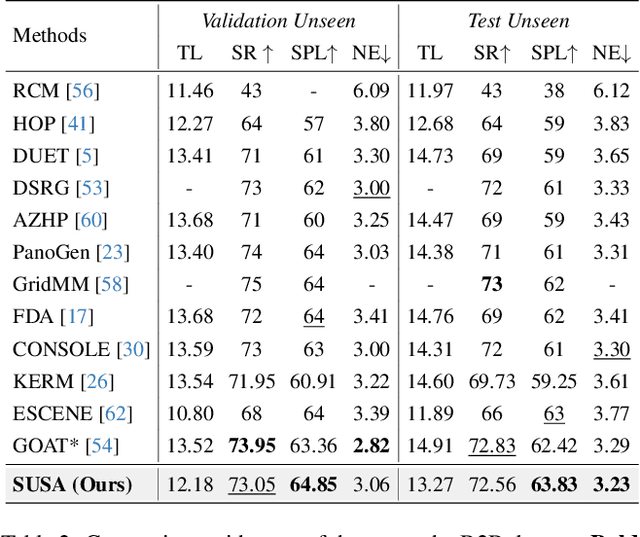
Navigating unseen environments based on natural language instructions remains difficult for egocentric agents in Vision-and-Language Navigation (VLN). While recent advancements have yielded promising outcomes, they primarily rely on RGB images for environmental representation, often overlooking the underlying semantic knowledge and spatial cues. Intuitively, humans inherently ground textual semantics within the spatial layout during indoor navigation. Inspired by this, we propose a versatile Semantic Understanding and Spatial Awareness (SUSA) architecture to facilitate navigation. SUSA includes a Textual Semantic Understanding (TSU) module, which narrows the modality gap between instructions and environments by generating and associating the descriptions of environmental landmarks in the agent's immediate surroundings. Additionally, a Depth-based Spatial Perception (DSP) module incrementally constructs a depth exploration map, enabling a more nuanced comprehension of environmental layouts. Experimental results demonstrate that SUSA hybrid semantic-spatial representations effectively enhance navigation performance, setting new state-of-the-art performance across three VLN benchmarks (REVERIE, R2R, and SOON). The source code will be publicly available.