 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointformer: Single-Frame Lifting Transformer with Error Prediction and Refinement for 3D Human Pose Estimation
Aug 07, 2022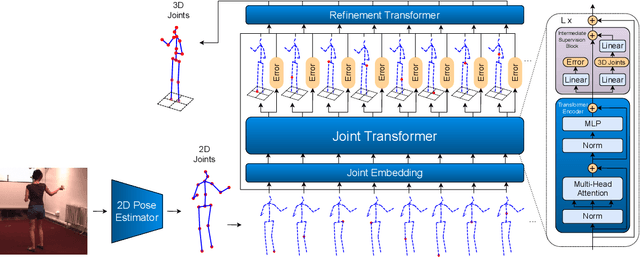
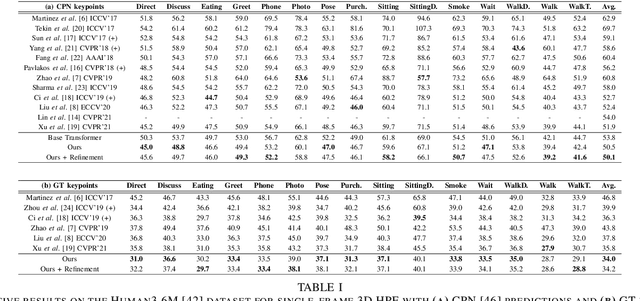
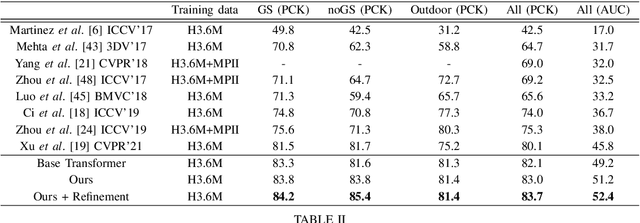
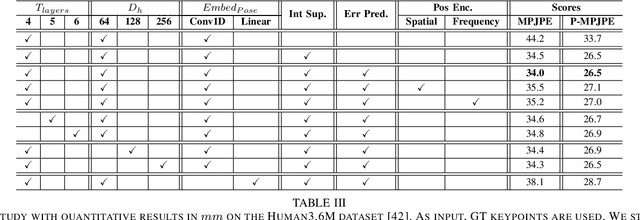
Monocular 3D human pose estimation technologies have the potential to greatly increase the availability of human movement data. The best-performing models for single-image 2D-3D lifting use graph convolutional networks (GCNs) that typically require some manual input to define the relationships between different body joints. We propose a novel transformer-based approach that uses the more generalised self-attention mechanism to learn these relationships within a sequence of tokens representing joints. We find that the use of intermediate supervision, as well as residual connections between the stacked encoders benefits performance. We also suggest that using error prediction as part of a multi-task learning framework improves performance by allowing the network to compensate for its confidence level. We perform extensive ablation studies to show that each of our contributions increases performance. Furthermore, we show that our approach outperforms the recent state of the art for single-frame 3D human pose estimation by a large margin. Our code and trained models are made publicly available on Github.
Frequency Domain Loss Function for Deep Exposure Correction of Dark Images
May 21, 2021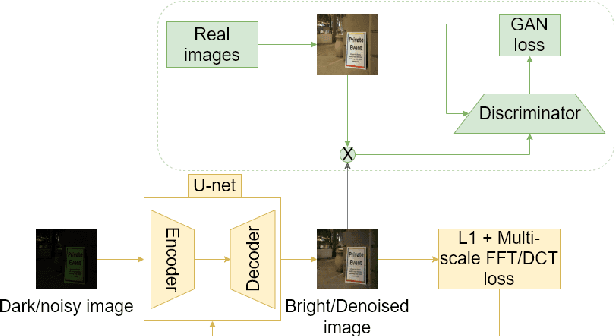
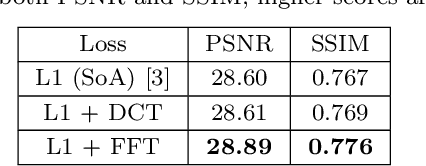
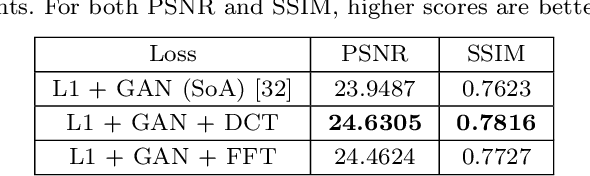

We address the problem of exposure correction of dark, blurry and noisy images captured in low-light conditions in the wild. Classical image-denoising filters work well in the frequency space but are constrained by several factors such as the correct choice of thresholds, frequency estimates etc. On the other hand, traditional deep networks are trained end-to-end in the RGB space by formulating this task as an image-translation problem. However, that is done without any explicit constraints on the inherent noise of the dark images and thus produce noisy and blurry outputs. To this end we propose a DCT/FFT based multi-scale loss function, which when combined with traditional losses, trains a network to translate the important features for visually pleasing output. Our loss function is end-to-end differentiable, scale-agnostic, and generic; i.e., it can be applied to both RAW and JPEG images in most existing frameworks without additional overhead. Using this loss function, we report significant improvements over the state-of-the-art using quantitative metrics and subjective tests.
Foreground color prediction through inverse compositing
Mar 24, 2021
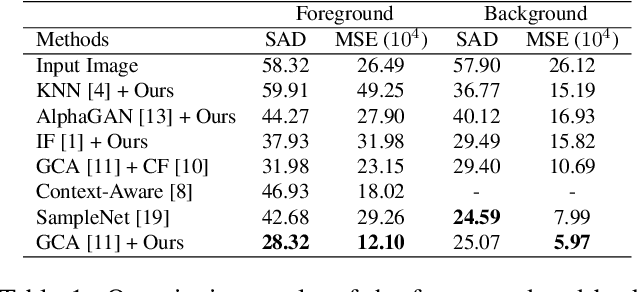


In natural image matting, the goal is to estimate the opacity of the foreground object in the image. This opacity controls the way the foreground and background is blended in transparent regions. In recent years, advances in deep learning have led to many natural image matting algorithms that have achieved outstanding performance in a fully automatic manner. However, most of these algorithms only predict the alpha matte from the image, which is not sufficient to create high-quality compositions. Further, it is not possible to manually interact with these algorithms in any way except by directly changing their input or output. We propose a novel recurrent neural network that can be used as a post-processing method to recover the foreground and background colors of an image, given an initial alpha estimation. Our method outperforms the state-of-the-art in color estimation for natural image matting and show that the recurrent nature of our method allows users to easily change candidate solutions that lead to superior color estimations.
STaDA: Style Transfer as Data Augmentation
Sep 03, 2019
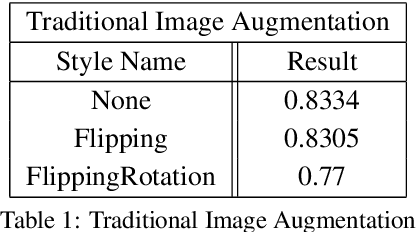

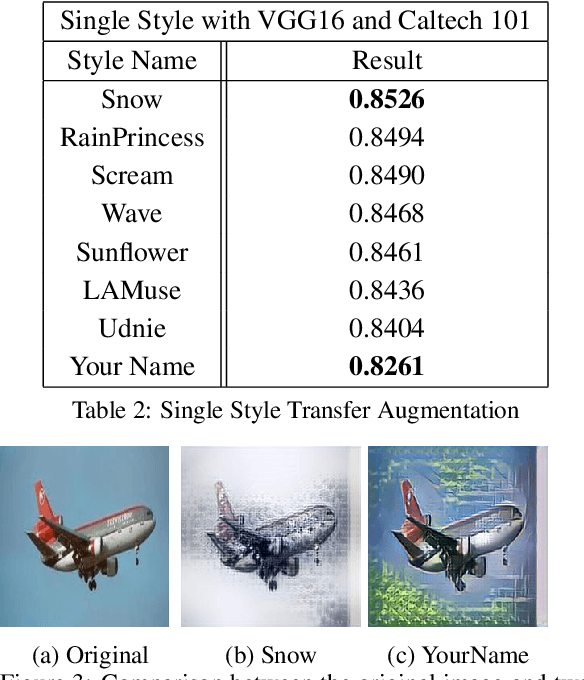
The success of training deep Convolutional Neural Networks (CNNs) heavily depends on a significant amount of labelled data. Recent research has found that neural style transfer algorithms can apply the artistic style of one image to another image without changing the latter's high-level semantic content, which makes it feasible to employ neural style transfer as a data augmentation method to add more variation to the training dataset. The contribution of this paper is a thorough evaluation of the effectiveness of the neural style transfer as a data augmentation method for image classification tasks. We explore the state-of-the-art neural style transfer algorithms and apply them as a data augmentation method on Caltech 101 and Caltech 256 dataset, where we found around 2% improvement from 83% to 85% of the image classification accuracy with VGG16, compared with traditional data augmentation strategies. We also combine this new method with conventional data augmentation approaches to further improve the performance of image classification. This work shows the potential of neural style transfer in computer vision field, such as helping us to reduce the difficulty of collecting sufficient labelled data and improve the performance of generic image-based deep learning algorithms.
AlphaGAN: Generative adversarial networks for natural image matting
Jul 26, 2018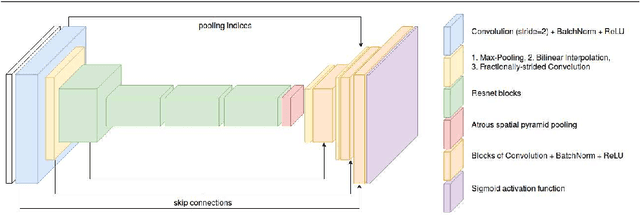

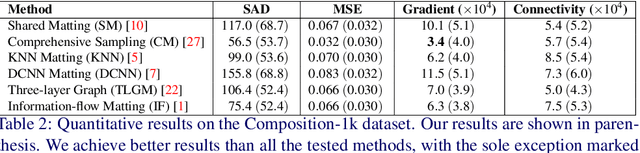

We present the first generative adversarial network (GAN) for natural image matting. Our novel generator network is trained to predict visually appealing alphas with the addition of the adversarial loss from the discriminator that is trained to classify well-composited images. Further, we improve existing encoder-decoder architectures to better deal with the spatial localization issues inherited in convolutional neural networks (CNN) by using dilated convolutions to capture global context information without downscaling feature maps and losing spatial information. We present state-of-the-art results on the alphamatting online benchmark for the gradient error and give comparable results in others. Our method is particularly well suited for fine structures like hair, which is of great importance in practical matting applications, e.g. in film/TV production.
SalNet360: Saliency Maps for omni-directional images with CNN
May 10, 2018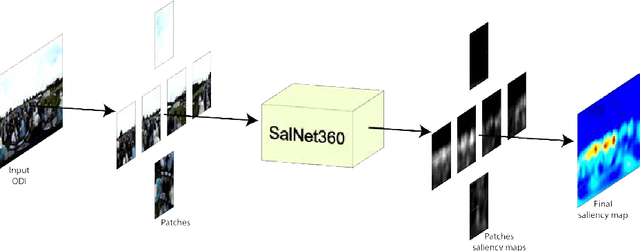
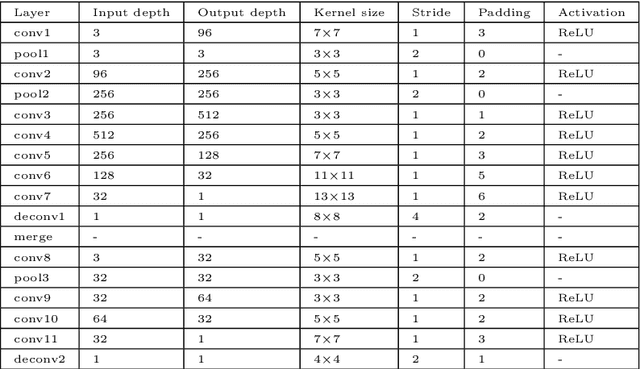


The prediction of Visual Attention data from any kind of media is of valuable use to content creators and used to efficiently drive encoding algorithms. With the current trend in the Virtual Reality (VR) field, adapting known techniques to this new kind of media is starting to gain momentum. In this paper, we present an architectural extension to any Convolutional Neural Network (CNN) to fine-tune traditional 2D saliency prediction to Omnidirectional Images (ODIs) in an end-to-end manner. We show that each step in the proposed pipeline works towards making the generated saliency map more accurate with respect to ground truth data.