 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing is Believing? Enhancing Vision-Language Navigation using Visual Perturbations
Paper and Code
Sep 09, 2024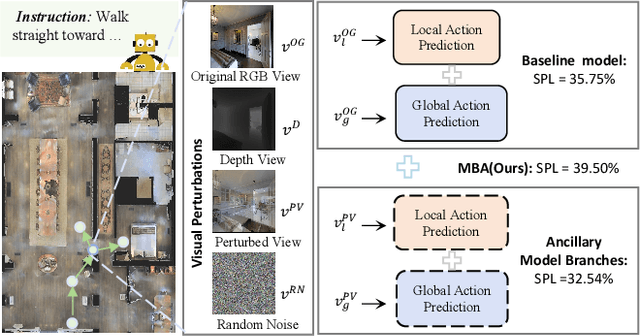

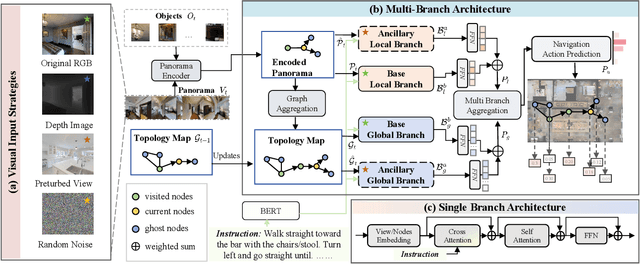

Autonomous navigation for an embodied agent guided by natural language instructions remains a formidable challenge in vision-and-language navigation (VLN). Despite remarkable recent progress in learning fine-grained and multifarious visual representations, the tendency to overfit to the training environments leads to unsatisfactory generalization performance. In this work, we present a versatile Multi-Branch Architecture (MBA) aimed at exploring and exploiting diverse visual inputs. Specifically, we introduce three distinct visual variants: ground-truth depth images, visual inputs integrated with incongruent views, and those infused with random noise to enrich the diversity of visual input representation and prevent overfitting to the original RGB observations. To adaptively fuse these varied inputs, the proposed MBA extend a base agent model into a multi-branch variant, where each branch processes a different visual input. Surprisingly, even random noise can further enhance navigation performance in unseen environments. Extensive experiments conducted on three VLN benchmarks (R2R, REVERIE, SOON) demonstrate that our proposed method equals or even surpasses state-of-the-art results. The source code will be publicly available.