 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Quality of Text-to-Video Model Outputs: Metrics and Dataset
Sep 14, 2023

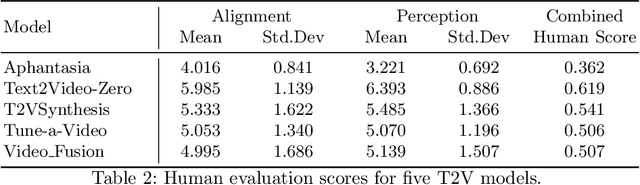
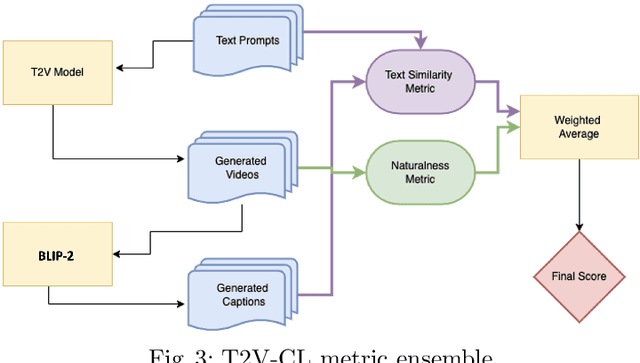
Evaluating the quality of videos generated from text-to-video (T2V) models is important if they are to produce plausible outputs that convince a viewer of their authenticity. We examine some of the metrics used in this area and highlight their limitations. The paper presents a dataset of more than 1,000 generated videos from 5 very recent T2V models on which some of those commonly used quality metrics are applied. We also include extensive human quality evaluations on those videos, allowing the relative strengths and weaknesses of metrics, including human assessment, to be compared. The contribution is an assessment of commonly used quality metrics, and a comparison of their performances and the performance of human evaluations on an open dataset of T2V videos. Our conclusion is that naturalness and semantic matching with the text prompt used to generate the T2V output are important but there is no single measure to capture these subtleties in assessing T2V model output.
IROS 2019 Lifelong Robotic Vision Challenge -- Lifelong Object Recognition Report
Apr 26, 2020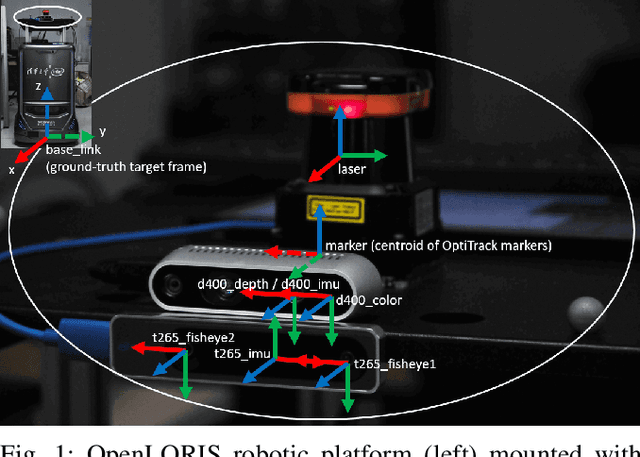
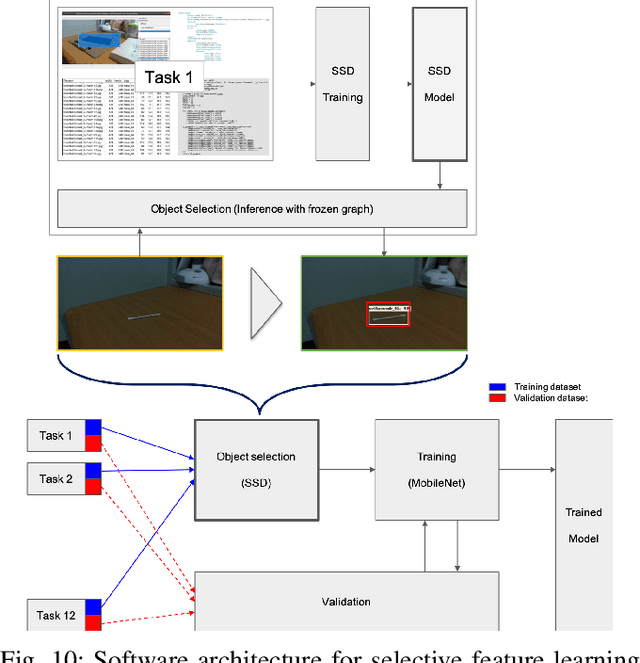
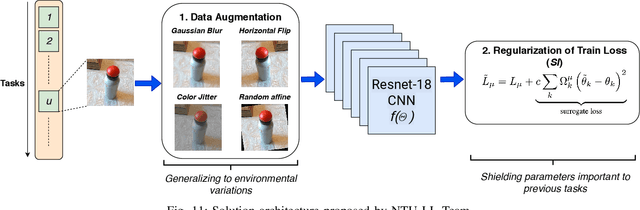

This report summarizes IROS 2019-Lifelong Robotic Vision Competition (Lifelong Object Recognition Challenge) with methods and results from the top $8$ finalists (out of over~$150$ teams). The competition dataset (L)ifel(O)ng (R)obotic V(IS)ion (OpenLORIS) - Object Recognition (OpenLORIS-object) is designed for driving lifelong/continual learning research and application in robotic vision domain, with everyday objects in home, office, campus, and mall scenarios. The dataset explicitly quantifies the variants of illumination, object occlusion, object size, camera-object distance/angles, and clutter information. Rules are designed to quantify the learning capability of the robotic vision system when faced with the objects appearing in the dynamic environments in the contest. Individual reports, dataset information, rules, and released source code can be found at the project homepage: "https://lifelong-robotic-vision.github.io/competition/".
A Neuro-AI Interface for Evaluating Generative Adversarial Networks
Apr 06, 2020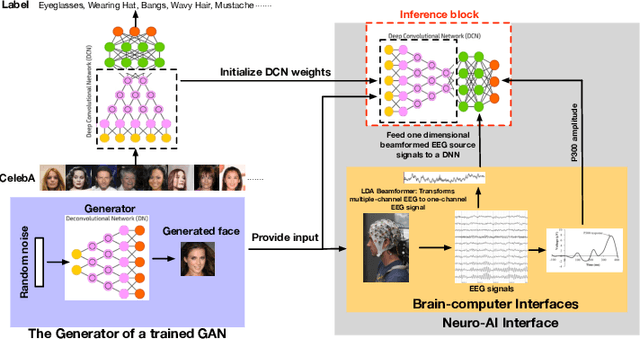

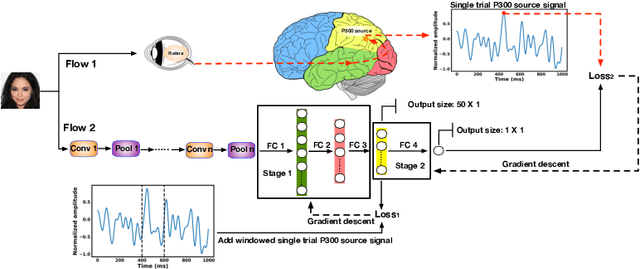

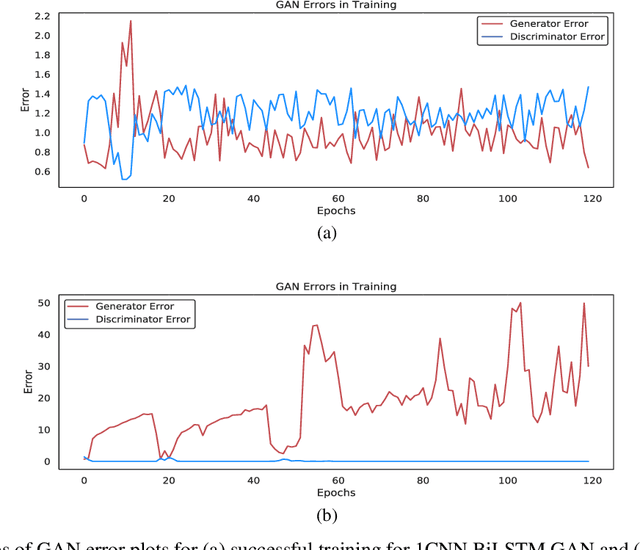
Generative adversarial networks (GANs) are increasingly attracting attention in the computer vision, natural language processing, speech synthesis and similar domains. However, evaluating the performance of GANs is still an open and challenging problem. Existing evaluation metrics primarily measure the dissimilarity between real and generated images using automated statistical methods. They often require large sample sizes for evaluation and do not directly reflect human perception of image quality. In this work, we introduce an evaluation metric called Neuroscore, for evaluating the performance of GANs, that more directly reflects psychoperceptual image quality through the utilization of brain signals. Our results show that Neuroscore has superior performance to the current evaluation metrics in that: (1) It is more consistent with human judgment; (2) The evaluation process needs much smaller numbers of samples; and (3) It is able to rank the quality of images on a per GAN basis. A convolutional neural network (CNN) based neuro-AI interface is proposed to predict Neuroscore from GAN-generated images directly without the need for neural responses. Importantly, we show that including neural responses during the training phase of the network can significantly improve the prediction capability of the proposed model. Codes and data can be referred at this link: https://github.com/villawang/Neuro-AI-Interface.
Predicting Injectable Medication Adherence via a Smart Sharps Bin and Machine Learning
Apr 02, 2020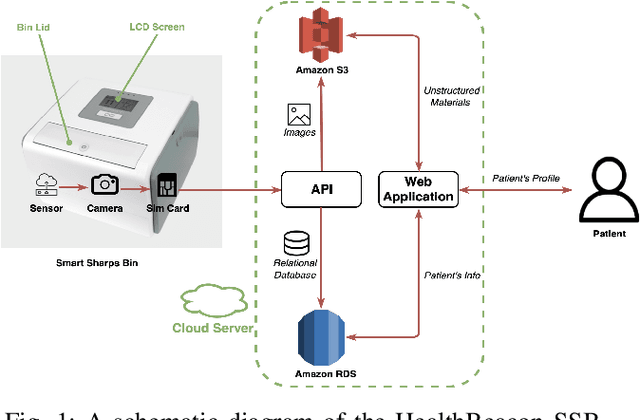
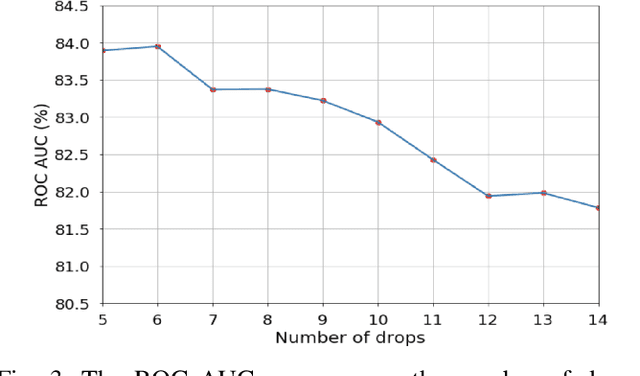
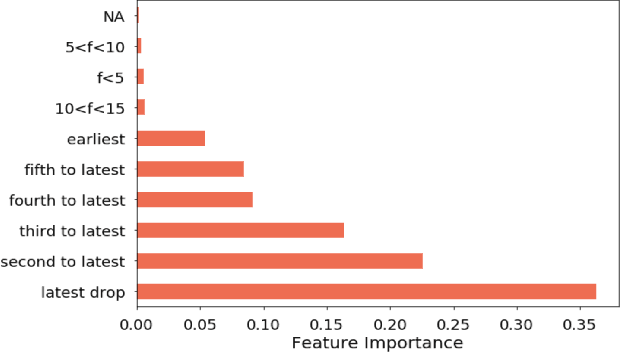
Medication non-adherence is a widespread problem affecting over 50% of people who have chronic illness and need chronic treatment. Non-adherence exacerbates health risks and drives significant increases in treatment costs. In order to address these challenges, the importance of predicting patients' adherence has been recognised. In other words, it is important to improve the efficiency of interventions of the current healthcare system by prioritizing resources to the patients who are most likely to be non-adherent. Our objective in this work is to make predictions regarding individual patients' behaviour in terms of taking their medication on time during their next scheduled medication opportunity. We do this by leveraging a number of machine learning models. In particular, we demonstrate the use of a connected IoT device; a "Smart Sharps Bin", invented by HealthBeacon Ltd.; to monitor and track injection disposal of patients in their home environment. Using extensive data collected from these devices, five machine learning models, namely Extra Trees Classifier, Random Forest, XGBoost, Gradient Boosting and Multilayer Perception were trained and evaluated on a large dataset comprising 165,223 historic injection disposal records collected from 5,915 HealthBeacon units over the course of 3 years. The testing work was conducted on real-time data generated by the smart device over a time period after the model training was complete, i.e. true future data. The proposed machine learning approach demonstrated very good predictive performance exhibiting an Area Under the Receiver Operating Characteristic Curve (ROC AUC) of 0.86.
Optimised Convolutional Neural Networks for Heart Rate Estimation and Human Activity Recognition in Wrist Worn Sensing Applications
Mar 30, 2020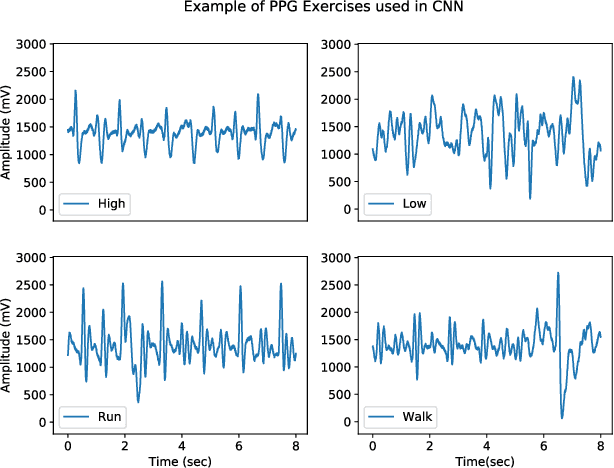

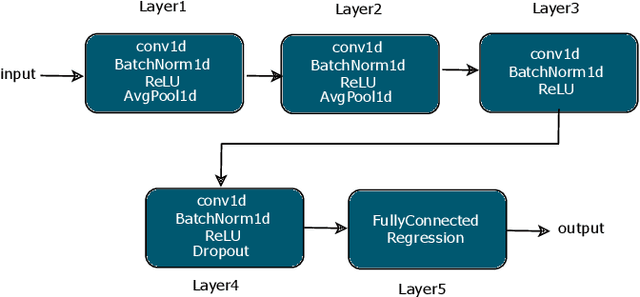
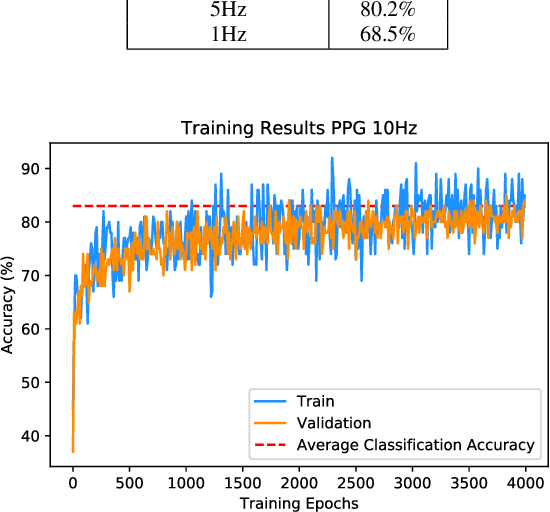
Wrist-worn smart devices are providing increased insights into human health, behaviour and performance through sophisticated analytics. However, battery life, device cost and sensor performance in the face of movement-related artefact present challenges which must be further addressed to see effective applications and wider adoption through commoditisation of the technology. We address these challenges by demonstrating, through using a simple optical measurement, photoplethysmography (PPG) used conventionally for heart rate detection in wrist-worn sensors, that we can provide improved heart rate and human activity recognition (HAR) simultaneously at low sample rates, without an inertial measurement unit. This simplifies hardware design and reduces costs and power budgets. We apply two deep learning pipelines, one for human activity recognition and one for heart rate estimation. HAR is achieved through the application of a visual classification approach, capable of robust performance at low sample rates. Here, transfer learning is leveraged to retrain a convolutional neural network (CNN) to distinguish characteristics of the PPG during different human activities. For heart rate estimation we use a CNN adopted for regression which maps noisy optical signals to heart rate estimates. In both cases, comparisons are made with leading conventional approaches. Our results demonstrate a low sampling frequency can achieve good performance without significant degradation of accuracy. 5 Hz and 10 Hz were shown to have 80.2% and 83.0% classification accuracy for HAR respectively. These same sampling frequencies also yielded a robust heart rate estimation which was comparative with that achieved at the more energy-intensive rate of 256 Hz.
Synthesis of Realistic ECG using Generative Adversarial Networks
Sep 19, 2019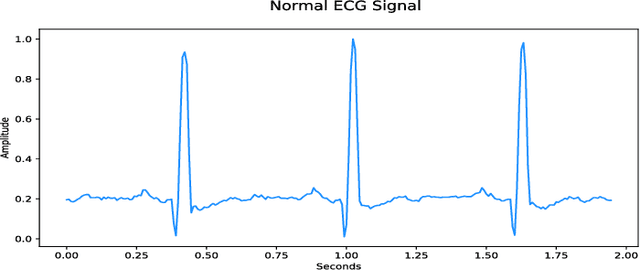
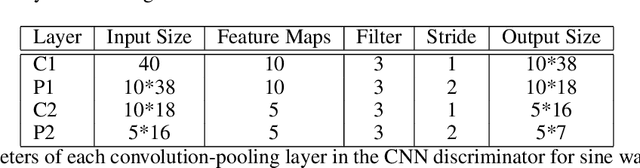
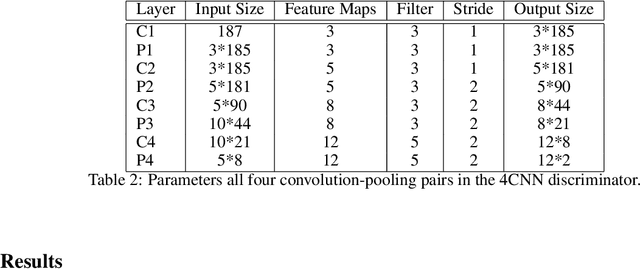
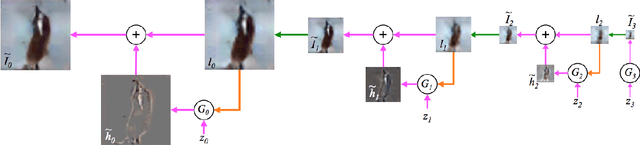
Access to medical data is highly restricted due to its sensitive nature, preventing communities from using this data for research or clinical training. Common methods of de-identification implemented to enable the sharing of data are sometimes inadequate to protect the individuals contained in the data. For our research, we investigate the ability of generative adversarial networks (GANs) to produce realistic medical time series data which can be used without concerns over privacy. The aim is to generate synthetic ECG signals representative of normal ECG waveforms. GANs have been used successfully to generate good quality synthetic time series and have been shown to prevent re-identification of individual records. In this work, a range of GAN architectures are developed to generate synthetic sine waves and synthetic ECG. Two evaluation metrics are then used to quantitatively assess how suitable the synthetic data is for real world applications such as clinical training and data analysis. Finally, we discuss the privacy concerns associated with sharing synthetic data produced by GANs and test their ability to withstand a simple membership inference attack. For the first time we both quantitatively and qualitatively demonstrate that GAN architecture can successfully generate time series signals that are not only structurally similar to the training sets but also diverse in nature across generated samples. We also report on their ability to withstand a simple membership inference attack, protecting the privacy of the training set.
Generative Adversarial Networks: A Survey and Taxonomy
Jun 14, 2019


Generative adversarial networks (GANs) have been extensively studied in the past few years. Arguably the revolutionary techniques are in the area of computer vision such as plausible image generation, image to image translation, facial attribute manipulation and similar domains. Despite the significant success achieved in the computer vision field, applying GANs to real-world problems still poses significant challenges, three of which we focus on here: (1) High quality image generation; (2) Diverse image generation; and (3) Stable training. Through an in-depth review of GAN-related research in the literature, we provide an account of the architecture-variants and loss-variants, which have been proposed to handle these three challenges from two perspectives. We propose loss-variants and architecture-variants for classifying the most popular GANs, and discuss the potential improvements with focusing on these two aspects. While several reviews for GANs have been presented to date, none have focused on the review of GAN-variants based on their handling the challenges mentioned above. In this paper, we review and critically discuss 7 architecture-variant GANs and 9 loss-variant GANs for remedying those three challenges. The objective of this review is to provide an insight on the footprint that current GANs research focuses on the performance improvement. Code related to GAN-variants studied in this work is summarized on https://github.com/sheqi/GAN_Review.
Neuroscore: A Brain-inspired Evaluation Metric for Generative Adversarial Networks
May 10, 2019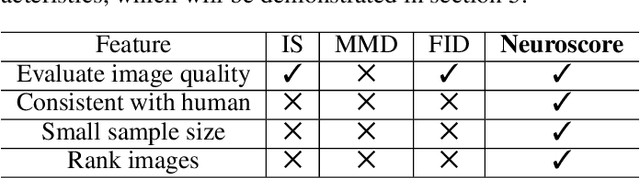
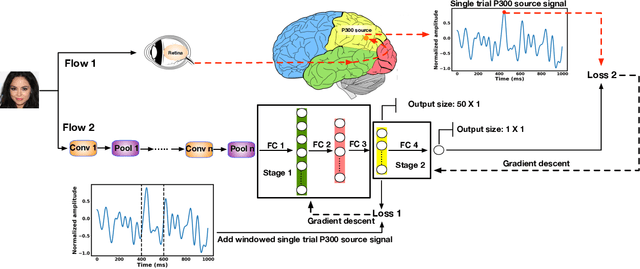


Generative adversarial networks (GANs) are increasingly attracting attention in the computer vision, natural language processing, speech synthesis and similar domains. Arguably the most striking results have been in the area of image synthesis. However, evaluating the performance of GANs is still an open and challenging problem. Existing evaluation metrics primarily measure the dissimilarity between real and generated images using automated statistical methods. They often require large sample sizes for evaluation and do not directly reflect the human perception of the image quality. In this work, we introduce an evaluation metric we call Neuroscore, for evaluating the performance of GANs, that more directly reflects psychoperceptual image quality through the utilization of brain signals. Our results show that Neuroscore has superior performances to the current evaluation metrics in that: (1) It is more consistent with human judgment; (2) The evaluation process needs much smaller numbers of samples; and (3) It is able to rank the quality of images on a per GAN basis. A convolutional neural network based brain-inspired framework is also proposed to predict Neuroscore from GAN-generated images. Importantly, we show that including neural responses during the training phase of the network can significantly improve the prediction capability of the proposed model.
Quick and Easy Time Series Generation with Established Image-based GANs
Feb 18, 2019
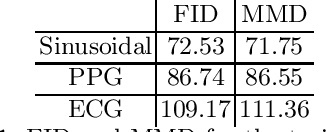

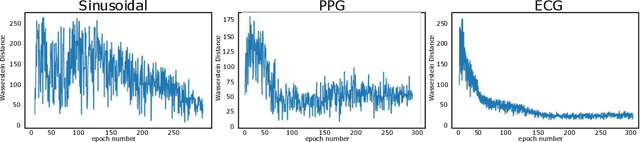
In the recent years Generative Adversarial Networks (GANs) have demonstrated significant progress in generating authentic looking data. In this work we introduce our simple method to exploit the advancements in well established image-based GANs to synthesise single channel time series data. We implement Wasserstein GANs (WGANs) with gradient penalty due to their stability in training to synthesise three different types of data; sinusoidal data, photoplethysmograph (PPG) data and electrocardiograph (ECG) data. The length of the returned time series data is limited only by the image resolution, we use an image size of 64x64 pixels which yields 4096 data points. We present both visual and quantitative evidence that our novel method can successfully generate time series data using image-based GANs.
Spatial Filtering Pipeline Evaluation of Cortically Coupled Computer Vision System for Rapid Serial Visual Presentation
Jan 15, 2019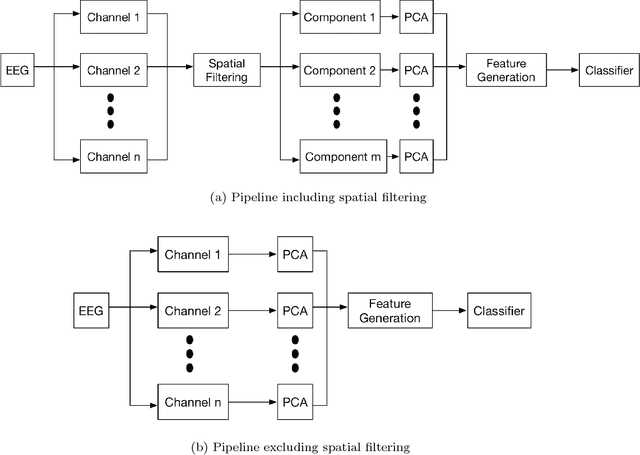


Rapid Serial Visual Presentation (RSVP) is a paradigm that supports the application of cortically coupled computer vision to rapid image search. In RSVP, images are presented to participants in a rapid serial sequence which can evoke Event-related Potentials (ERPs) detectable in their Electroencephalogram (EEG). The contemporary approach to this problem involves supervised spatial filtering techniques which are applied for the purposes of enhancing the discriminative information in the EEG data. In this paper we make two primary contributions to that field: 1) We propose a novel spatial filtering method which we call the Multiple Time Window LDA Beamformer (MTWLB) method; 2) we provide a comprehensive comparison of nine spatial filtering pipelines using three spatial filtering schemes namely, MTWLB, xDAWN, Common Spatial Pattern (CSP) and three linear classification methods Linear Discriminant Analysis (LDA), Bayesian Linear Regression (BLR) and Logistic Regression (LR). Three pipelines without spatial filtering are used as baseline comparison. The Area Under Curve (AUC) is used as an evaluation metric in this paper. The results reveal that MTWLB and xDAWN spatial filtering techniques enhance the classification performance of the pipeline but CSP does not. The results also support the conclusion that LR can be effective for RSVP based BCI if discriminative features are available.