 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniTac-NV: A Unified Tactile Representation For Non-Vision-Based Tactile Sensors
Jun 24, 2025Generalizable algorithms for tactile sensing remain underexplored, primarily due to the diversity of sensor modalities. Recently, many methods for cross-sensor transfer between optical (vision-based) tactile sensors have been investigated, yet little work focus on non-optical tactile sensors. To address this gap, we propose an encoder-decoder architecture to unify tactile data across non-vision-based sensors. By leveraging sensor-specific encoders, the framework creates a latent space that is sensor-agnostic, enabling cross-sensor data transfer with low errors and direct use in downstream applications. We leverage this network to unify tactile data from two commercial tactile sensors: the Xela uSkin uSPa 46 and the Contactile PapillArray. Both were mounted on a UR5e robotic arm, performing force-controlled pressing sequences against distinct object shapes (circular, square, and hexagonal prisms) and two materials (rigid PLA and flexible TPU). Another more complex unseen object was also included to investigate the model's generalization capabilities. We show that alignment in latent space can be implicitly learned from joint autoencoder training with matching contacts collected via different sensors. We further demonstrate the practical utility of our approach through contact geometry estimation, where downstream models trained on one sensor's latent representation can be directly applied to another without retraining.
Knowledge Distilled Ensemble Model for sEMG-based Silent Speech Interface
Aug 07, 2023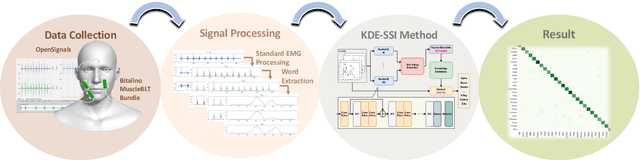
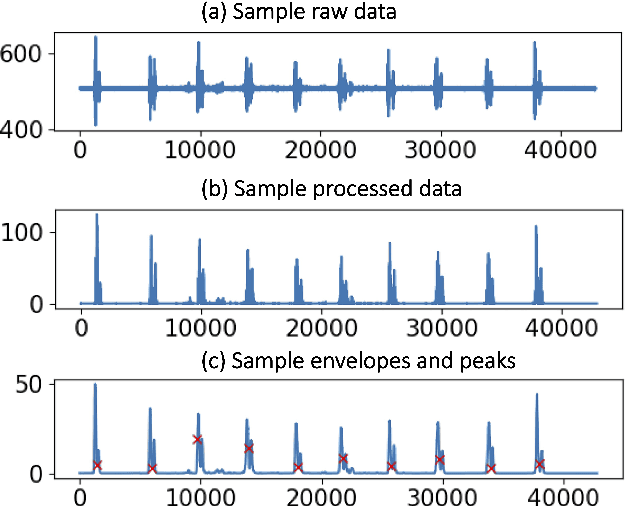
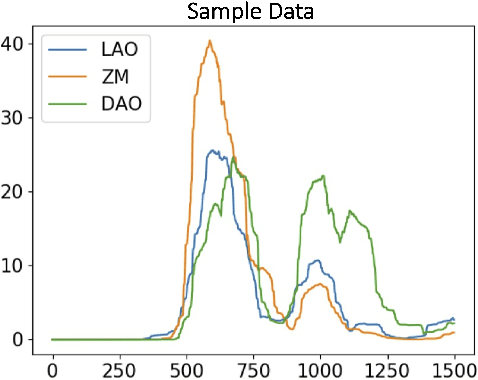
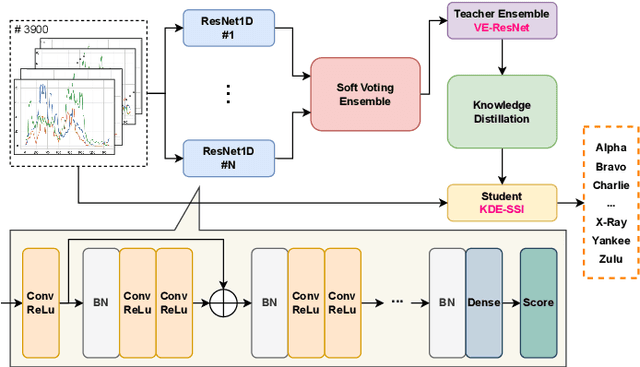
Voice disorders affect millions of people worldwide. Surface electromyography-based Silent Speech Interfaces (sEMG-based SSIs) have been explored as a potential solution for decades. However, previous works were limited by small vocabularies and manually extracted features from raw data. To address these limitations, we propose a lightweight deep learning knowledge-distilled ensemble model for sEMG-based SSI (KDE-SSI). Our model can classify a 26 NATO phonetic alphabets dataset with 3900 data samples, enabling the unambiguous generation of any English word through spelling. Extensive experiments validate the effectiveness of KDE-SSI, achieving a test accuracy of 85.9\%. Our findings also shed light on an end-to-end system for portable, practical equipment.
A Benchmark and Empirical Analysis for Replay Strategies in Continual Learning
Aug 04, 2022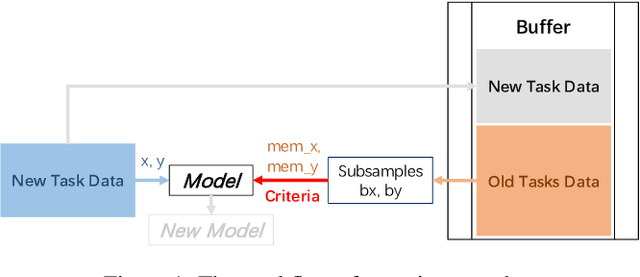
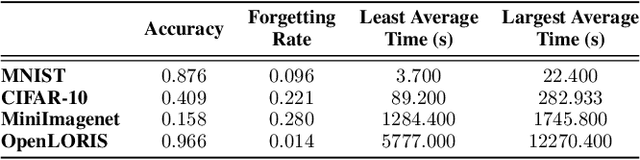
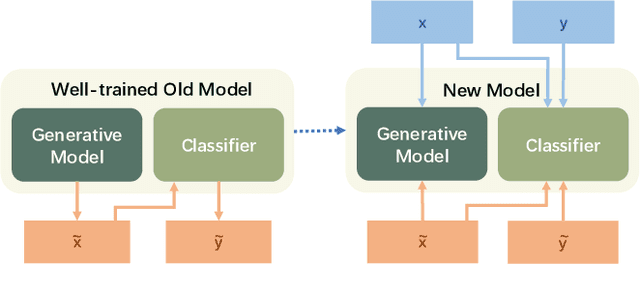

With the capacity of continual learning, humans can continuously acquire knowledge throughout their lifespan. However, computational systems are not, in general, capable of learning tasks sequentially. This long-standing challenge for deep neural networks (DNNs) is called catastrophic forgetting. Multiple solutions have been proposed to overcome this limitation. This paper makes an in-depth evaluation of the memory replay methods, exploring the efficiency, performance, and scalability of various sampling strategies when selecting replay data. All experiments are conducted on multiple datasets under various domains. Finally, a practical solution for selecting replay methods for various data distributions is provided.
IROS 2019 Lifelong Robotic Vision Challenge -- Lifelong Object Recognition Report
Apr 26, 2020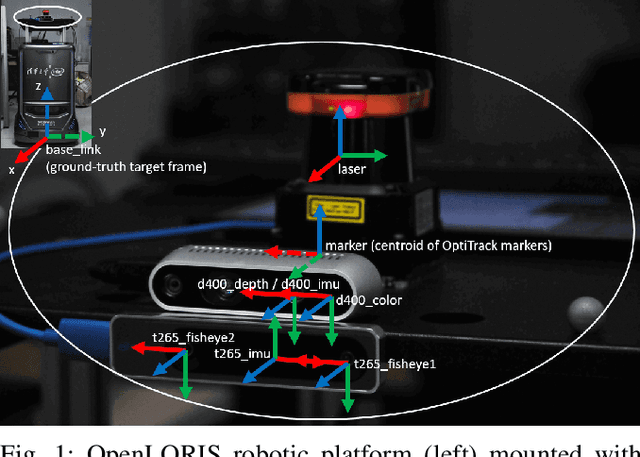
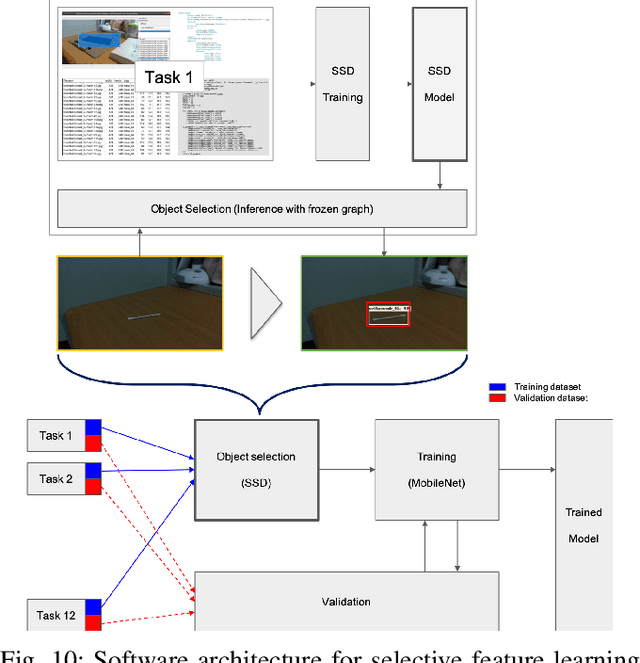
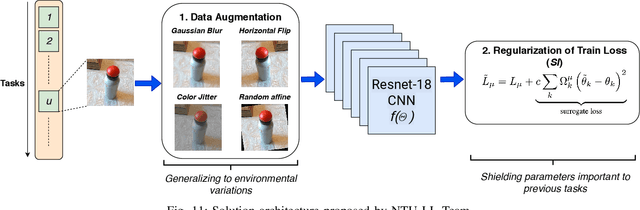

This report summarizes IROS 2019-Lifelong Robotic Vision Competition (Lifelong Object Recognition Challenge) with methods and results from the top $8$ finalists (out of over~$150$ teams). The competition dataset (L)ifel(O)ng (R)obotic V(IS)ion (OpenLORIS) - Object Recognition (OpenLORIS-object) is designed for driving lifelong/continual learning research and application in robotic vision domain, with everyday objects in home, office, campus, and mall scenarios. The dataset explicitly quantifies the variants of illumination, object occlusion, object size, camera-object distance/angles, and clutter information. Rules are designed to quantify the learning capability of the robotic vision system when faced with the objects appearing in the dynamic environments in the contest. Individual reports, dataset information, rules, and released source code can be found at the project homepage: "https://lifelong-robotic-vision.github.io/competition/".
OpenLORIS-Object: A Dataset and Benchmark towards Lifelong Object Recognition
Nov 15, 2019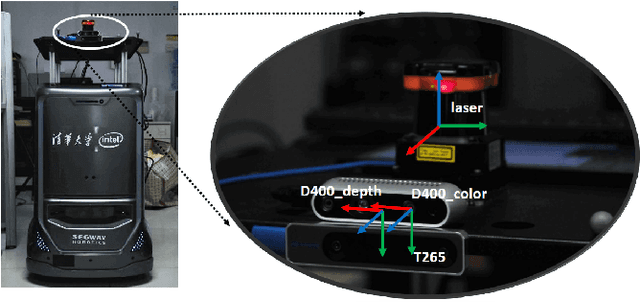


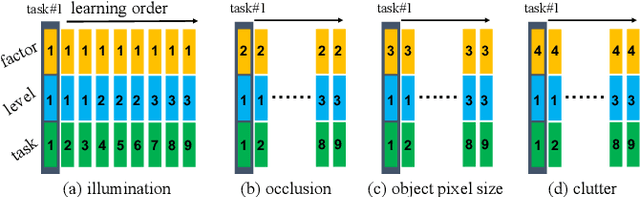
The recent breakthroughs in computer vision have benefited from the availability of large representative datasets (e.g. ImageNet and COCO) for training. Yet, robotic vision poses unique challenges for applying visual algorithms developed from these standard computer vision datasets due to their implicit assumption over non-varying distributions for a fixed set of tasks. Fully retraining models each time a new task becomes available is infeasible due to computational, storage and sometimes privacy issues, while na\"{i}ve incremental strategies have been shown to suffer from catastrophic forgetting. It is crucial for the robots to operate continuously under open-set and detrimental conditions with adaptive visual perceptual systems, where lifelong learning is a fundamental capability. However, very few datasets and benchmarks are available to evaluate and compare emerging techniques. To fill this gap, we provide a new lifelong robotic vision dataset ("OpenLORIS-Object") collected via RGB-D cameras mounted on mobile robots. The dataset embeds the challenges faced by a robot in the real-life application and provides new benchmarks for validating lifelong object recognition algorithms. Moreover, we have provided a testbed of $9$ state-of-the-art lifelong learning algorithms. Each of them involves $48$ tasks with $4$ evaluation metrics over the OpenLORIS-Object dataset. The results demonstrate that the object recognition task in the ever-changing difficulty environments is far from being solved and the bottlenecks are at the forward/backward transfer designs. Our dataset and benchmark are publicly available at \href{https://lifelong-robotic-vision.github.io/dataset/Data_Object-Recognition.html}{\underline{this url}}.
Fractional spectral graph wavelets and their applications
Feb 27, 2019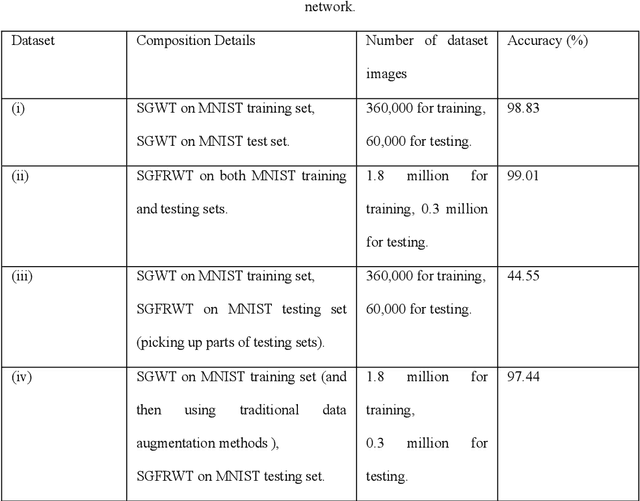
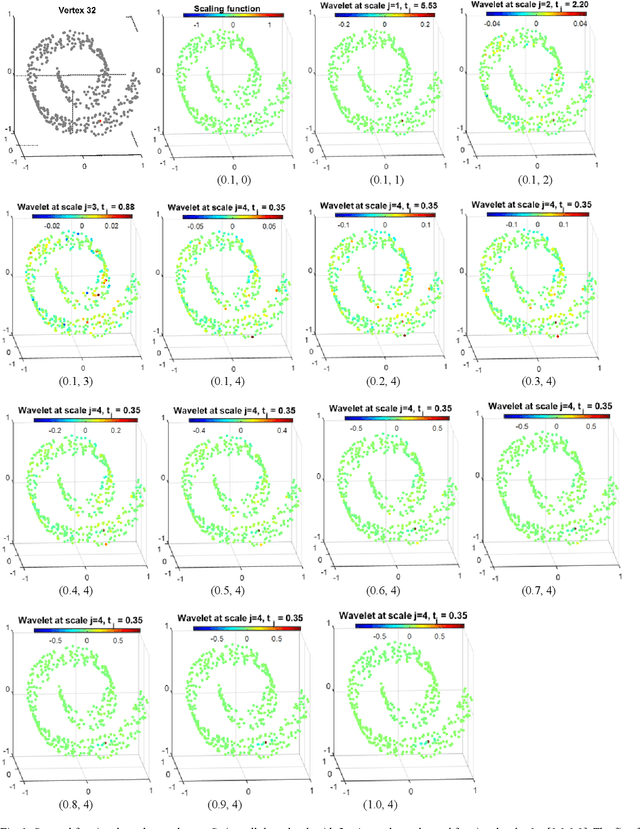


One of the key challenges in the area of signal processing on graphs is to design transforms and dictionaries methods to identify and exploit structure in signals on weighted graphs. In this paper, we first generalize graph Fourier transform (GFT) to graph fractional Fourier transform (GFRFT), which is then used to define a novel transform named spectral graph fractional wavelet transform (SGFRWT), which is a generalized and extended version of spectral graph wavelet transform (SGWT). A fast algorithm for SGFRWT is also derived and implemented based on Fourier series approximation. The potential applications of SGFRWT are also presented.