 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEAM-Net: Multi-modal Learning for Video Action Recognition with Partial Decoding
Paper and Code



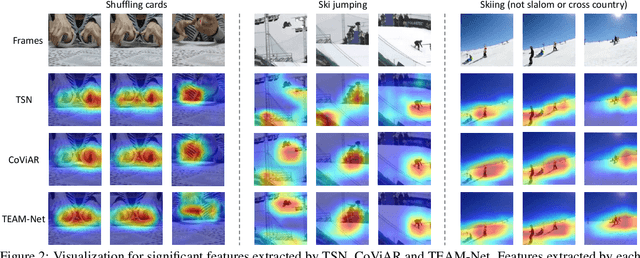
Most of existing video action recognition models ingest raw RGB frames. However, the raw video stream requires enormous storage and contains significant temporal redundancy. Video compression (e.g., H.264, MPEG-4) reduces superfluous information by representing the raw video stream using the concept of Group of Pictures (GOP). Each GOP is composed of the first I-frame (aka RGB image) followed by a number of P-frames, represented by motion vectors and residuals, which can be regarded and used as pre-extracted features. In this work, we 1) introduce sampling the input for the network from partially decoded videos based on the GOP-level, and 2) propose a plug-and-play mulTi-modal lEArning Module (TEAM) for training the network using information from I-frames and P-frames in an end-to-end manner. We demonstrate the superior performance of TEAM-Net compared to the baseline using RGB only. TEAM-Net also achieves the state-of-the-art performance in the area of video action recognition with partial decoding. Code is provided at https://github.com/villawang/TEAM-Net.