 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextSculptor: Training and Benchmarking Scene Text Editing
May 20, 2026Recent advances in Multimodal Large Language Models (MLLMs) and diffusion-based generative models have substantially improved prompt-driven image editing. However, scene text editing remains challenging, as it requires models to precisely modify textual content while preserving visual realism and non-target regions. Current open-source models still lag behind proprietary systems, largely due to the scarcity of high-quality training data and the lack of standardized benchmarks tailored to text editing. To address these challenges, we present TextSculptor, a comprehensive framework for data construction and evaluation of scene text editing. We first develop an automated data construction pipeline that combines text-aware image synthesis with programmatic text rendering and compositing. Based on this pipeline, we build TextSculpt-Data, a large-scale dataset containing 3.2M training samples, including 1.2M OCR-verified text-to-image samples and 2M paired text editing samples with naturally aligned source-target images and strong background consistency. We further introduce TextSculpt-Bench, a benchmark covering four fundamental text editing tasks: text addition, text replacement, text removal, and hybrid editing. To support reliable evaluation, we design a tailored protocol that measures text accuracy, visual quality, and background preservation through OCR-based text alignment, multimodal judgment, and background-region similarity. Extensive experiments show that TextSculptor improves open-source text editing performance and narrows the gap to proprietary models. The data and benchmark are available at https://github.com/linyiheng123/TextSculptor.
Exploring the Global-to-Local Attention Scheme in Graph Transformers: An Empirical Study
Sep 18, 2025Graph Transformers (GTs) show considerable potential in graph representation learning. The architecture of GTs typically integrates Graph Neural Networks (GNNs) with global attention mechanisms either in parallel or as a precursor to attention mechanisms, yielding a local-and-global or local-to-global attention scheme. However, as the global attention mechanism primarily captures long-range dependencies between nodes, these integration schemes may suffer from information loss, where the local neighborhood information learned by GNN could be diluted by the attention mechanism. Therefore, we propose G2LFormer, featuring a novel global-to-local attention scheme where the shallow network layers use attention mechanisms to capture global information, while the deeper layers employ GNN modules to learn local structural information, thereby preventing nodes from ignoring their immediate neighbors. An effective cross-layer information fusion strategy is introduced to allow local layers to retain beneficial information from global layers and alleviate information loss, with acceptable trade-offs in scalability. To validate the feasibility of the global-to-local attention scheme, we compare G2LFormer with state-of-the-art linear GTs and GNNs on node-level and graph-level tasks. The results indicate that G2LFormer exhibits excellent performance while keeping linear complexity.
UperFormer: A Multi-scale Transformer-based Decoder for Semantic Segmentation
Nov 25, 2022



While a large number of recent works on semantic segmentation focus on designing and incorporating a transformer-based encoder, much less attention and vigor have been devoted to transformer-based decoders. For such a task whose hallmark quest is pixel-accurate prediction, we argue that the decoder stage is just as crucial as that of the encoder in achieving superior segmentation performance, by disentangling and refining the high-level cues and working out object boundaries with pixel-level precision. In this paper, we propose a novel transformer-based decoder called UperFormer, which is plug-and-play for hierarchical encoders and attains high quality segmentation results regardless of encoder architecture. UperFormer is equipped with carefully designed multi-head skip attention units and novel upsampling operations. Multi-head skip attention is able to fuse multi-scale features from backbones with those in decoders. The upsampling operation, which incorporates feature from encoder, can be more friendly for object localization. It brings a 0.4% to 3.2% increase compared with traditional upsampling methods. By combining UperFormer with Swin Transformer (Swin-T), a fully transformer-based symmetric network is formed for semantic segmentation tasks. Extensive experiments show that our proposed approach is highly effective and computationally efficient. On Cityscapes dataset, we achieve state-of-the-art performance. On the more challenging ADE20K dataset, our best model yields a single-scale mIoU of 50.18, and a multi-scale mIoU of 51.8, which is on-par with the current state-of-art model, while we drastically cut the number of FLOPs by 53.5%. Our source code and models are publicly available at: https://github.com/shiwt03/UperFormer
TEAM-Net: Multi-modal Learning for Video Action Recognition with Partial Decoding
Oct 17, 2021


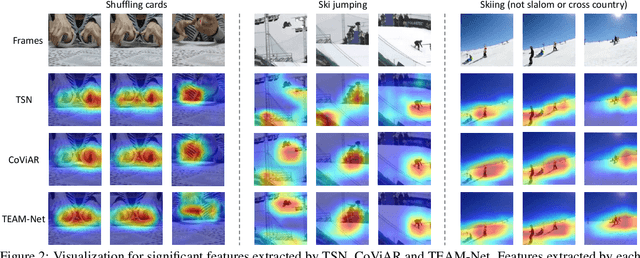
Most of existing video action recognition models ingest raw RGB frames. However, the raw video stream requires enormous storage and contains significant temporal redundancy. Video compression (e.g., H.264, MPEG-4) reduces superfluous information by representing the raw video stream using the concept of Group of Pictures (GOP). Each GOP is composed of the first I-frame (aka RGB image) followed by a number of P-frames, represented by motion vectors and residuals, which can be regarded and used as pre-extracted features. In this work, we 1) introduce sampling the input for the network from partially decoded videos based on the GOP-level, and 2) propose a plug-and-play mulTi-modal lEArning Module (TEAM) for training the network using information from I-frames and P-frames in an end-to-end manner. We demonstrate the superior performance of TEAM-Net compared to the baseline using RGB only. TEAM-Net also achieves the state-of-the-art performance in the area of video action recognition with partial decoding. Code is provided at https://github.com/villawang/TEAM-Net.
Generative adversarial networks in time series: A survey and taxonomy
Jul 23, 2021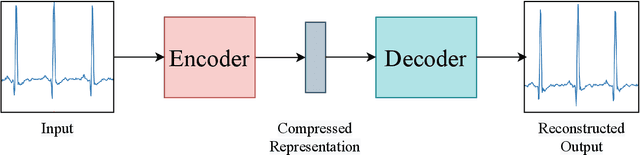
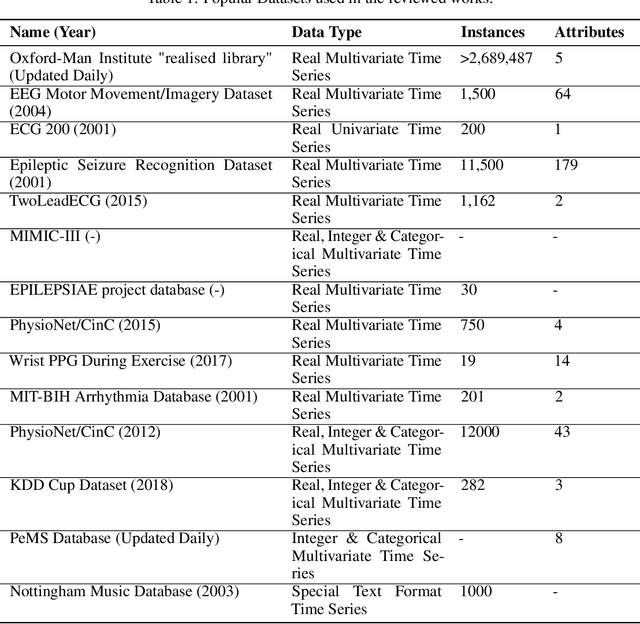
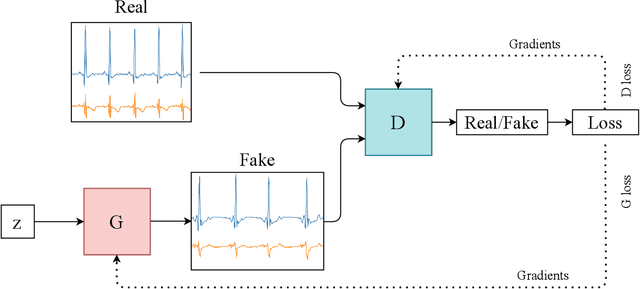
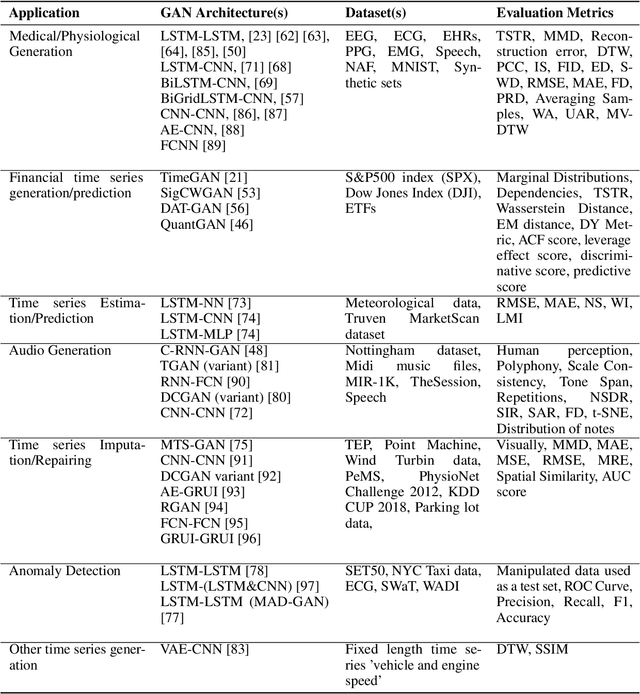
Generative adversarial networks (GANs) studies have grown exponentially in the past few years. Their impact has been seen mainly in the computer vision field with realistic image and video manipulation, especially generation, making significant advancements. While these computer vision advances have garnered much attention, GAN applications have diversified across disciplines such as time series and sequence generation. As a relatively new niche for GANs, fieldwork is ongoing to develop high quality, diverse and private time series data. In this paper, we review GAN variants designed for time series related applications. We propose a taxonomy of discrete-variant GANs and continuous-variant GANs, in which GANs deal with discrete time series and continuous time series data. Here we showcase the latest and most popular literature in this field; their architectures, results, and applications. We also provide a list of the most popular evaluation metrics and their suitability across applications. Also presented is a discussion of privacy measures for these GANs and further protections and directions for dealing with sensitive data. We aim to frame clearly and concisely the latest and state-of-the-art research in this area and their applications to real-world technologies.
ACTION-Net: Multipath Excitation for Action Recognition
Mar 11, 2021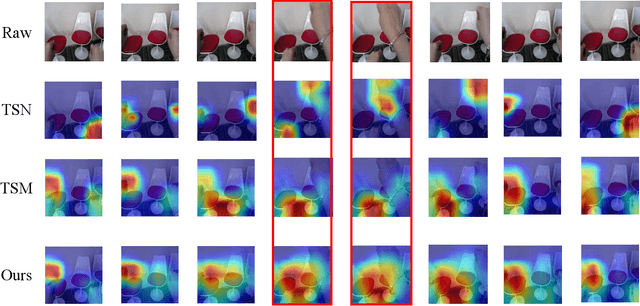

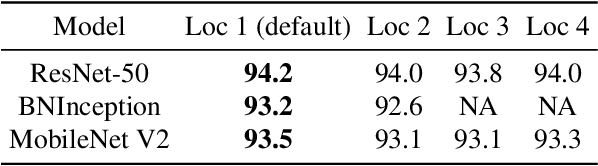
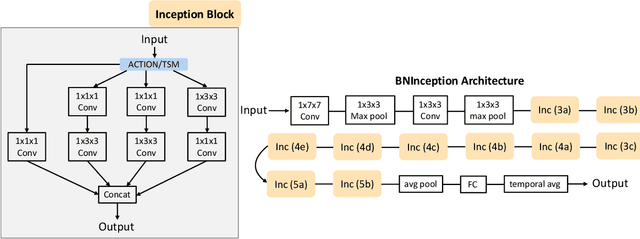
Spatial-temporal, channel-wise, and motion patterns are three complementary and crucial types of information for video action recognition. Conventional 2D CNNs are computationally cheap but cannot catch temporal relationships; 3D CNNs can achieve good performance but are computationally intensive. In this work, we tackle this dilemma by designing a generic and effective module that can be embedded into 2D CNNs. To this end, we propose a spAtio-temporal, Channel and moTion excitatION (ACTION) module consisting of three paths: Spatio-Temporal Excitation (STE) path, Channel Excitation (CE) path, and Motion Excitation (ME) path. The STE path employs one channel 3D convolution to characterize spatio-temporal representation. The CE path adaptively recalibrates channel-wise feature responses by explicitly modeling interdependencies between channels in terms of the temporal aspect. The ME path calculates feature-level temporal differences, which is then utilized to excite motion-sensitive channels. We equip 2D CNNs with the proposed ACTION module to form a simple yet effective ACTION-Net with very limited extra computational cost. ACTION-Net is demonstrated by consistently outperforming 2D CNN counterparts on three backbones (i.e., ResNet-50, MobileNet V2 and BNInception) employing three datasets (i.e., Something-Something V2, Jester, and EgoGesture). Codes are available at \url{https://github.com/V-Sense/ACTION-Net}.
IROS 2019 Lifelong Robotic Vision Challenge -- Lifelong Object Recognition Report
Apr 26, 2020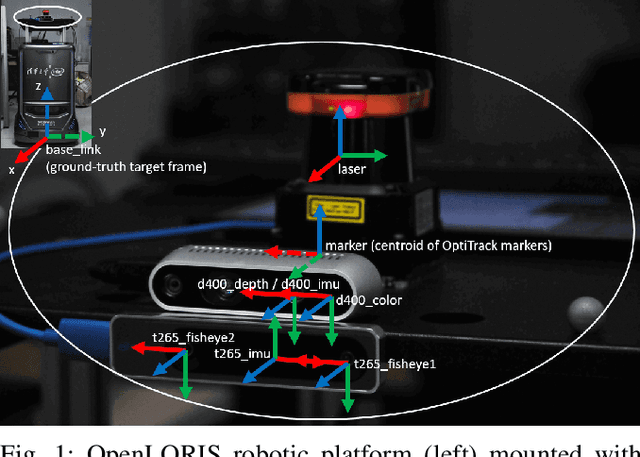
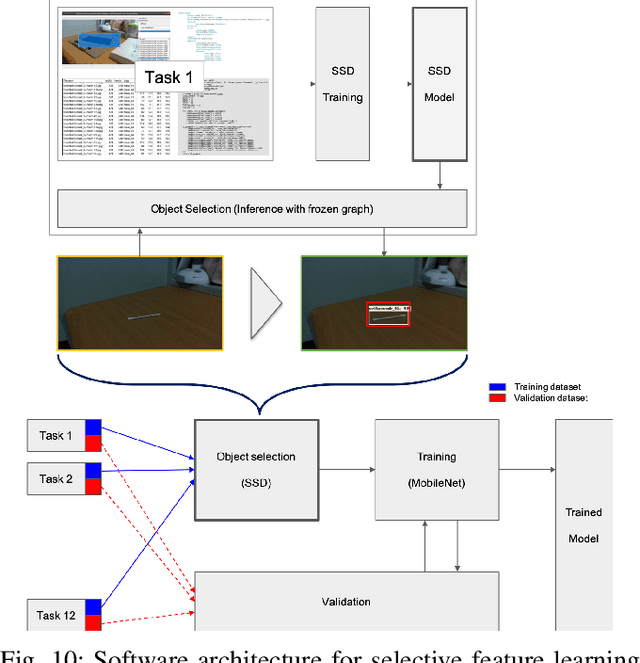
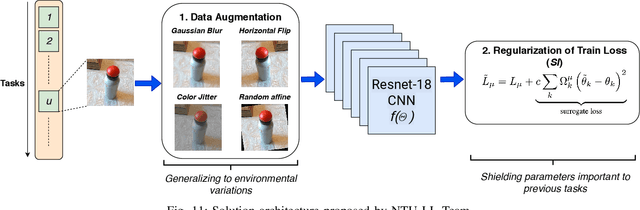

This report summarizes IROS 2019-Lifelong Robotic Vision Competition (Lifelong Object Recognition Challenge) with methods and results from the top $8$ finalists (out of over~$150$ teams). The competition dataset (L)ifel(O)ng (R)obotic V(IS)ion (OpenLORIS) - Object Recognition (OpenLORIS-object) is designed for driving lifelong/continual learning research and application in robotic vision domain, with everyday objects in home, office, campus, and mall scenarios. The dataset explicitly quantifies the variants of illumination, object occlusion, object size, camera-object distance/angles, and clutter information. Rules are designed to quantify the learning capability of the robotic vision system when faced with the objects appearing in the dynamic environments in the contest. Individual reports, dataset information, rules, and released source code can be found at the project homepage: "https://lifelong-robotic-vision.github.io/competition/".
CatNet: Class Incremental 3D ConvNets for Lifelong Egocentric Gesture Recognition
Apr 20, 2020
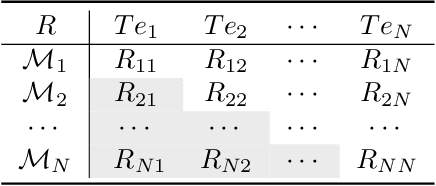

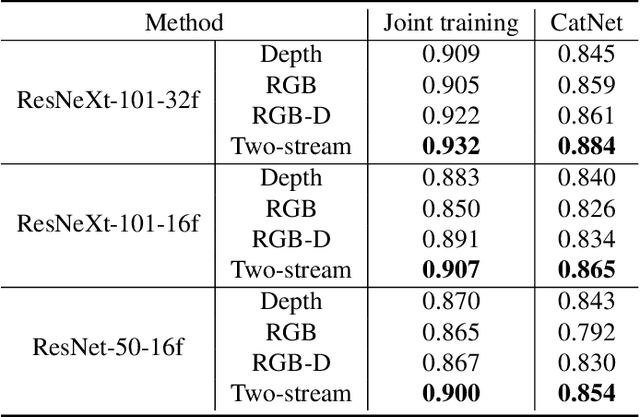
Egocentric gestures are the most natural form of communication for humans to interact with wearable devices such as VR/AR helmets and glasses. A major issue in such scenarios for real-world applications is that may easily become necessary to add new gestures to the system e.g., a proper VR system should allow users to customize gestures incrementally. Traditional deep learning methods require storing all previous class samples in the system and training the model again from scratch by incorporating previous samples and new samples, which costs humongous memory and significantly increases computation over time. In this work, we demonstrate a lifelong 3D convolutional framework -- c(C)la(a)ss increment(t)al net(Net)work (CatNet), which considers temporal information in videos and enables lifelong learning for egocentric gesture video recognition by learning the feature representation of an exemplar set selected from previous class samples. Importantly, we propose a two-stream CatNet, which deploys RGB and depth modalities to train two separate networks. We evaluate CatNets on a publicly available dataset -- EgoGesture dataset, and show that CatNets can learn many classes incrementally over a long period of time. Results also demonstrate that the two-stream architecture achieves the best performance on both joint training and class incremental training compared to 3 other one-stream architectures. The codes and pre-trained models used in this work are provided at https://github.com/villawang/CatNet.
A Neuro-AI Interface for Evaluating Generative Adversarial Networks
Apr 06, 2020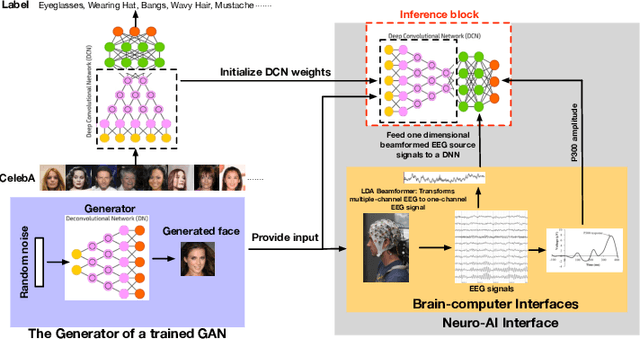

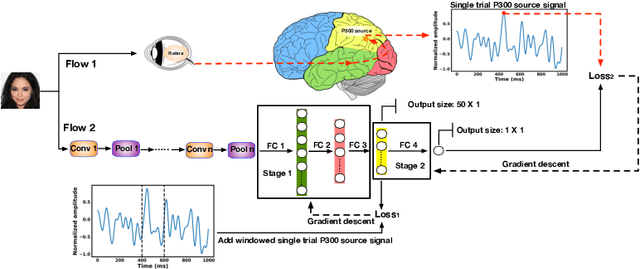

Generative adversarial networks (GANs) are increasingly attracting attention in the computer vision, natural language processing, speech synthesis and similar domains. However, evaluating the performance of GANs is still an open and challenging problem. Existing evaluation metrics primarily measure the dissimilarity between real and generated images using automated statistical methods. They often require large sample sizes for evaluation and do not directly reflect human perception of image quality. In this work, we introduce an evaluation metric called Neuroscore, for evaluating the performance of GANs, that more directly reflects psychoperceptual image quality through the utilization of brain signals. Our results show that Neuroscore has superior performance to the current evaluation metrics in that: (1) It is more consistent with human judgment; (2) The evaluation process needs much smaller numbers of samples; and (3) It is able to rank the quality of images on a per GAN basis. A convolutional neural network (CNN) based neuro-AI interface is proposed to predict Neuroscore from GAN-generated images directly without the need for neural responses. Importantly, we show that including neural responses during the training phase of the network can significantly improve the prediction capability of the proposed model. Codes and data can be referred at this link: https://github.com/villawang/Neuro-AI-Interface.
OpenLORIS-Object: A Dataset and Benchmark towards Lifelong Object Recognition
Nov 15, 2019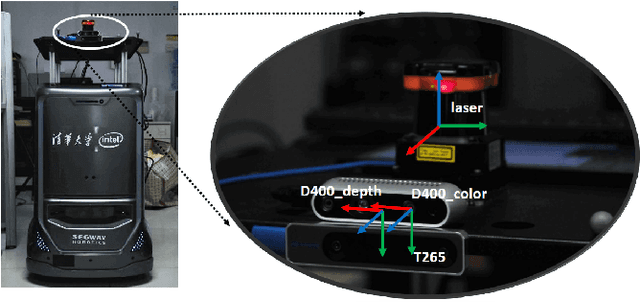


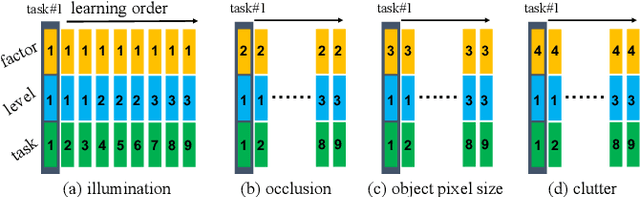
The recent breakthroughs in computer vision have benefited from the availability of large representative datasets (e.g. ImageNet and COCO) for training. Yet, robotic vision poses unique challenges for applying visual algorithms developed from these standard computer vision datasets due to their implicit assumption over non-varying distributions for a fixed set of tasks. Fully retraining models each time a new task becomes available is infeasible due to computational, storage and sometimes privacy issues, while na\"{i}ve incremental strategies have been shown to suffer from catastrophic forgetting. It is crucial for the robots to operate continuously under open-set and detrimental conditions with adaptive visual perceptual systems, where lifelong learning is a fundamental capability. However, very few datasets and benchmarks are available to evaluate and compare emerging techniques. To fill this gap, we provide a new lifelong robotic vision dataset ("OpenLORIS-Object") collected via RGB-D cameras mounted on mobile robots. The dataset embeds the challenges faced by a robot in the real-life application and provides new benchmarks for validating lifelong object recognition algorithms. Moreover, we have provided a testbed of $9$ state-of-the-art lifelong learning algorithms. Each of them involves $48$ tasks with $4$ evaluation metrics over the OpenLORIS-Object dataset. The results demonstrate that the object recognition task in the ever-changing difficulty environments is far from being solved and the bottlenecks are at the forward/backward transfer designs. Our dataset and benchmark are publicly available at \href{https://lifelong-robotic-vision.github.io/dataset/Data_Object-Recognition.html}{\underline{this url}}.