 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUperFormer: A Multi-scale Transformer-based Decoder for Semantic Segmentation
Nov 25, 2022



While a large number of recent works on semantic segmentation focus on designing and incorporating a transformer-based encoder, much less attention and vigor have been devoted to transformer-based decoders. For such a task whose hallmark quest is pixel-accurate prediction, we argue that the decoder stage is just as crucial as that of the encoder in achieving superior segmentation performance, by disentangling and refining the high-level cues and working out object boundaries with pixel-level precision. In this paper, we propose a novel transformer-based decoder called UperFormer, which is plug-and-play for hierarchical encoders and attains high quality segmentation results regardless of encoder architecture. UperFormer is equipped with carefully designed multi-head skip attention units and novel upsampling operations. Multi-head skip attention is able to fuse multi-scale features from backbones with those in decoders. The upsampling operation, which incorporates feature from encoder, can be more friendly for object localization. It brings a 0.4% to 3.2% increase compared with traditional upsampling methods. By combining UperFormer with Swin Transformer (Swin-T), a fully transformer-based symmetric network is formed for semantic segmentation tasks. Extensive experiments show that our proposed approach is highly effective and computationally efficient. On Cityscapes dataset, we achieve state-of-the-art performance. On the more challenging ADE20K dataset, our best model yields a single-scale mIoU of 50.18, and a multi-scale mIoU of 51.8, which is on-par with the current state-of-art model, while we drastically cut the number of FLOPs by 53.5%. Our source code and models are publicly available at: https://github.com/shiwt03/UperFormer
Unifying Training and Inference for Panoptic Segmentation
Jan 14, 2020
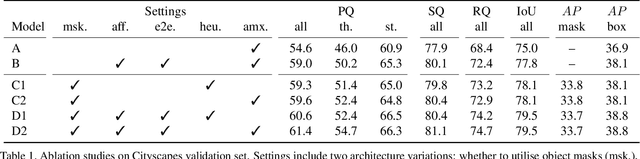
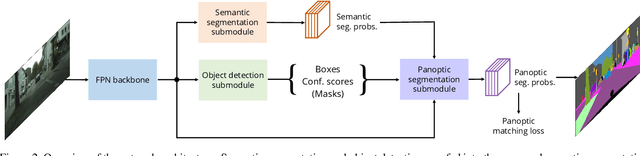
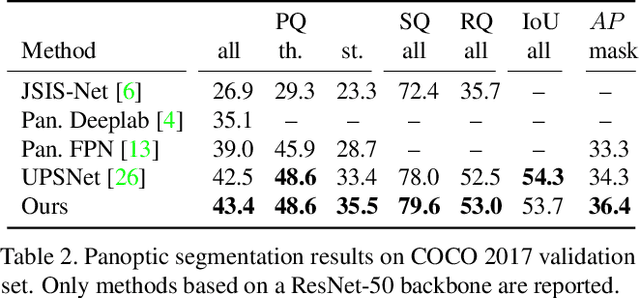
We present an end-to-end network to bridge the gap between training and inference pipeline for panoptic segmentation, a task that seeks to partition an image into semantic regions for "stuff" and object instances for "things". In contrast to recent works, our network exploits a parametrised, yet lightweight panoptic segmentation submodule, powered by an end-to-end learnt dense instance affinity, to capture the probability that any pair of pixels belong to the same instance. This panoptic submodule gives rise to a novel propagation mechanism for panoptic logits and enables the network to output a coherent panoptic segmentation map for both "stuff" and "thing" classes, without any post-processing. Reaping the benefits of end-to-end training, our full system sets new records on the popular street scene dataset, Cityscapes, achieving 61.4 PQ with a ResNet-50 backbone using only the fine annotations. On the challenging COCO dataset, our ResNet-50-based network also delivers state-of-the-art accuracy of 43.4 PQ. Moreover, our network flexibly works with and without object mask cues, performing competitively under both settings, which is of interest for applications with computation budgets.
Metric Attack and Defense for Person Re-identification
Mar 23, 2019


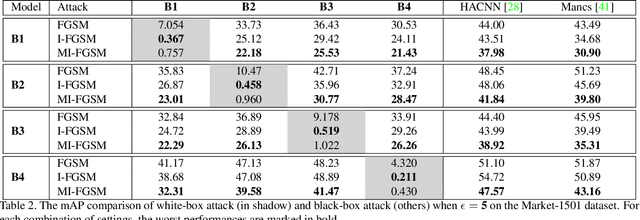
Person re-identification (re-ID) has attracted much attention recently due to its great importance in video surveillance. In general, distance metrics used to identify two person images are expected to be robust under various appearance changes. However, our work observes the extreme vulnerability of existing distance metrics to adversarial examples, generated by simply adding human-imperceptible perturbations to person images. Hence, the security danger is dramatically increased when deploying commercial re-ID systems in video surveillance. Although adversarial examples have been extensively applied for classification analysis, it is rarely studied in metric analysis like person re-identification. The most likely reason is the natural gap between the training and testing of re-ID networks, that is, the predictions of a re-ID network cannot be directly used during testing without an effective metric. In this work, we bridge the gap by proposing Adversarial Metric Attack, a parallel methodology to adversarial classification attacks. Comprehensive experiments clearly reveal the adversarial effects in re-ID systems. Meanwhile, we also present an early attempt of training a metric-preserving network, thereby defending the metric against adversarial attacks. At last, by benchmarking various adversarial settings, we expect that our work can facilitate the development of adversarial attack and defense in metric-based applications.
Weakly- and Semi-Supervised Panoptic Segmentation
Aug 10, 2018


We present a weakly supervised model that jointly performs both semantic- and instance-segmentation -- a particularly relevant problem given the substantial cost of obtaining pixel-perfect annotation for these tasks. In contrast to many popular instance segmentation approaches based on object detectors, our method does not predict any overlapping instances. Moreover, we are able to segment both "thing" and "stuff" classes, and thus explain all the pixels in the image. "Thing" classes are weakly-supervised with bounding boxes, and "stuff" with image-level tags. We obtain state-of-the-art results on Pascal VOC, for both full and weak supervision (which achieves about 95% of fully-supervised performance). Furthermore, we present the first weakly-supervised results on Cityscapes for both semantic- and instance-segmentation. Finally, we use our weakly supervised framework to analyse the relationship between annotation quality and predictive performance, which is of interest to dataset creators.
Holistic, Instance-Level Human Parsing
Sep 11, 2017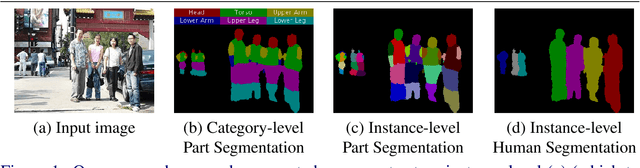
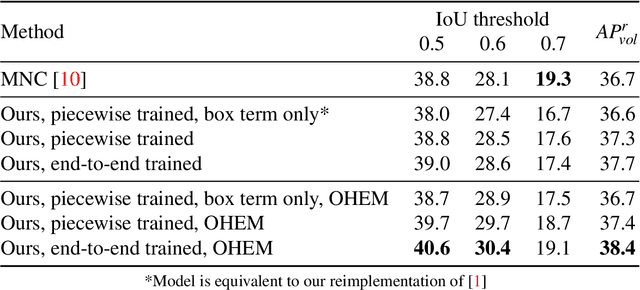
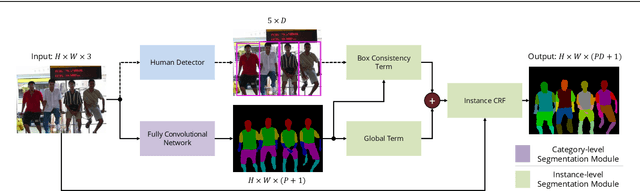
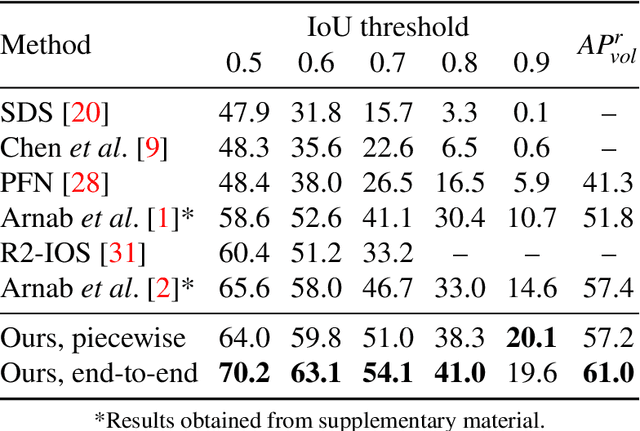
Object parsing -- the task of decomposing an object into its semantic parts -- has traditionally been formulated as a category-level segmentation problem. Consequently, when there are multiple objects in an image, current methods cannot count the number of objects in the scene, nor can they determine which part belongs to which object. We address this problem by segmenting the parts of objects at an instance-level, such that each pixel in the image is assigned a part label, as well as the identity of the object it belongs to. Moreover, we show how this approach benefits us in obtaining segmentations at coarser granularities as well. Our proposed network is trained end-to-end given detections, and begins with a category-level segmentation module. Thereafter, a differentiable Conditional Random Field, defined over a variable number of instances for every input image, reasons about the identity of each part by associating it with a human detection. In contrast to other approaches, our method can handle the varying number of people in each image and our holistic network produces state-of-the-art results in instance-level part and human segmentation, together with competitive results in category-level part segmentation, all achieved by a single forward-pass through our neural network.