 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatNet: Class Incremental 3D ConvNets for Lifelong Egocentric Gesture Recognition
Apr 20, 2020

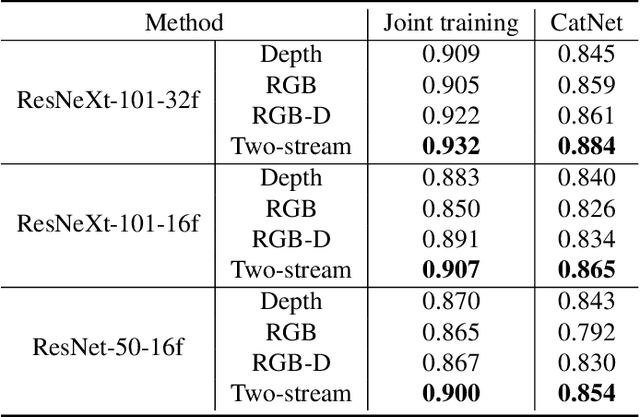
Egocentric gestures are the most natural form of communication for humans to interact with wearable devices such as VR/AR helmets and glasses. A major issue in such scenarios for real-world applications is that may easily become necessary to add new gestures to the system e.g., a proper VR system should allow users to customize gestures incrementally. Traditional deep learning methods require storing all previous class samples in the system and training the model again from scratch by incorporating previous samples and new samples, which costs humongous memory and significantly increases computation over time. In this work, we demonstrate a lifelong 3D convolutional framework -- c(C)la(a)ss increment(t)al net(Net)work (CatNet), which considers temporal information in videos and enables lifelong learning for egocentric gesture video recognition by learning the feature representation of an exemplar set selected from previous class samples. Importantly, we propose a two-stream CatNet, which deploys RGB and depth modalities to train two separate networks. We evaluate CatNets on a publicly available dataset -- EgoGesture dataset, and show that CatNets can learn many classes incrementally over a long period of time. Results also demonstrate that the two-stream architecture achieves the best performance on both joint training and class incremental training compared to 3 other one-stream architectures. The codes and pre-trained models used in this work are provided at https://github.com/villawang/CatNet.
Simultaneous Segmentation and Recognition: Towards more accurate Ego Gesture Recognition
Sep 18, 2019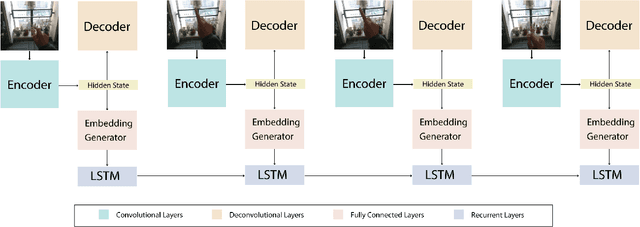
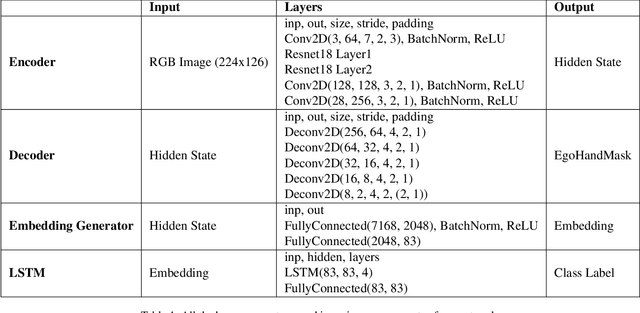
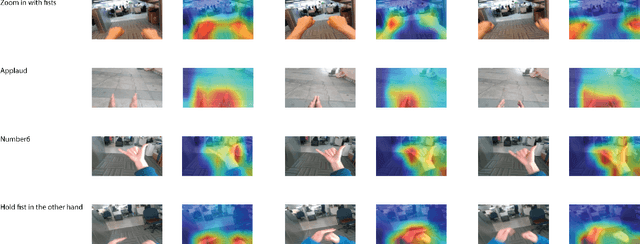

Ego hand gestures can be used as an interface in AR and VR environments. While the context of an image is important for tasks like scene understanding, object recognition, image caption generation and activity recognition, it plays a minimal role in ego hand gesture recognition. An ego hand gesture used for AR and VR environments conveys the same information regardless of the background. With this idea in mind, we present our work on ego hand gesture recognition that produces embeddings from RBG images with ego hands, which are simultaneously used for ego hand segmentation and ego gesture recognition. To this extent, we achieved better recognition accuracy (96.9%) compared to the state of the art (92.2%) on the biggest ego hand gesture dataset available publicly. We present a gesture recognition deep neural network which recognises ego hand gestures from videos (videos containing a single gesture) by generating and recognising embeddings of ego hands from image sequences of varying length. We introduce the concept of simultaneous segmentation and recognition applied to ego hand gestures, present the network architecture, the training procedure and the results compared to the state of the art on the EgoGesture dataset
STaDA: Style Transfer as Data Augmentation
Sep 03, 2019
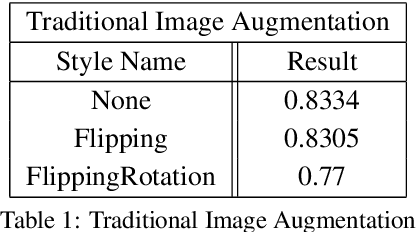

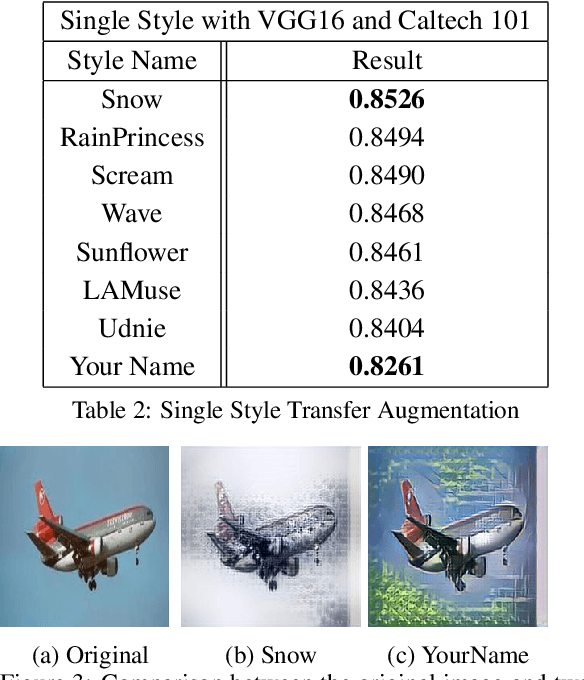
The success of training deep Convolutional Neural Networks (CNNs) heavily depends on a significant amount of labelled data. Recent research has found that neural style transfer algorithms can apply the artistic style of one image to another image without changing the latter's high-level semantic content, which makes it feasible to employ neural style transfer as a data augmentation method to add more variation to the training dataset. The contribution of this paper is a thorough evaluation of the effectiveness of the neural style transfer as a data augmentation method for image classification tasks. We explore the state-of-the-art neural style transfer algorithms and apply them as a data augmentation method on Caltech 101 and Caltech 256 dataset, where we found around 2% improvement from 83% to 85% of the image classification accuracy with VGG16, compared with traditional data augmentation strategies. We also combine this new method with conventional data augmentation approaches to further improve the performance of image classification. This work shows the potential of neural style transfer in computer vision field, such as helping us to reduce the difficulty of collecting sufficient labelled data and improve the performance of generic image-based deep learning algorithms.
Egocentric Gesture Recognition for Head-Mounted AR devices
Aug 16, 2018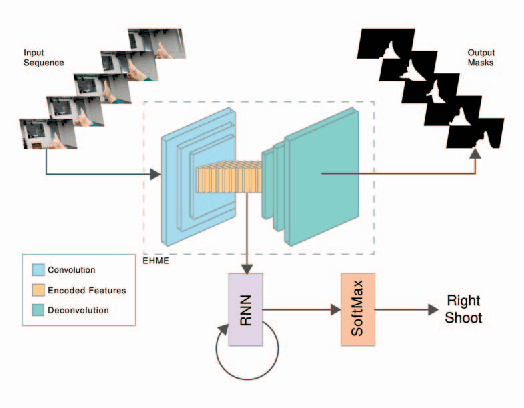
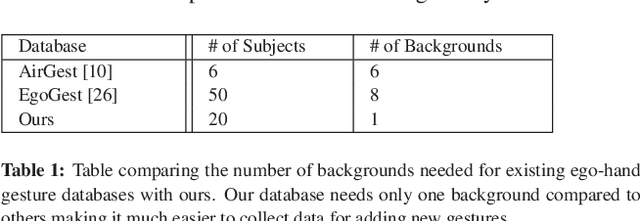

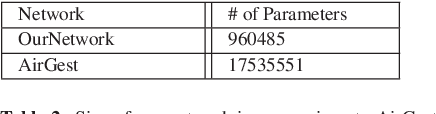
Natural interaction with virtual objects in AR/VR environments makes for a smooth user experience. Gestures are a natural extension from real world to augmented space to achieve these interactions. Finding discriminating spatio-temporal features relevant to gestures and hands in ego-view is the primary challenge for recognising egocentric gestures. In this work we propose a data driven end-to-end deep learning approach to address the problem of egocentric gesture recognition, which combines an ego-hand encoder network to find ego-hand features, and a recurrent neural network to discern temporally discriminating features. Since deep learning networks are data intensive, we propose a novel data augmentation technique using green screen capture to alleviate the problem of ground truth annotation. In addition we publish a dataset of 10 gestures performed in a natural fashion in front of a green screen for training and the same 10 gestures performed in different natural scenes without green screen for validation. We also present the results of our network's performance in comparison to the state-of-the-art using the AirGest dataset
SalNet360: Saliency Maps for omni-directional images with CNN
May 10, 2018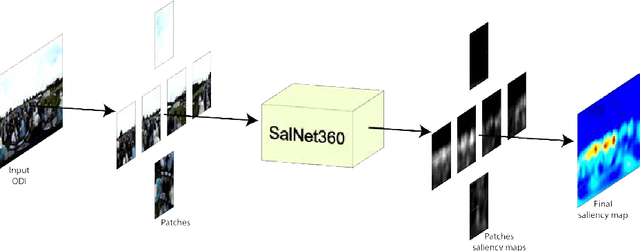
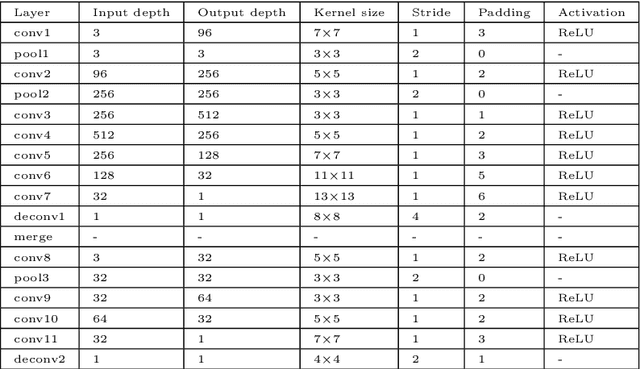


The prediction of Visual Attention data from any kind of media is of valuable use to content creators and used to efficiently drive encoding algorithms. With the current trend in the Virtual Reality (VR) field, adapting known techniques to this new kind of media is starting to gain momentum. In this paper, we present an architectural extension to any Convolutional Neural Network (CNN) to fine-tune traditional 2D saliency prediction to Omnidirectional Images (ODIs) in an end-to-end manner. We show that each step in the proposed pipeline works towards making the generated saliency map more accurate with respect to ground truth data.